Arm拥有跨所有处理器的计算IP。而且,无论您要在GPU,CPU还是NPU上进行ML推理,都可以在一个通用框架下使用它们:Arm NN。
Arm NN是适用于CPU,GPU和NPU的开源推理引擎。它弥合了现有NN框架与底层IP之间的鸿沟。Arm NN建立在Arm Compute库(ACL)之上。其中包含一组高度优化的低级功能,以加快对Arm Cortex-A系列CPU处理器和Arm Mali系列GPU的推断。对于GPU,ACL使用OpenCL作为其计算API。(请参见图1)。
OpenCL内存模型紧密映射到GPU架构。因此,可以实现优化,从而显着减少对全局内存的访问,这将在下一部分中看到。这意味着更快的卷积计算和更低的功耗。这与CNN推论特别相关,卷积约占总操作量的90%。
ACL是一个开源项目,与其他替代产品相比,Arm一直在努力优化以提供卓越的性能。为了从Arm NN中获得最大收益,重要的是要知道它提供的选项来提高推理性能。作为开发人员,您会寻找可以压缩的每一毫秒,尤其是在需要实现实时推理时。让我们看一下Arm NN中可用的优化选项之一,并通过一些实际示例评估它可能产生的影响。
OpenCL tuner
ACL实现了所谓的本地工作组大小(LWS)调谐器。这个想法是要提高L1和L2级别的缓存利用率,并尽可能减少对全局内存的访问。
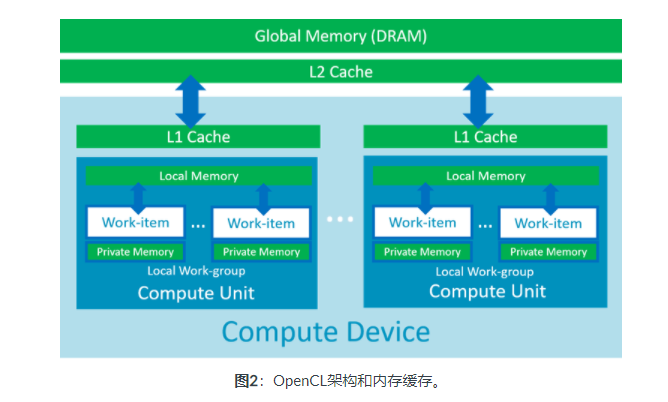
图2显示了OpenCL体系结构的基本表示。计算设备可以是GPU,CPU或加速器。在计算设备内部,我们有几个计算单元(GPU内核,CPU内核等)。它们每个都有自己的L1内存缓存,并且可以并行执行N个线程,称为工作项。每个线程执行对应于OpenCL内核的同一段代码,其中线程ID用于访问不同的内存位置。
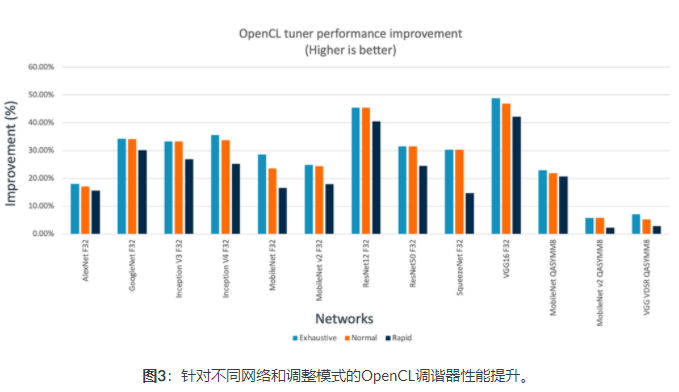
为了提高L1内存缓存的利用率,我们希望同一个工作组的线程访问连续的内存地址(内存合并)。为了优化L2缓存利用率,我们希望计算单元重用相同的内存块。为了对L1和L2内存缓存实现这些优化,ACL实施了本地工作组大小(LWS)调谐器,以找到用于每种OpenCL内核类型的最佳配置。对LWS调谐器的推理性能的影响可能很大。对于不同的网络,此值介于1.12和1.8之间,如下面的图片所示,这是三种不同的CL Tuner模式。
当调谐器第一次被引入时,它使用了一种暴力方法。它简单地测试了LWS的所有可能值,并选择了提供最小执行时间的值。对于深度网络,此过程可能需要几分钟。在ACL19.05版本中,调谐器进行了优化,现在我们可以从三个级别的调优中进行选择:“穷举”、“快速”和“正常”。这些级别在调优性能和调优时间之间提供了不同的权衡。调整过程只进行一次,最佳配置保存在本地文件中。要访问此文件,Android应用程序需要拥有读写外部存储的权限。可以将该文件放入特定于应用程序的文件夹中。
以下摘录中显示了启用调谐器的代码片段。要启用调谐器,必须设置介于1和3之间的级别。此外,我们必须提供保存最佳配置的文件路径。一旦我们为GPU后端设置了调优选项,我们就可以使用它来创建运行时。第一次激活调谐器需要较长时间才能运行。
最后一步是从“选项”中删除在第一次运行后设置调优级别的行。一旦创建了文件,就不再需要此行。ARM NN只需要知道文件在哪里。保持这一行意味着每次都会启动调优过程,以找到内核的最佳配置,并降低每次执行的速度。
快速模式旨在提供最短的调谐时间,但没有实现良好的性能提升。但是,穷举可提供最佳性能,但具有最长的调优时间。正常级别在性能改进和调优时间之间提供了平衡。在各种网络上进行的一项研究表明,正常模式和快速模式足以实现显著的性能提升。
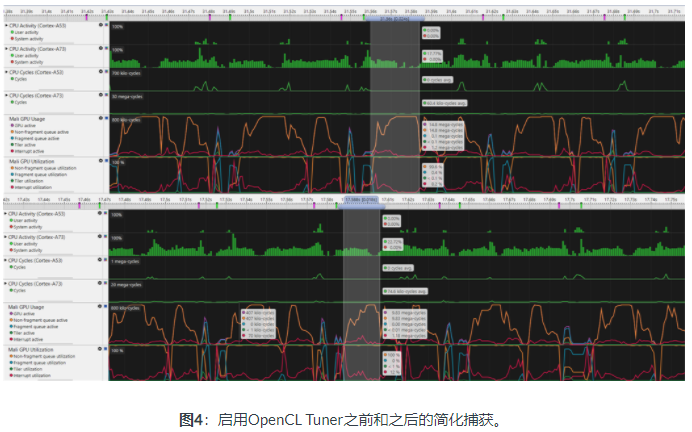
上图显示了启用OpenCL Tuner之前(上图)和启用OpenCL Tuner之后(下图)的流线型捕获。关注GPU使用率部分中的非碎片队列活动(橙色曲线),突出显示的间隔显示GPU上ML推理过程的开始和结束。请注意,启用调谐器后,与启用调谐器之前的推理间隔(24ms)相比,推断间隔(18ms)更短。这意味着推理性能提高了25%。根据硬件和网络类型的不同,改进程度会有所不同。图片中显示的截图对应于在Unity应用程序中的Marii-G72 MP12 GPU上运行的分段网络对来自智能手机的视频流的推断。
结论
GPU最初旨在通过在每个图形核心中并行运行数百个线程以进行顶点和片段处理来加速图形。现在,这种图形功能也广泛用于通用计算(GPGPU),尤其是用作将运算符实现为计算着色器的推理引擎的后端。GPU推理不仅具有优于CPU推理的性能,还具有其他优势。在移动CPU上执行深度神经网络推理会带来不必要的功耗增加成本,这会不利地影响电池寿命和热节流,从而导致计算速度降低。但是,哪个计算单元最好?答案是:这取决于工作量。
但是,例如,如果您的应用程序需要实时性能,例如,当使用CNN处理来自智能手机视频流的图像时,则GPU是首选。下一步是使OpenCL Tuner获得免费的性能提升,您将在任何实时应用程序中始终欣赏到它。