ARM Linux 内核在自解压并处理完设备树的更新后,会将程序计数器 pc 设置为 stext() 的物理地址,这里是内核的代码段。这段代码可以在 arch/arm/kernel/head.S 中找到。

通过查看 ARM 体系结构的链接脚本 arch/arm/kernel/vmlinux.lds.S,可以知道这个宏会将目标代码放置在内核最开始的位置。
这个位置对应的物理地址为:16MB 的倍数 + TEXT_OFFSET (32KB)。例如,你可能会在 0x10008000 之类的地址处找到 stext(),后面的示例会基于这个假设的地址进行分析。
head.S 包含了一些针对不同的旧 ARM 平台的特殊处理代码,这使得我们很难从抓住程序的主干。ATAG 和设备树的标准是后来才出现的,所以这些特殊代码多年来变得越来越复杂。
要理解后续的内容,你需要对分页虚拟内存 (paged virtual memory) 有基本的了解。如果维基百科过于简洁,请参阅 Hennesy & Patterson 的书:Computer Architecture: A Quan
titative Approach。这里默认你是了解一点 ARM 汇编语言和 Linux 内核基础知识的。
虚拟内存的划分
首先,让我们先弄清楚内核是在虚拟内存中哪个地址开始执行的。内核的虚拟内存基地址 (kernel RAM base) 由 PAGE_OFFSET 决定,你可以对其进行配置。从名字上理解 PAGE_OFFSET:first page of kernel RAM 在虚拟内存中的偏移位置。
你可以从 4 种内存划分方案中选择其中 1 个,这让我想起了快餐店的餐牌。目前在 arch/arm/Kconfig 中是这样定义的:
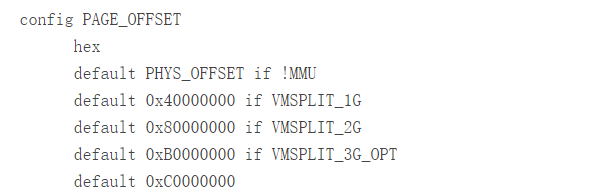
注意,如果芯片没有 MMU (例如在 ARM Cortex-R 类设备或旧的 ARM7 芯片上运行时),内核将在物理和虚拟内存之间创建 1:1 映射。然后页表将仅用于填充缓存并且地址不会被重写。这种情况下,PAGE_OFFSET 的典型值就是 0x00000000。没有使用虚拟内存的 Linux 内核被称为“uClinux”,在合并在主线内核之前,多年来它都是 Linux 内核的一个分支。
在使用 Linux 或任何 POSIX 类型的系统时,不使用虚拟内存被认为是一种怪异的行为。因此,从现在开始,我们只考虑使用虚拟内存的情况。
PAGE_OFFSET,即 virtual memory split symbol,在其上方的地址处创建一个虚拟内存空间,供内核驻留。内核将其所有代码、状态和数据结构 (包括虚拟到物理内存转换表,即 page table) 都保存在这一区域的虚拟内存中:
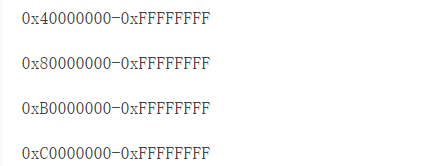
这 4 种不同大小的内核空间里,0xC0000000-0xFFFFFFFF 是迄今为止最常见的。这种方式下,内核有 1GB 的地址空间可供使用。
内核下方的虚拟内存空间,从 0x00000000-PAGE_OFFSET-1,即通常地址 0x00000000-0xBFFFFFFF (3 GB) 用于用户空间代码。这意味着您可以乐观地为程序提供比可用物理内存更多的虚拟内存空间,这种做法被称为 overcommit。每次启动一个新的用户空间进程时,它都认为它有 3 GB 的内存可以使用!overcommit 一直是 Unix 系统自 1970 年代诞生以来的一个特征。
为什么有四种不同的划分方式?
答案很明显:ARM 大量用于嵌入式系统,这些系统可以是用户空间密集型 (例如普通平板电脑或
手机,甚至台式计算机) 或内核空间密集型 (例如路由器)。大多数系统都是用户空间密集型,或物理内存太小以至于拆分并不重要,因此最常见方式是 PAGE_OFFSET = 0xC0000000。

关于这些插图的注意事项:当我说内存“高于”某物时,我的意思是图片中的较低位置,沿着箭头,朝向更高的地址。我知道有些人认为这是不合逻辑的,并将数字倒置,顶部为 0xFFFFFFFF,但这是我个人的偏好,也是大多数硬件手册中使用的约定。
当你有足够大的内存和并且应用场景是内核密集型,例如大容量的内存 (例如 4GB 内存) 路由器或 NAS 的话,如果你希望内核能够将其中一些内存用于 page cache 和 network cache 以提升系统的性能,可以选择更大的内核空间,例如在极端情况下:PAGE_OFFSET = 0x40000000。
内核空间的映射会一直存在,即便是内核正在执行用户空间代码时也是如此。这个想法是这样的,通过保持内核空间永久映射,从用户空间到内核空间的上下文切换会变得非常快:当用户空间进程想要向内核询问某些东西时,不需要替换任何页表。只需发出一个软中断 (software trap) 来切换到特权模式 (supervisor mode) 并执行内核代码,无需改动虚拟内存相关的设置。
不同用户空间的进程之间的上下文切换也变得更快:你只需要替换页表的较低部分。内核空间的映射通常很简单,它映射的是预先确定的物理内存块并且是线性映射,甚至存储在一个特殊的地方:translation lookaside buffer,从而能更快地进入内核空间。内核空间的地址总是存在的,并且总是线性映射,永远不会产生 page fault。
目前我们是在哪里运行?
我们继续查看 arch/arm/kernel/head.S 里的 stext()。
下一步是处理我们目前正在内存的某个未知位置运行的事实。内核可以被加载到任何地址(只要它是一个合理的偶数地址)并直接执行,所以现在我们需要处理它。由于内核代码不是位置无关的,它在编译后被链接器链接到某个地址处执行,而我们还不知道是哪个地址。
内核首先检查一些特殊功能,如虚拟化扩展和 LPAE(大型物理地址扩展),然后做了下面这件事:

.long . 是在链接的时候就分配给 lable 2 的地址,也就是说我们可以通过 label 2 获得其链接地址,这个地址属于内核空间,一般在 0xC0000000 之上的某个位置。
之后是常量 PAGE_OFFSET,它大概率是 0xC0000000。
其余的几行汇编代码是在通过 lable 2 的运行地址和链接地址相减的方式来推算出物理内存的起始偏移(PHYS_OFFSET),将其保存在 r8 中,假设其值为0x10000000。
旧的 ARM 内核有一个名为 PLAT_PHYS_OFFSET 的符号,它包含这个偏移量,这是在编译时时指定的。我们现在不再这样做了,正如我们前面看到的那样,动态地计算出来。如果您使用的操作系统不如 Linux 那么成熟,您会发现开发人员通常就会在编译时指定,使事情变得简单些:物理内存的起始偏移量是一个常数。Linux 发展成现在这样,是因为我们需要在各种内存布局上处理单个内核映像的启动。
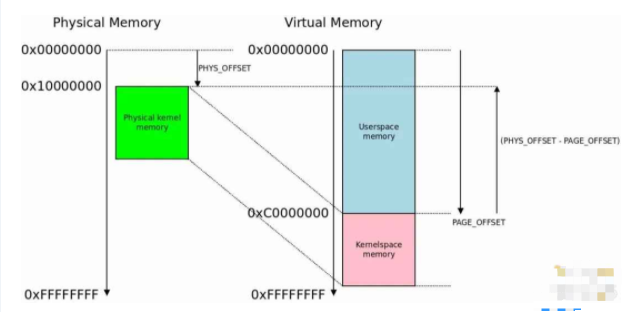
物理内存到虚拟内存映射。
一些关于 PHYS_OFFSET 的规定:它需要遵守一些基本的对齐要求。当我们要确定第一个物理内存块的位置时,是通过执行 PHYS = pc & 0xF8000000 来确定的,这意味着物理内存必须是 128 MB 对齐。例如,如果它从 0x00000000 开始,那就太好了。
当内核是以 XIP “execute in place” 的方式执行时,就需要有有一些特殊的考虑,但我们把这种情况放在一边,这是另一个奇怪的地方,甚至比不使用虚拟内存更不常见。
请注意另一件事:你可能尝试加载未压缩的内核并启动它,然后发现内核对放置它的位置特别挑剔。此时,你最好将其加载到 0x00008000 或 0x10008000 之类的物理地址(假设你的 TEXT_OFFSET 是 0x8000 )。如果你使用压缩内核,则可以避免此问题,因为解压缩器会将内核解压缩到合适的位置(通常为 0x00008000)并为你解决此问题。这正是人们觉得压缩内核正常工作是一种常态的另一个原因。
给 P2V 打补丁 (Patching Physical to Virtual)
现在我们有了运行时应处于的虚拟内存地址和实际执行时的物理内存地址之间的偏移量 (PHYS_OFFSET - PAGE_OFFSET),接下来我们第一个要处理的东西就是 CONFIG_ARM_PATCH_PHYS_VIRT。
创建此符号是因为内核开发者想实现这样的功能:无需重新编译,也能让同一个内核在不同内存配置的系统上启动。内核被编译成在某个虚拟地址处执行,例如 0xC0000000,但是仍然可以被加载到物理内存 0x10000000 处,或者在 0x40000000 处,或其他某个地址处去执行。
内核中的大多数符号是不需要我们额外关心的:它们运行时的地址就是其链接时的虚拟地址上,即 0xC0000000 之后的那些地址。但是现在我们不是在编写用户空间的程序,事情没那么容易。我们必须知道我们正在执行的物理内存,因为我们是内核,这意味着我们需要在页表中设置物理到虚拟的映射,并定期更新这些页表。
内核不知道自己将在物理内存中的哪个位置运行,而我们也不能依赖任何廉价的技巧,例如编译时常量,这是作弊,那会创建难以维护的充满幻数的代码。
为了在物理地址和虚拟地址之间转换,内核有两个函数:__virt_to_phys() 和 __phys_to_virt() 用于互相转换内核地址 (不会用于非内核地址)。
这种转换在内存空间中是线性的,可以通过简单的加法或减法来实现。这就是我们正要做的事情,我们给它起了个名字叫 “P2V runtime patching”。该方案由 Nicolas Pitre、Eric Miao 和 Russell King 在 2011 年发明,2013 年 Santosh Shilimkar 将该方案扩展到适用于 LPAE 系统,特别是 TI Keystone SoC。

__pv_stub() 是用汇编实现加减操作的宏。LPAE 对超过 32 位地址的支持使此代码变得更加复杂,但总体思路是相同的。
每当在内核中调用 __virt_to_phys() 或 __phys_to_virt() 时,它都会被替换为来自 arch/arm/include/asm/memory.h 的一段内联汇编代码,然后链接器会换到名为 .pv_table 的 section,然后向该 section 里添加一个条目,条目的内容是一个指针,它指向前面提到的汇编代码。这意味着 .pv_table section 其实就是一个表,里面的每一个条目都是一个指针,每个指针都指向内核调用了 __virt_to_phys() 或 __phys_to_virt() 处的汇编代码。
在启动过程中,我们将遍历这个表,取出每个指针,检查它指向的每条指令,然后用 (PHYS_OFFSET - PAGE_OFFSET) 去给这些指令打补丁。
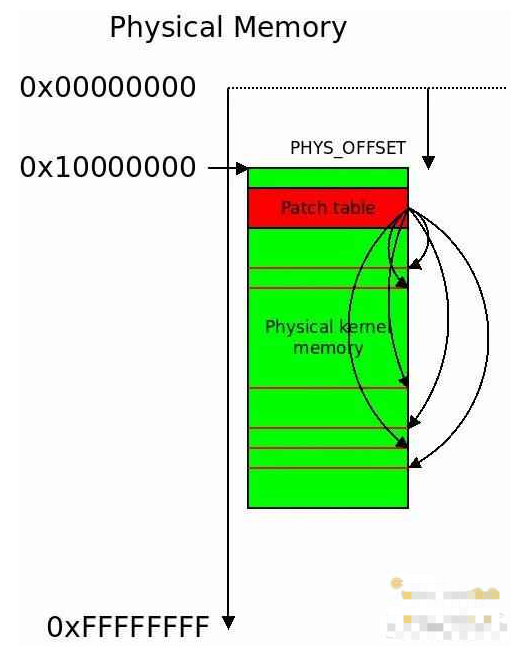
在早期启动过程中,每个调用了执行物理内存到虚拟内存的转换汇编宏的地方都需要打补丁
相关的代码:

核心内容就是,先计算出 pv_table 的起始地址和结束地址,然后遍历该表,对每一个条目都调用 __fixup_a_pv_table,给该条目所指向的汇编代码打补丁。
为什么我们进行这么复杂的操作,而不仅仅是将偏移量存储在变量中?
这是出于效率原因:它位于内核的热数据路径上。更新页表和交叉引用物理到虚拟内核内存的操作对性能的要求是及其苛刻的,所有使用内核虚拟内存的场景,无论是 block layer 或 network layer 的操作,还是用户到内核空间的转换,原则上任何通过内核的数据会在某个时间点调用这些函数。所以,他们必须很快。



