多核处理器分类方式有很多种,其中一种比较常见的是按照存储器组织方式分类。
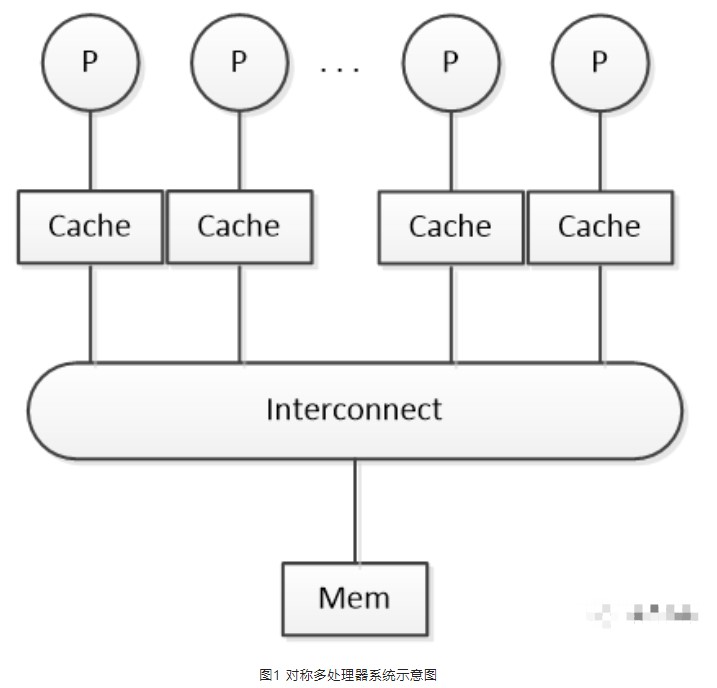
第一类就是一致存储器访问(Uniform Memory Access,简称UMA)多处理器,所谓的“一致”是指所有处理器访问存储器的延迟都是一样的。这种体系结构的处理器有时候也会被叫做对称多处理器(Symmetric Mul
ti-Processor,简称SMP)。这里的“对称”,是说所有的处理器没有主次或从属关系。所有处理器可以平等的访问存储器,共享相同的物理内存,每个处理器访问内存所需时间是相同的(延迟相差不大,并不是绝对的相同)。SMP系统可以采用多种连接方式,最常用的还是总线方式。SMP系统的最大特点就是处理器之间共享系统资源,但正是因为共享,每个处理器必须通过相同的内存总线访问相同的内存资源,随着处理器数量的增加,内存访问冲突将迅速增加,最终会造成使处理器的性能大大降低。所以,SMP的扩展性有限。
第二类是非一致存储器访问(Non- Uniform Memory Access,简称NUMA)。NUMA系统的特点是,整个系统由多个节点构成,每个节点有自己的处理器(一个或多个)和独立的存储器,节点间通过互联模块连接。这样,处理器既可以访问本地的存储器,也可以访问其它节点内的存储器(也可以称为远端存储器),但是,处理器访问本地内存的速度将远高于访问远端内存的速度。看得出来,NUMA很好地解决了UMA的扩展性问题。但是由于NUMA系统的不对称访问特点,开发应用程序时需要尽量减少不同处理器节点之间的信息交互,因为程序编写者必须了解数据在内存中的局部性。需要指出的是,NUMA的系统性能并不会随着处理器数量的增长而线性增长。
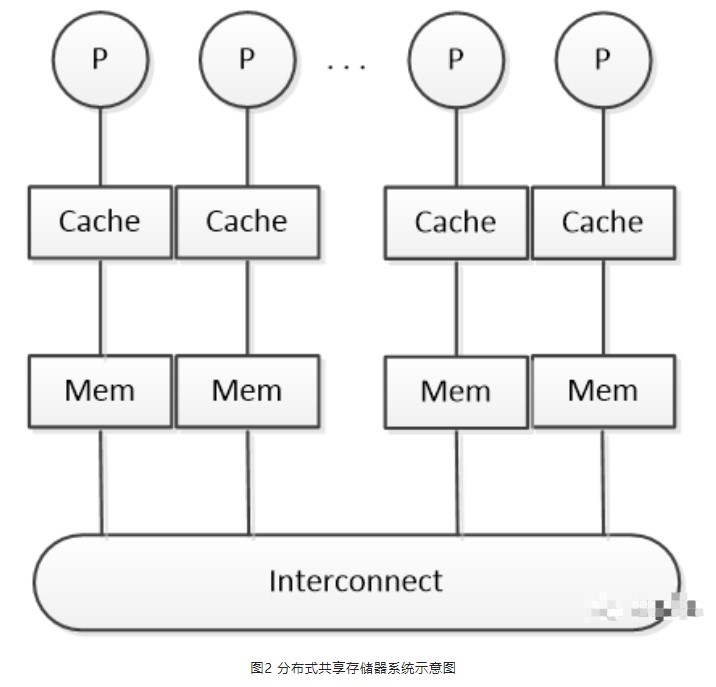
分布式共享存储器(Distributed Shared Memory,DSM)是NUMA中的一种。在DSM结构中,互连网络将多个分布的存储器连接起来。当系统中的处理器数量变多时,互连网络也会增大本地存储器访问的时延。但是因为访问本地内存的时间变长,通过互连网络访问远端内存的额外时延并不会造成总时延的急剧增加。
如果NUMA系统中的节点之间需要保持缓存一致性,那么这个系统又可以称为CC-NUMA(Cache Coherent NUMA)。对于CC-NUMA中的并行处理任务,操作系统的调度器要格外小心。
在实际应用中,不同层次存储可以用不同的组织方式互连。比如,一个多处理器系统可能包含多个多核处理器,在每个多核处理器芯片内部的L2和L3可以采用共享缓存或SMP方式,而在多个芯片间采用DSM结构互连。
原作者:老秦谈芯


