
![]()
![]()
语音识别系统 嵌入式 TMS320VC5402
音乐语音识别系统的硬件
电路该如何去设计?
音乐语音识别系统的软件该如何去实现?
回帖(1)

2021-12-23 14:34:40
随着电子音乐的快速发展, 迫切需要一种更智能、更便捷的用户操作系统。自动音乐语音识别系统能够提供便利的人机交互,方便人们自己学习音乐知识, 将成为一种主要方法,也是一个发展的方向。目前, 实验室环境中自动语音识别系统已经取得了很好的效果, 但是应用于电子音乐方面的自动音乐语音识别却很少。当自动语音识别应用于电子音乐时, 必须对识别方法进行相应改进, 才能满足其对运算速度、内存资源等方面的要求。为了解决这个问题, 本文将结合音乐语音的特点,设计并实现嵌入式音乐语音识别系统。
1系统硬件电路设计系统
硬件电路设计的原理框图如图1所示,它主要由音乐语音信息采集部分、音乐语音处理DSP部分、程序数据存储器FLASH部分、数据存储器SRAM部分、键盘管理部分、音源芯片语音输出部分、以及电源部分组成。音乐语音信息采集部分主要由MCU GPL162001来完成,该芯片自带12bit ADC和72个I/O口,方便键盘管理,。音乐语音处理DSP部分选用了目前通用的TI公司的TMS320VC5402 16位微处理器,处理速度快,最快运行速度可达100MIPS,功耗低,是一款理想的DSP处理器。考虑到速度要求较快,DSP的晶振选用100MHZ的晶振。另外,由于音乐输出要求有专业的乐音效果,电路中选择了由中芯微公司提供的64和弦MIDI音频处理芯片。此外,TMS320VC5402片上没有FLASH且片内RAM只有16K,考虑到语音数据比较大,我们外扩了1M的FLASH芯片和64K的SRAM芯片。 DSP(TMS320VC5402) 是整个硬件系统的信号处理中心,完成音乐语音识别工作, 进行RAM及FLASH 存储芯片的数据管理与调度, 并向主控芯片 MCU 提供反馈信息。电源的工作电压为3.3V。
 图1 系统原理图
2系统的软件实现
和大部分语音识别系统一样,音乐语音识别系统本质也是一种模式识别系统。它的基本流程图如图2所示,主要包括语音信号预处理,端点检测,特征参数求取和语音识别等几个步骤。
图1 系统原理图
2系统的软件实现
和大部分语音识别系统一样,音乐语音识别系统本质也是一种模式识别系统。它的基本流程图如图2所示,主要包括语音信号预处理,端点检测,特征参数求取和语音识别等几个步骤。
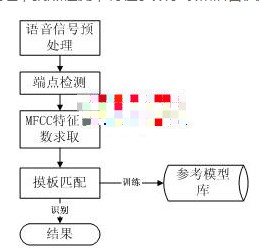 图2 系统识别算法流程图
2.1语音信号预处理
语音信号预处理主要是对语音信号进行前期的优化处理,方便后面的端点检测和语音识别,语音信号预处理主要包括分帧处理、预加重处理、加窗处理、滤波和消除毛刺处理等。
2.1.1语音信号的分帧
语音信号的特征是随着时间而变化的,只有在一段短的时间间隔中,语音信号才保持相对稳定一致的特征, 通常这段时间取5~50ms。在程序中取200个采样点,对于8k的采样频率,即相当于25ms。帧间重叠为100个采样点,亦即12.5ms。
2.1.2预加重
由于语音信号平均功率谱受声门激励和口鼻辐射影响,800HZ以上的高频信号按6DB/倍频跌落,所以求语音信号频谱时,频率越高相应成分越少,高频部分的频谱比低频部分难求,所以要进行预加重处理。在数字语音信号处理中,数字语音信号通常都通过一个低阶的系统(典型的是一个一阶的滤波器),即
图2 系统识别算法流程图
2.1语音信号预处理
语音信号预处理主要是对语音信号进行前期的优化处理,方便后面的端点检测和语音识别,语音信号预处理主要包括分帧处理、预加重处理、加窗处理、滤波和消除毛刺处理等。
2.1.1语音信号的分帧
语音信号的特征是随着时间而变化的,只有在一段短的时间间隔中,语音信号才保持相对稳定一致的特征, 通常这段时间取5~50ms。在程序中取200个采样点,对于8k的采样频率,即相当于25ms。帧间重叠为100个采样点,亦即12.5ms。
2.1.2预加重
由于语音信号平均功率谱受声门激励和口鼻辐射影响,800HZ以上的高频信号按6DB/倍频跌落,所以求语音信号频谱时,频率越高相应成分越少,高频部分的频谱比低频部分难求,所以要进行预加重处理。在数字语音信号处理中,数字语音信号通常都通过一个低阶的系统(典型的是一个一阶的滤波器),即
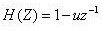 式中, 为预加重系数,通常 最为常用的取值是在0.95附近。由于本系统采用的是 =0.94
2.1.3加窗
对每一帧语音进行加窗实质是语音波形乘窗函数,为减少时间窗两端的坡度,使窗口边缘两端平滑过渡到零,减小语音帧的截断效应, 这里采用典型的应用在语音识别系统中加hamming窗。
2.1.4滤波、消除毛刺
由于语音信号包含很多噪声信号,这些噪声信号在时域中表现出高频随机、毛刺等信号,这些信号很可能影响识别的效果,所以,对信号进行带通滤波和消除毛刺处理能很好提高识别的精度。由于人声主要在60-1000HZ ,采用50-1000HZ的FIR带通滤波器对原信号进行滤波,即可获得良好的效果。 消除毛刺影响主要采用语音信号峰谷值检测的方法,把相邻两峰值之间很不明显的谷值和相邻两谷值之间很不明显的峰值去掉,对语音曲线中一些较小的毛刺进行曲线整形,消除那些明显的毛刺!
式中, 为预加重系数,通常 最为常用的取值是在0.95附近。由于本系统采用的是 =0.94
2.1.3加窗
对每一帧语音进行加窗实质是语音波形乘窗函数,为减少时间窗两端的坡度,使窗口边缘两端平滑过渡到零,减小语音帧的截断效应, 这里采用典型的应用在语音识别系统中加hamming窗。
2.1.4滤波、消除毛刺
由于语音信号包含很多噪声信号,这些噪声信号在时域中表现出高频随机、毛刺等信号,这些信号很可能影响识别的效果,所以,对信号进行带通滤波和消除毛刺处理能很好提高识别的精度。由于人声主要在60-1000HZ ,采用50-1000HZ的FIR带通滤波器对原信号进行滤波,即可获得良好的效果。 消除毛刺影响主要采用语音信号峰谷值检测的方法,把相邻两峰值之间很不明显的谷值和相邻两谷值之间很不明显的峰值去掉,对语音曲线中一些较小的毛刺进行曲线整形,消除那些明显的毛刺!
随着电子音乐的快速发展, 迫切需要一种更智能、更便捷的用户操作系统。自动音乐语音识别系统能够提供便利的人机交互,方便人们自己学习音乐知识, 将成为一种主要方法,也是一个发展的方向。目前, 实验室环境中自动语音识别系统已经取得了很好的效果, 但是应用于电子音乐方面的自动音乐语音识别却很少。当自动语音识别应用于电子音乐时, 必须对识别方法进行相应改进, 才能满足其对运算速度、内存资源等方面的要求。为了解决这个问题, 本文将结合音乐语音的特点,设计并实现嵌入式音乐语音识别系统。
1系统硬件电路设计系统
硬件电路设计的原理框图如图1所示,它主要由音乐语音信息采集部分、音乐语音处理DSP部分、程序数据存储器FLASH部分、数据存储器SRAM部分、键盘管理部分、音源芯片语音输出部分、以及电源部分组成。音乐语音信息采集部分主要由MCU GPL162001来完成,该芯片自带12bit ADC和72个I/O口,方便键盘管理,。音乐语音处理DSP部分选用了目前通用的TI公司的TMS320VC5402 16位微处理器,处理速度快,最快运行速度可达100MIPS,功耗低,是一款理想的DSP处理器。考虑到速度要求较快,DSP的晶振选用100MHZ的晶振。另外,由于音乐输出要求有专业的乐音效果,电路中选择了由中芯微公司提供的64和弦MIDI音频处理芯片。此外,TMS320VC5402片上没有FLASH且片内RAM只有16K,考虑到语音数据比较大,我们外扩了1M的FLASH芯片和64K的SRAM芯片。 DSP(TMS320VC5402) 是整个硬件系统的信号处理中心,完成音乐语音识别工作, 进行RAM及FLASH 存储芯片的数据管理与调度, 并向主控芯片 MCU 提供反馈信息。电源的工作电压为3.3V。
图1 系统原理图
2系统的软件实现
和大部分语音识别系统一样,音乐语音识别系统本质也是一种模式识别系统。它的基本流程图如图2所示,主要包括语音信号预处理,端点检测,特征参数求取和语音识别等几个步骤。
图2 系统识别算法流程图
2.1语音信号预处理
语音信号预处理主要是对语音信号进行前期的优化处理,方便后面的端点检测和语音识别,语音信号预处理主要包括分帧处理、预加重处理、加窗处理、滤波和消除毛刺处理等。
2.1.1语音信号的分帧
语音信号的特征是随着时间而变化的,只有在一段短的时间间隔中,语音信号才保持相对稳定一致的特征, 通常这段时间取5~50ms。在程序中取200个采样点,对于8k的采样频率,即相当于25ms。帧间重叠为100个采样点,亦即12.5ms。
2.1.2预加重
由于语音信号平均功率谱受声门激励和口鼻辐射影响,800HZ以上的高频信号按6DB/倍频跌落,所以求语音信号频谱时,频率越高相应成分越少,高频部分的频谱比低频部分难求,所以要进行预加重处理。在数字语音信号处理中,数字语音信号通常都通过一个低阶的系统(典型的是一个一阶的滤波器),即
式中, 为预加重系数,通常 最为常用的取值是在0.95附近。由于本系统采用的是 =0.94
2.1.3加窗
对每一帧语音进行加窗实质是语音波形乘窗函数,为减少时间窗两端的坡度,使窗口边缘两端平滑过渡到零,减小语音帧的截断效应, 这里采用典型的应用在语音识别系统中加hamming窗。
2.1.4滤波、消除毛刺
由于语音信号包含很多噪声信号,这些噪声信号在时域中表现出高频随机、毛刺等信号,这些信号很可能影响识别的效果,所以,对信号进行带通滤波和消除毛刺处理能很好提高识别的精度。由于人声主要在60-1000HZ ,采用50-1000HZ的FIR带通滤波器对原信号进行滤波,即可获得良好的效果。 消除毛刺影响主要采用语音信号峰谷值检测的方法,把相邻两峰值之间很不明显的谷值和相邻两谷值之间很不明显的峰值去掉,对语音曲线中一些较小的毛刺进行曲线整形,消除那些明显的毛刺!

 举报
举报
更多回帖



