1 简介
在真正利用ARM NEON优化程序性能时,还有很多编程技巧和注意事项。本文将结合本人的一些开发经历,介绍NEON编程中的一些常见优化技巧,希望能对用户在NEON实际开发中有些借鉴意义。
2 NEON 优化技术
在利用NEON优化程序时,有下述几项比较通用的优化技巧。
2.1 降低数据依赖性
在ARM v7-A NEON指令通常需要3~9个指令周期,NEON指令比ARM指令需要更多周期数。因此,为了减少指令延时,最好避免将当前指令的目的寄存器当作下条指令的源寄存器。如下例所示:



: "memory", "cc", "q0", "q1", "q2", "q3", "q8", "q9", "q10", "q11","q12", "q13","q14", "q15");
return sse;
}


: "memory", "cc", "q0", "q1", "q2", "q3", "q8", "q9", "q10", "q11", "q12", "q13","q14", "q15");
return sse;
}
在NEON实现一中,我们把目的寄存器立刻当作源寄存器;在NEON实现二中,我们重新排布了指令,并给予目的寄存器尽量多的延时。经过测试实现二比实现一快30%。由此可见,降低数据依赖性对于提高程序性能有重要意义。一个好消息是编译器能自动调整NEON intrinsics以降低数据依赖性。这个利用NEON intrinsics的一个很大优势。
2.2 减少跳转
NEON指令集没有跳转指令,当需要跳转时,我们需要借助ARM指令。在ARM处理器中,分支预测技术被广泛使用。但是一旦分支预测失败,惩罚还是比较高的。因此我们最好尽量减少跳转指令的使用。其实,在有些情况下,我们可以用逻辑运算来代替跳转,如下例所示:


ARM NEON指令集提供了下列指令来帮助用户实现上述逻辑实现:
• VCEQ, VCGE, VCGT, VCLE, VCLT……
• VBIT, VBIF, VBSL……
减少跳转,不仅仅是在NEON中使用的技巧,是一个比较通用的问题。即使在C程序中,这个问题也是值得注意的。
2.3 其它技巧
在ARM NEON编程时,一种功能有时有多种实现方式,但是更少的指令不总是意味着更好的性能,要依据测试结果和profiling数据,具体问题具体分析。下面列出来我遇到的一些特殊情况。
2.3.1 浮点累加指令
通常情况下,我们会用VMLA/VMLS来代替VMUL + VADD/ VMUL + VSUB,这样使用较少的指令,完成更多的功能。但是与浮点VMUL相比,浮点VMLA/VMLS具有更长的指令延时,如果在指令延时中间不能插入其它计算的情况下,使用浮点VMUL + VADD/ VMUL + VSUB反而具有更好的性能。
一个真实例子就是Ne10库函数的浮点FIR函数。代码片段如下所示:
实现1:在两条VMLA指令之间,仅有VEXT指令。而根据指令延时表,VMLA需要9个周期。
实现2:对于qAcc0,依然存在指令延时。但是VADD/VMUL只需要5个周期。
下列代码中周期n粗略地表示了指令执行需要的周期数。与实现1相比,实现2节省了6个周期。性能测试也表明实现2具有更好的性能。


modules/dsp/NE10_fir.neon.s:line 195
指令延时请参考下表:
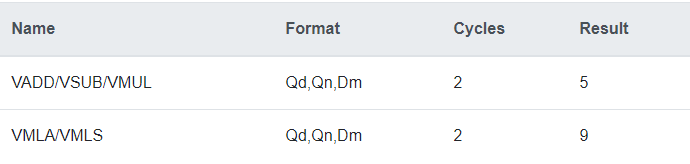
表格来源于Cortex™-A9 NEON™ Media Processing Engine Revision: r4p1 Technical Reference Manual: 3.4.8。表格中:
• Cycles:指令发射时间
• Result:指令执行时间
2.4 小结
总结起来,NEON的优化技巧主要有以下几点:
• 尽量利用指令执行延时,合理安排指令顺序
• 少用跳转
• 注意cache命中率


