一般架构有 1~3 级 Cache。
作者在之后的 Lecture 中集中讨论了 L1 Cache。
CPU 在进行 load/store 时,会使用虚拟地址,需要在访问时转换成物理地址。对于 L1 Cache,一般有两种实施方式:
如果使用 virtual tag 的话,需要格外注意虚拟地址别名问题 (virtual aliasing)。比如一个多进程程序,访问同一块物理内存 (共享内存或者动态库的代码段) ,这时会有两个不同的 virtual address page 指向同一个 physical address page。这种问题想要正确处理会比较困难。
TLB (translation lookaside buffer) 一般有 10 ~ 几百项 (高端架构 TLB 也会分级,一般 L1 TLB 有 10 ~ 几十项,L2 TLB 可能有上百项) 。由于 TLB 对性能影响很大,一般都是单周期访问。
关于 TLB 内容的管理,有两种方案:
Cache 的组织结构一般如下图:
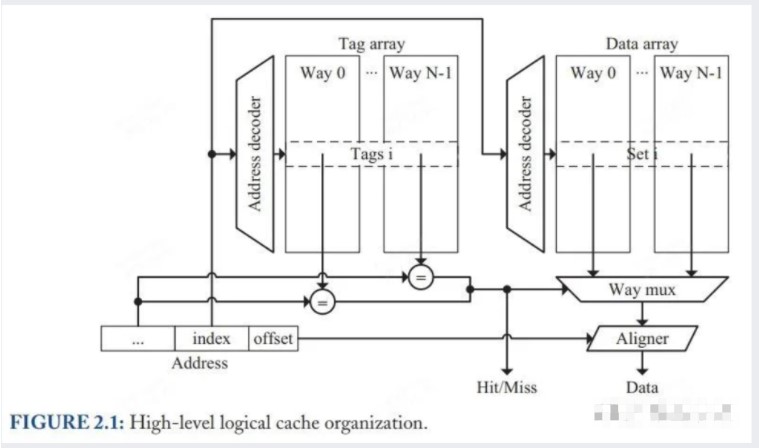
△ Figure 2.1: Cache 组织架构示意图_(其实也是单周期并行访问 Cache 的实现)_
Cache 主要由两块组成:tag array 和 data array
data array 由多个 set 构成 (一些教材将 set 中文译为「组」) ,每个 set 由多个 block 组成 (block 等价于 cache line,缓存行) 。一个 set 中有多少个 block 被称为相联度,有时也叫做 N-way,代表相联度为 N。
tag array 的 set 数量和相联度跟 data array 一致。tag array 里除了保存 tag 外,还保存了一些控制位,如 valid、dirty 等。
其实 Figure 2.1 也描述了单周期 Cache 的一种实现方式。index 被取出后同时用于计算对应的 set。对于 data array,直接从对应 set 中把所有 block 拿出来给 way mux;对于 tag array,将对应 set 的 N-way tag 全部拿出来跟 virtual address 的 tag 进行比对,如果没有一项比对上,则生成 miss 信号,从下级 cache 取数据;如果比对上,则用比对上的 i-th way 从 data array 中拿对应的 block。最后再根据 offset 取到想要的 word (这一步被称为 data alignment) 。
上述过程中 Tag 的访问以及 Data 的访问是同时发生的。
由于 L1 Cache 对性能影响很大,因此对于频率高的架构,需要对上述过程进行流水化。
下图展示了 Figure 2.1 流水化后的实现方案:
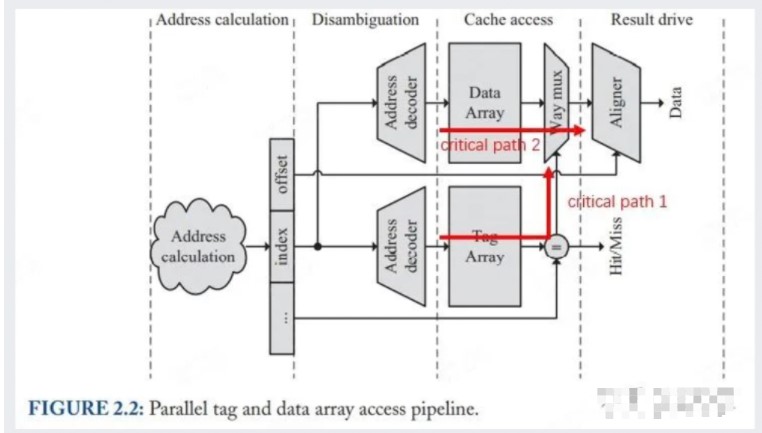
Figure 2.2: Figure 2.1 的流水化版,红色箭头为关键路径
图中有两条关键路径 (已用红色箭头标出) ,一条是从 tag 中找到对应 set 取出 N 个数据,并对每一个 tag 进行比对,将控制位送到 way mux 上;另一条是从 data array 里取出 N 个 block,送入 way mux,并根据 tag 给来的控制位选出结果。
使用 Tag & Data 并行访问,单周期内需要完成 Tag Array 选中与匹配、Data Array 选中与取出、稳定 way mux 通道控制、数据通过 way mux 选出并稳定输出。这些操作在单周期内进行会造成时序的紧张,有可能会拖慢 Cache 的频率。
另一种实现方案是先访问 tag,然后再访问 data,两者是串行工作的。其工作流程示意图如下:
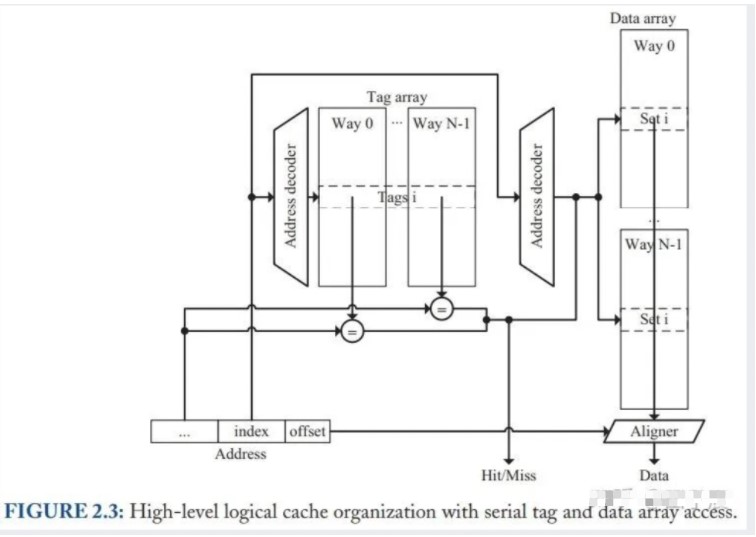
这种 Cache 拿到 index 解码对应好 set 后,首先访问并比对 tag array,如果 cache hit,再从 data array 中取出对应的 way,将数据送去 Aligner 获取所需的 word。
相比于上一种并行实现,串行实现的好处在于:
Tag & Data 并行访问的流水化方案如下:
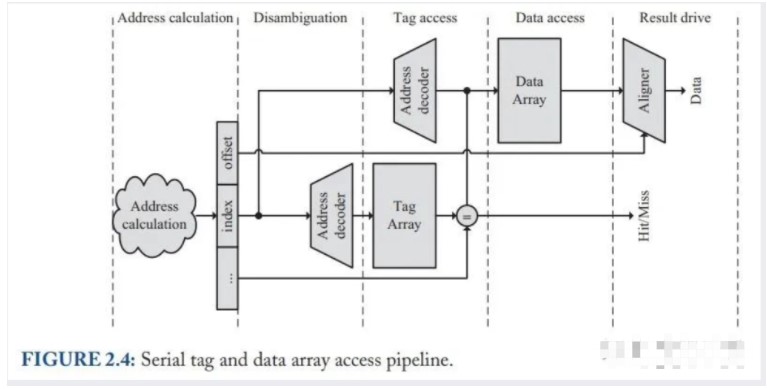
△ Figure 2.4: Figure 2.3 的流水化方案
可以看到,相对于 Figure 2.2,Figure 2.4 方案的好处在于:不再需要 way mux,Tag array 的关键路径 (Figure 2.2 的关键路径 1) 缩短了,而 Data array 的关键路径也消失了。整个方案的时序不再像并行访问那么紧张,因此 Cache 的频率可以得以提高,Cache 吞吐量可以做的更大。另外,串行访问的功耗更低。
但是串行访问也有一个缺点,由于需要先匹配 Tag,后取 Data,流水线相比并行访问会多一个周期,延迟更高。
相联度越低,不论是并行方案还是串行方案,对于 tag 匹配和 data 选通来说,时序都会更优,因此能达到更高的频率。但是更低的相联度也就意味着更多的 cache 冲突,会导致 cache miss rate 升高。因此相联度需要进行权衡。
阻塞式 cache (blocking cache) :流水线访问 cache 发生 miss 时,流水线发生阻塞,直到数据从下级访存系统中获取到后再恢复执行。阻塞式 cache 的好处是简单,但是一旦发生阻塞,会严重拖慢流水线性能。
非阻塞式 cache (non-blocking cache,作者用的是 lockup-free cache) :流水线访问 cache 发生 miss 时,流水线能够继续执行与访存无依赖关系的其他指令(包括访存指令)。非阻塞式 cache 要与某种依赖 tracking 机制组合使用(计分板或者 tomasulo)。在目前的乱序执行核心中,Cache 都是非阻塞的。
为了实现这一机制,需要有空间来暂存 miss 的访存请求,等待数据从下级访存系统返回后写入 cache 并向流水线返回。实现这一机制的空间被称作 MSHRs(miss status/information holding registers)。另外,从下级访存系统返回的数据会被先缓存到 input stack(或称 fill buffer)中,再写入 data array。
对于非阻塞 cache,miss 可以被分为三类:
MSHRs 有三种实现方式:
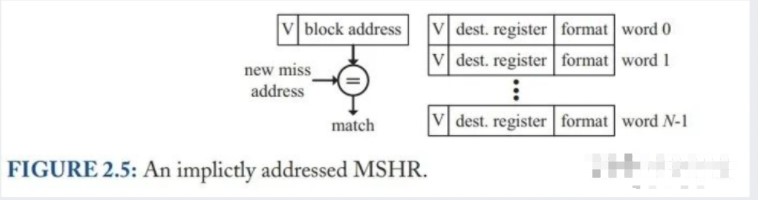
△ Figure 2.5: Implicitly Addressed MSHRs_(图中是一个 MSHR 项所包含的内容)_
隐式寻址 MSHRs(Implicitly Addressed MSHRs)结构如上图所示。需要先说明的是,图中的一大堆东西其实是一项 MSHR 所包含的内容。
一项 MSHR 包括有效位、block address(cache line address)、以及一个长度为 N 的 data array。N 对应于一个 cache line 中的 word 数量,即 data array 中的每一项对应于 cache line 中的一个 word。data array 会存下每个 word 的访存信息,包括数据从下级访存返回后应该写到哪个寄存器,是多少 bit 的访存指令,zero-extend 还是 sign-extend 等。
当发生 primary miss 时,会找到一个空的 MSHR,设置有效位和 block address,并把访存信息设置到对应的 data array 项。后续发生 secondary miss 时,会根据 block address 找到该 MSHR 项,再次设置访存信息。等到下级访存系统回数后,根据 data array 记录的访存信息给寄存器返回数据。
上文提到的隐式寻址 MSHRs 虽然实现简单,但存在一个问题:当 secondary miss 的 word 跟 primary miss 相同时,由于 data array 和 word 一一对应,因此 secondary miss 会触发一次结构冒险,导致流水线停顿。
显式寻址 MSHRs(Explicitly Addressed MSHRs)放弃了一一对应的关系,而是在每一个访存信息里加了 block offset 的信息,如下图所示。这样即使是同一个 word 的两次 miss,也可以存在不同的 data array 项中,避免了隐式寻址 MSHRs 的问题。
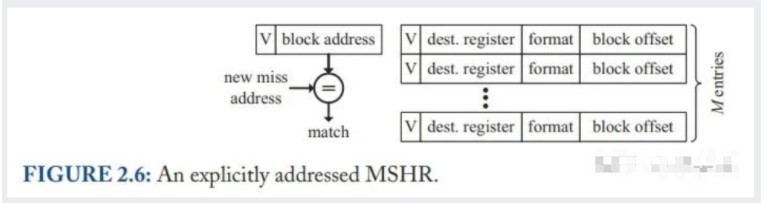
(作者没有给出 M 的选取规则,个人理解这里是有 tradeoff 的:M 越大越能缓存更多的 miss,但是面积和时序都考验更大,且 MSHRs 的项数会受限;相反虽然 MSHRs 的项数会变多,但是一旦程序频繁的访问同一个 cache line 且都触发 miss 的话,依然会造成阻塞)
不管是隐式还是显式寻址 MSHRs,都会额外占用面积,在面积受限时 MSHRs 的项数会受限。一种解决方法是把 MSHRs 的信息直接存在 Cache 里面,Cache 的 tag array 依旧存 tag,Cache 的 data array 在数据回来之前用来存储 MSHRs 的访存信息,再额外添加一个 transient 位用来标记这一个 cache line 正在从下级访存取数据。这种 In-Cache MSHRs 既可以用隐式寻址,也可以显式寻址。
这种方式的好处是可以有很多的 MSHRs 项,但缺点是实现比较复杂。
为了保证高带宽,目前的高端处理器都能每个周期处理两条访存指令。实现 dual-ported Cache 的方法主要有 4 种:
这种设计思路将 Cache 种的所有的控制和数据通路都复制了一份,包括 address decoders、multiplexors、tag comparators、aligners 等。tag array 和 data array 不复制。这种方法虽然能够保证实现真正的双发射,但是会导致 Cache 访问时间急剧增加,进而导致频率无法提高。因此商用芯片几乎不采用这一方案。
这种方案在 True Multiported Cache 的基础上,把 data array 和 tag array 也复制了一份。这种方式降低了访存的复杂度,能够在增加带宽的同时不会引入额外的访存时间开销。但是这种方案很浪费面积,而且因为需要同步两个 array 的数据而造成复杂度升高。有些设计也会仅复制 data array。
这种方案是使用时分复用的方式,在一个周期内处理两条访存指令,从而在一个端口上实现双端口的功能。这种设计有两个弊端:一是很难扩展到更高的端口数,二是 data array 很难在高频率下一个周期输出多个数据,因此限制了频率的升高。
这种方案的核心思想是:将 cache 分为多个 bank,每一个 bank 有一个 cache port(包括 address decoder、tag comparators、aligners 等),负责处理当前 bank 的访存请求。跟 True Multiported Cache 不同的是,这种方式不需要 cache bank 有多端口,因此访问时间没有升高,且不像 Array Replication 一样需要复制 tag array 和 data,因此面积也不会明显增大。这种方案的示意图如下:
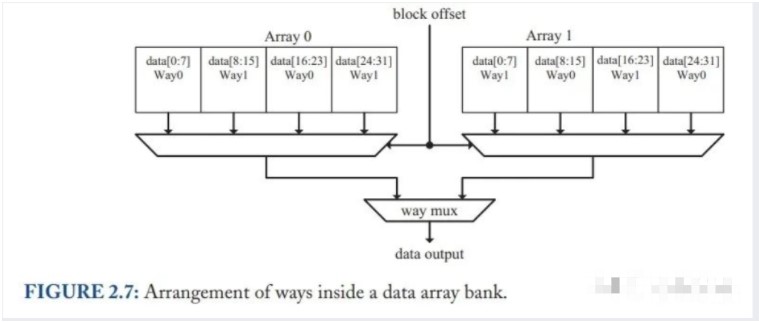
△ Figure 2.7: Multibanking 方案示意图
Multibanking 是目前最常用的 dual-port Cache 实现方案。不过这种方案需要注意 bank conflict 的问题。如果两条访存指令访问了同一个 bank,则不能在一个周期内处理。解决这个问题一方面可以靠硬件对地址做映射(一般都是连续地址 interleave),另一方面也可以靠软件尽可能不同时访问同一个 bank。
另外要强调一点的就是地址对齐的问题,如果地址对齐到 cache line 的话,访存指令只需要访问一个 bank,因此只要另一条访存指令没有 bank conflict,就可以多发射一条访存指令。如果访存指令不对齐的话,就会被拆成两条对齐的指令,分给两个 bank 去访存。虽然延迟不变,但是带宽会减半。(最新的设计貌似已经克服了这个问题,不知道是怎么解决的)
ICache 一般比 DCache 更简单一些,这主要是由于 ICache 的访存 pattern 不同于 DCache 导致的
由于程序访问一般是顺序的,一个周期访问一个 cache line 基本上能够满足指令发射的需要,因此使用单端口即可
ICache 使用阻塞式 Cache。非阻塞 Cache 的好处在于访存指令 miss 后,可以执行后续的指令。但 ICache Miss 的话根本就没有后续的指令可以用(它本来就是取指令的地方),必须等到 miss 回数后再继续,因此使用非阻塞 Cache 没有意义。
相比于串行访问,ICache 更适合使用 Tag & Data 并行访问,原因在于当分支预测错误时,并行访问能够更快的重启流水线。不过并行访问的时序和功耗会更紧张,需要仔细权衡
关于相联度,ICache 由于访问一般比较连续,因此不需要太高的相联度,不过也要根据实际情况仔细权衡。
原作者:田子宸
更多回帖

