这是一个硬件定义+testbench的例子:
//你的硬件顶层
import spinal.core._
class TopLevel extends Component {
...
}
//你的测试顶层
import spinal.sim._
import spinal.core.sim._
object DutTests {
def main(args: Array[String]): Unit = {
SimConfig.withWave.compile(new TopLevel).doSim{ dut =>
//仿真代码
}
}
}
SimConfig`会返回默认的仿真配置实例, 通过该实例能调用各种函数对仿真进行配置:
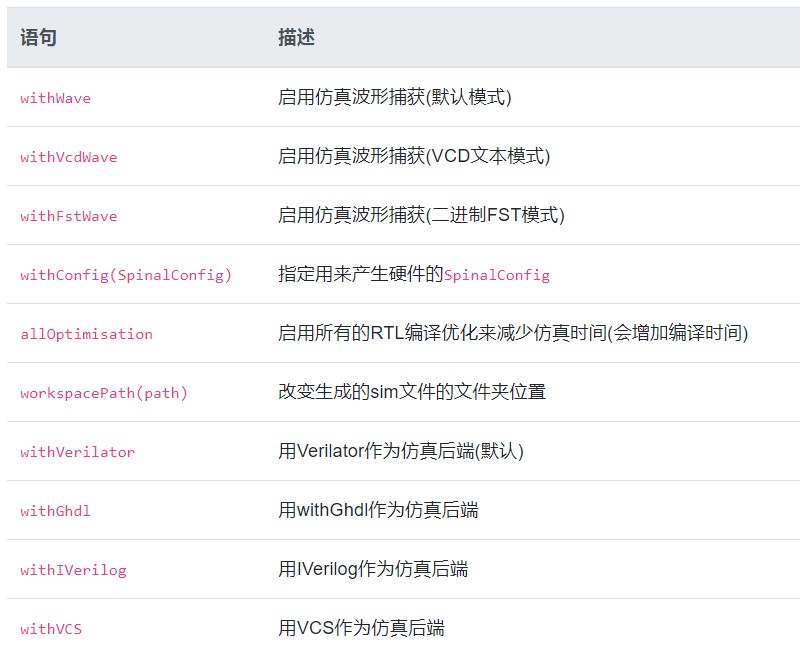
之后你可以调用compile(rtl)函数对硬件编译并为仿真器做准备。这个函数会返回SimCompiled实例。在这个SimCompiled实例中你可以用以下函数运行你的仿真:

注意默认情况下, 仿真文件会被替换成simWorkspace/xxx文件夹。你可以通过设置SPINALSIM_WROKSPACE环境变量重写simWorkspace的位置。
val compiled = SimConfig.withWave.compile(new Dut)
compiled.doSim("testA") { dut =>
//仿真代码
}
compiled.doSim("testB") { dut =>
//仿真代码
}
在仿真的任何一个时刻你都可以调用simSuccess或simFailure来终止它。
如果仿真太大, 很可能会产生仿真失败, 例如因为testbench在等待从未发生的条件的判断。为此, 调用SimTimeout(maxDuration)其中maxDuration所仿真应该会发生失败的时间(以仿真时间为单位)。
例如, 在1000个时钟周期后终止仿真:
val period = 10
dut.clockDomain.forkStimulus(period)
SimTimeout(1000 * period)
每个顶层的接口信号都可以通过Scala读写:
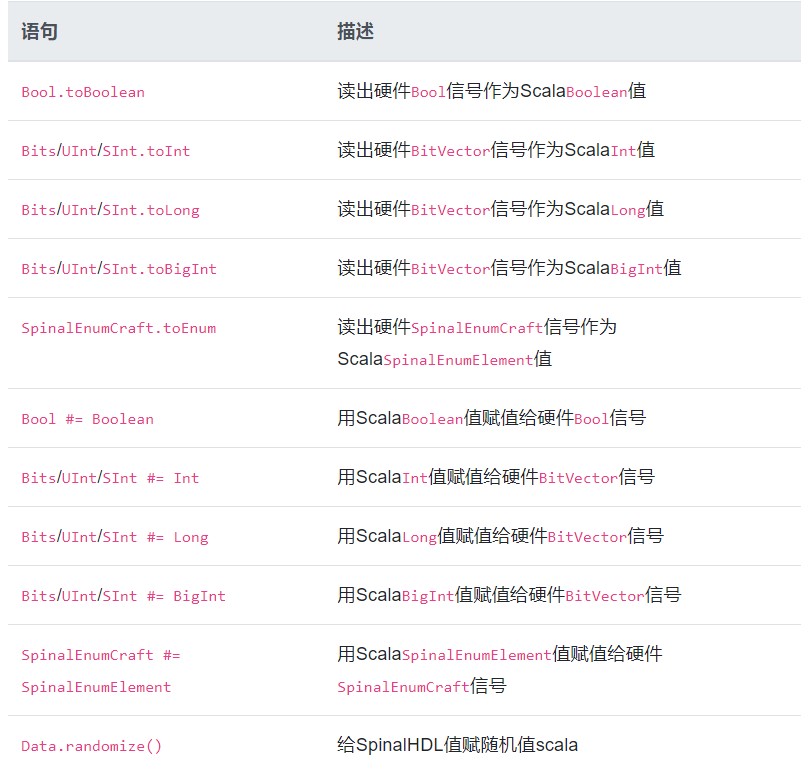
dut.io.a #= 42
dut.io.a #= 42l
dut.io.a #= BigInt("101010", 2)
dut.io.a #= BigInt("0123456789ABCDEF", 16)
println(dut.io.b.toInt)
为了访问在模块层次内部的信号, 你应该先把信号设置成simPublic。
你可以直接在硬件描述中增加simPublic标签:
object SimAccessSubSignal {
import spinal.core.sim._
class TopLevel extends Component {
val counter = Reg(UInt(8 bits)) init(0) simPublic() //这里给counter寄存器增加simPublic标签让其可被访问
counter := counter + 1
}
def main(args: Array[String]) {
SimConfig.compile(new TopLevel).doSim{dut =>
dut.clockDomain.forkStimulus(10)
for(i <- 0 to 3) {
dut.clockDomain.waitSampling()
println(dut.counter.toInt)
}
}
}
}
或者你可以在完成对顶层例化后, 在仿真时增加标签
object SimAccessSubSignal {
import spinal.core.sim._
class TopLevel extends Component {
val counter = Reg(UInt(8 bits)) init(0)
counter := counter + 1
}
def main(args: Array[String]) {
SimConfig.compile {
val dut = new TopLevel
dut.counter.simPublic()
dut
}.doSim{dut =>
dut.clockDomain.forkStimulus(10)
for(i <- 0 to 3) {
dut.clockDomain.waitSampling()
println(dut.counter.toInt)
}
}
}
}
以下是ClockDomain激励函数的列表:

以下是可用于等待时钟域中给定事件的ClockDomain实用程序列表:
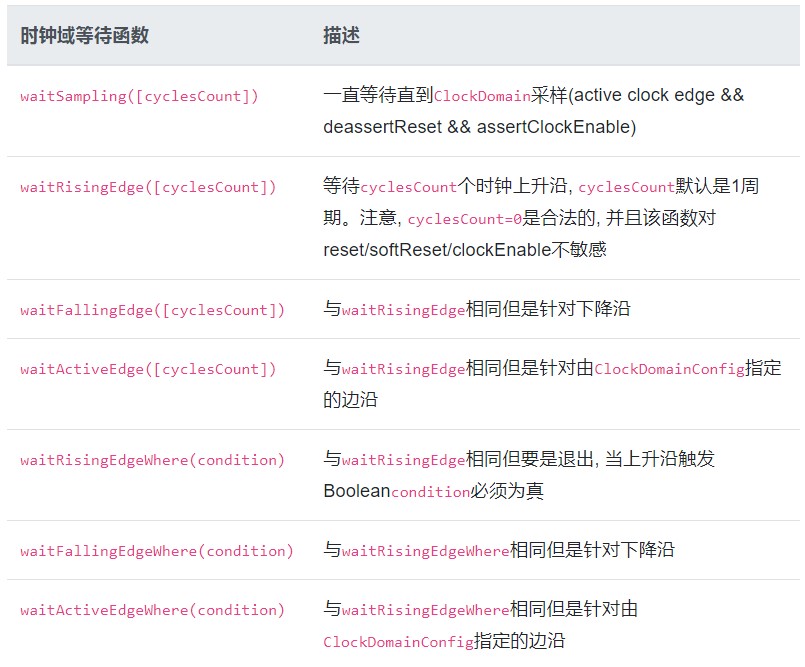
注意:所有的等待API的功能只能从线程内部调用, 不能从传回调用。
以下是可以用于传回时钟域中给定事件的ClockDomain实用程序列表:

你可以如下所示访存顶层的默认ClockDomain:
//线程分叉以产生复位的例子, 并且之后每5个单位时间翻转一次时钟。
//dut.clockDomain参考在模块例化期间产生的隐含的时钟域
fork {
dut.clockDomain.assertReset()
dut.clockDomain.fallingEdge()
sleep(10)
while(true) {
dut.clockDomain.clockToggle()
sleep(5)
}
}
备注:你也可以直接分化一个标准reset/clock进程:
dut.clockDomain.forkStimulus(period = 10)
下例所如何等待时钟上升沿的例子:
dut.clockDomain.waitRisingEdge()
如果你顶层定义了一些时钟并且复位输入没有直接集成到ClockDomain中, 你可以直接在testbench中定义他们对应的ClockDomain:
//在testbench中
ClockDomain(dut.io.coreClk, dut.io.coreReset).forkStimulus(10)
在SpinalSim中, 你可以用多线程写testbench, 这种方式比较像SystemVerilog, 也有点像VHDL/Verilog process/always块。这允许你写并行人物并用流式API控制仿真时间。
//建立新线程
val myNewThread = fork {
// New simulation thread body
}
//一直等待`myNewThread`直到完成执行
myNewThread.join()
//睡眠1000个单位时间
sleep(1000)
//在继续进行之前一直等待直到dut.io.a大于42
waitUntil(dut.io.a > 42)
也有一些函数帮助你避免线程的使用, 但是仍会允许你控制仿真时间流。
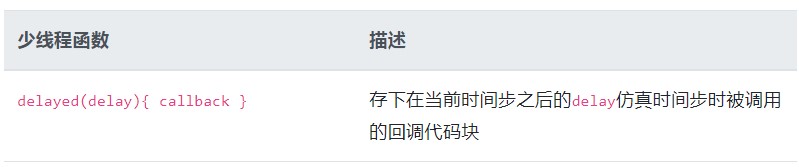
相比于用一般仿真线程+睡眠, delayed函数的优势: |
|---|
性能(没有上下文切换)
存储空间的利用(没有本地JVM线程存储空间的收集)
一些与ClockDomain相关的其他少线程函数都记录在"Callback API"模块中, 其他与delta-cycle相关的处理过程记录在"Sensitive API"中。
你可以寄存每个仿真中的delta-cycle回调函数:
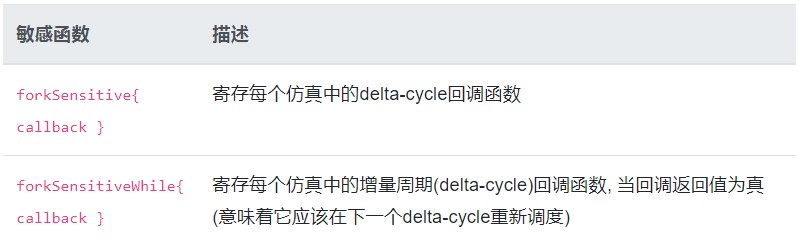
这一章解释了仿真引擎的内部构造。
仿真引擎通过在顶层Verilator C++仿真模型中应用以下仿真环来模仿事件驱动的仿真器(像VHDL/Verilog):
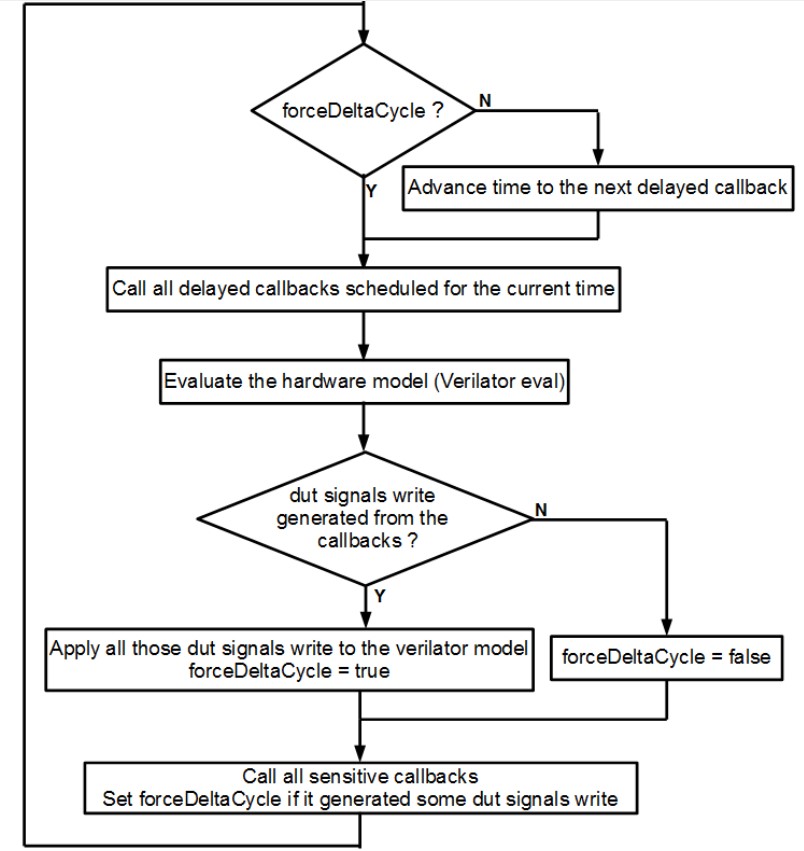
在底层, 仿真引擎管理如下原语:
敏感回调 , 允许用户在每个仿真增量周期调用函数;
延时回调 , 允许用户在未来仿真时间调用函数;
仿真线程 , 允许用户描述并行进程;
指令缓存 , 允许用户一直延时对DUT的写访问直到当前增量周期;
关于这些原语有一些使用的操作:
敏感回调可以像时钟上升沿一样, 当给定条件发生唤醒仿真线程;
延时回调可以用来调度激励, 例如在给定时间, 或者时钟翻转后取消对复位信号断言;
上述二者均可以用来恢复仿真线程;
仿真线程可以用来产生激励并检查DUT的输出值;
指令缓存的目的主要是避免DUT和testbench之间的并发事件。
该例使用组合逻辑创建了能处理一些简单算术运算的三操作数Component`:
testbench执行100次下述步骤:
在0..255的范围内随机初始化a, b和c;
给DUT的a, b, c输入激励;
等1个仿真时间步(让输入信号传播)
检查输出是否正确。
import spinal.sim._
import spinal.core._
import spinal.core.sim._
import scala.util.Random
object SimAsynchronousExample {
class Dut extends Component {
val io = new Bundle {
val a, b, c = in UInt (8 bits)
val result = out UInt (8 bits)
}
io.result := io.a + io.b - io.c
}
def main(args: Array[String]): Unit = {
SimConfig.withWave.compile(new Dut).doSim{ dut =>
var idx = 0
while(idx < 100){
val a, b, c = Random.nextInt(256)
dut.io.a #= a
dut.io.b #= b
dut.io.c #= c
sleep(1) //休眠1个时间步
assert(dut.io.result.toInt == ((a + b - c) & 0xFF))
idx += 1
}
}
}
}
该例创建了为跨时钟域设计的StreamFifoCC, 用了3个仿真线程。
线程用来处理:
管理两个时钟;
把数据推入FIFO;
把数据移出FIFO。
输入随机数推入FIFO。
FIFO推出线程检查DUT的输出和参考模型是否匹配(原始的scala.collection.mutable.Queue实例)。
import spinal.sim._
import spinal.core._
import spinal.core.sim._
import scala.collection.mutable.Queue
object SimStreamFifoCCExample {
def main(args: Array[String]): Unit = {
// Compile the Component for the simulator.
val compiled = SimConfig.withWave.allOptimisation.compile(
rtl = new StreamFifoCC(
dataType = Bits(32 bits),
depth = 32,
pushClock = ClockDomain.external("clkA"),
popClock = ClockDomain.external("clkB",withReset = false)
)
)
// Run the simulation.
compiled.doSimUntilVoid{dut =>
val queueModel = mutable.Queue[Long]()
// Fork a thread to manage the clock domains signals
val clocksThread = fork {
// Clear the clock domains' signals, to be sure the simulation captures their first edges.
dut.pushClock.fallingEdge()
dut.popClock.fallingEdge()
dut.pushClock.deassertReset()
sleep(0)
// Do the resets.
dut.pushClock.assertReset()
sleep(10)
dut.pushClock.deassertReset()
sleep(1)
// Forever, randomly toggle one of the clocks.
// This will create asynchronous clocks without fixed frequencies.
while(true) {
if(Random.nextBoolean()) {
dut.pushClock.clockToggle()
} else {
dut.popClock.clockToggle()
}
sleep(1)
}
}
// Push data randomly, and fill the queueModel with pushed transactions.
val pushThread = fork {
while(true) {
dut.io.push.valid.randomize()
dut.io.push.payload.randomize()
dut.pushClock.waitSampling()
if(dut.io.push.valid.toBoolean && dut.io.push.ready.toBoolean) {
queueModel.enqueue(dut.io.push.payload.toLong)
}
}
}
// Pop data randomly, and check that it match with the queueModel.
val popThread = fork {
for(i <- 0 until 100000) {
dut.io.pop.ready.randomize()
dut.popClock.waitSampling()
if(dut.io.pop.valid.toBoolean && dut.io.pop.ready.toBoolean) {
assert(dut.io.pop.payload.toLong == queueModel.dequeue())
}
}
simSuccess()
}
}
}
}
该例创建了StreamFifo, 并产生3个仿真线程。不像Dual clock fifo, 本FIFO不需要复杂的时钟管理。
三个仿真线程用来处理:
管理时钟/复位
数据推入FIFO
数据推出FIFO
输入随机数推入FIFO
FIFO推出线程检查DUT的输出和参考模型是否匹配(原始的scala.collection.mutable.Queue实例)。
import spinal.sim._
import spinal.core._
import spinal.core.sim._
import scala.collection.mutable.Queue
object SimStreamFifoExample {
def main(args: Array[String]): Unit = {
// Compile the Component for the simulator.
val compiled = SimConfig.withWave.allOptimisation.compile(
rtl = new StreamFifo(
dataType = Bits(32 bits),
depth = 32
)
)
// Run the simulation.
compiled.doSimUntilVoid{dut =>
val queueModel = mutable.Queue[Long]()
dut.clockDomain.forkStimulus(period = 10)
SimTimeout(1000000*10)
// Push data randomly, and fill the queueModel with pushed transactions.
val pushThread = fork {
dut.io.push.valid #= false
while(true) {
dut.io.push.valid.randomize()
dut.io.push.payload.randomize()
dut.clockDomain.waitSampling()
if(dut.io.push.valid.toBoolean && dut.io.push.ready.toBoolean) {
queueModel.enqueue(dut.io.push.payload.toLong)
}
}
}
// Pop data randomly, and check that it match with the queueModel.
val popThread = fork {
dut.io.pop.ready #= true
for(i <- 0 until 100000) {
dut.io.pop.ready.randomize()
dut.clockDomain.waitSampling()
if(dut.io.pop.valid.toBoolean && dut.io.pop.ready.toBoolean) {
assert(dut.io.pop.payload.toLong == queueModel.dequeue())
}
}
simSuccess()
}
}
}
}
本例用时序逻辑搭建了三操作数的简单算术运算Component。
在0..255的范围内随机初始化a, b和c;
给DUT的a, b, c输入激励;
一直等待直到DUT信号再次被仿真采样;
检查输出是否正确。
该例和Asynchronous adder例子的主要区别是本Component需要用forkStimulus产生时钟信号, 因为它内部用的是时序逻辑。
import spinal.sim._
import spinal.core._
import spinal.core.sim._
import scala.util.Random
object SimSynchronousExample {
class Dut extends Component {
val io = new Bundle {
val a, b, c = in UInt (8 bits)
val result = out UInt (8 bits)
}
io.result := RegNext(io.a + io.b - io.c) init(0)
}
def main(args: Array[String]): Unit = {
SimConfig.withWave.compile(new Dut).doSim{ dut =>
dut.clockDomain.forkStimulus(period = 10)
var resultModel = 0
for(idx <- 0 until 100){
dut.io.a #= Random.nextInt(256)
dut.io.b #= Random.nextInt(256)
dut.io.c #= Random.nextInt(256)
dut.clockDomain.waitSampling()
assert(dut.io.result.toInt == resultModel)
resultModel = (dut.io.a.toInt + dut.io.b.toInt - dut.io.c.toInt) & 0xFF
}
}
}
}
// Fork a simulation process which will analyze the uartPin and print transmitted bytes into the simulation terminal.
fork {
// Wait until the design sets the uartPin to true (wait for the reset effect).
waitUntil(uartPin.toBoolean == true)
while(true) {
waitUntil(uartPin.toBoolean == false)
sleep(baudPeriod/2)
assert(uartPin.toBoolean == false)
sleep(baudPeriod)
var buffer = 0
for(bitId <- 0 to 7) {
if(uartPin.toBoolean)
buffer |= 1 << bitId
sleep(baudPeriod)
}
assert(uartPin.toBoolean == true)
print(buffer.toChar)
}
}
// Fork a simulation process which will get chars typed into the simulation terminal and transmit them on the simulation uartPin.
fork{
uartPin #= true
while(true) {
// System.in is the java equivalent of the C's stdin.
if(System.in.available() != 0) {
val buffer = System.in.read()
uartPin #= false
sleep(baudPeriod)
for(bitId <- 0 to 7) {
uartPin #= ((buffer >> bitId) & 1) != 0
sleep(baudPeriod)
}
uartPin #= true
sleep(baudPeriod)
} else {
sleep(baudPeriod * 10) // Sleep a little while to avoid polling System.in too often.
}
}
}
原作者:Joshua_FPGA
更多回帖

