笔试题
const用法
int const *p 表示限制指针P不可变
int * const p 表示 限制p值不可变
int const * const p 表示限制指针P和 p值不可变
osi七层
网络协议osi的分层,路由器在哪一层
应用层,表示层,会话层,传输层,网络层,数据链路层,物理层
路由器在网络层
jni java本地接口
在android系统中,JAVA层是通过java本地接口(JNI)实现本地调用
wifi路由器安全的加密方式
无线路由器主要提供了三种无线安全类型:WPA-PSK/WPA2-PSK和WEP。不同的安全类型下,安全设置项不同。
1、WPA-PSK/WPA2-PSK。
WPA-PSK/WPA2-PSK安全类型其实是WPA/WPA2的一种简化版本,它是基于共享密钥的WPA模式,安全性很高,设置也比较简单,适合普通家庭用户和小型企业使用。其具体设置项见下图所示:该项用来选择系统采用的安全模式,即自动、WPA-PSK、WPA2-PSK。自动:若选择该项,路由器会根据主机请求自动选择WPA-PSK或WPA2-PSK安全模式。
2、WEP
WEP是Wired Equivalent Privacy的缩写,它是一种基本的加密方法,其安全性不如另外两种安全类型高。选择WEP安全类型,路由器将使用802.11基本的WEP安全模式。这里需要注意的是因为802.11N不支持此加密方式,如果您选择此加密方式,路由器可能会工作在较低的传输速率上。
SPI协议简介
SPI,是英语Serial Peripheral interface的缩写,顾名思义就是串行外围设备接口。是Motorola首先在其MC68HCXX系列处理器上定义的。
SPI的通信原理很简单,它以主从方式工作,这种模式通常有一个主设备和一个或多个从设备,需要至少4根线,事实上3根也可以(单向传输时)。也是所有基于SPI的设备共有的,它们是SDI(数据输入),SDO(数据输出),SCK(时钟),CS(片选)。
(1)SDO – 主设备数据输出,从设备数据输入
(2)SDI – 主设备数据输入,从设备数据输出
(3)SCLK – 时钟信号,由主设备产生
(4)CS – 从设备使能信号,由主设备控制 其中CS是控制芯片是否被选中的,也就是说只有片选信号为预先规定的使能信号时(高电位或低电位),对此芯片的操作才有效。这就允许在同一总线上连接多个SPI设备成为可能。
接下来就负责通讯的3根线了。通讯是通过数据交换完成的,这里先要知道SPI是串行通讯协议,也就是说数据是一位一位的传输的。这就是SCK时钟线存在的原因,由SCK提供时钟脉冲,SDI,SDO则基于此脉冲完成数据传输。数据输出通过 SDO线,数据在时钟上升沿或下降沿时改变,在紧接着的下降沿或上升沿被读取。完成一位数据传输,输入也使用同样原理。这样,在至少8次时钟信号的改变(上沿和下沿为一次),就可以完成8位数据的传输。
SPI还是一个数据交换协议:因为SPI的数据输入和输出线独立,所以允许同时完成数据的输入和输出。不同的SPI设备的实现方式不尽相同,主要是数据改变和采集的时间不同,在时钟信号上沿或下沿采集有不同定义,具体请参考相关器件的文档。 在点对点的通信中,SPI接口不需要进行寻址操作,且为全双工通信,显得简单高效。在多个从设备的系统中,每个从设备需要独立的使能信号,硬件上比I2C系统要稍微复杂一些。
AT91RM9200的SPI接口主要由4个引脚构成:SPICLK、MOSI、MISO及 /SS,其中SPICLK是整个SPI总线的公用时钟,MOSI、MISO作为主机,从机的输入输出的标志,MOSI是主机的输出,从机的输入,MISO 是主机的输入,从机的输出。/SS是从机的标志管脚,在互相通信的两个SPI总线的器件,/SS管脚的电平低的是从机,相反/SS管脚的电平高的是主机。
二 SPI协议举例
SPI是一个环形总线结构,由ss(cs)、sck、sdi、sdo构成,其时序其实很简单,主要是在sck的控制下,两个双向移位寄存器进行数据交换。
那么第一个上升沿来的时候 数据将会是sdo=1;寄存器=0101010x。下降沿到来的时候,sdi上的电平将所存到寄存器中去,那么这时寄存器=0101010sdi,这样在 8个时钟脉冲以后,两个寄存器的内容互相交换一次。这样就完成里一个spi时序。
举例:
假设主机和从机初始化就绪:并且主机的***uff=0xaa,从机的***uff=0x55,下面将分步对spi的8个时钟周期的数据情况演示一遍:假设上升沿发送数据这样就完成了两个寄存器8位的交换,上面的上表示上升沿、下表示下降沿,sdi、sdo相对于主机而言的。其中ss引脚作为主机的时候,从机可以把它拉底被动选为从机,作为从机的是时候,可以作为片选脚用。根据以上分析,一个完整的传送周期是16位,即两个字节,因为,首先主机要发送命令过去,然后从机根据主机的命令准备数据,主机在下一个8位时钟周期才把数据读回来。
SPI总线四种工作方式
SPI 模块为了和外设进行数据交换,根据外设工作要求,其输出串行同步时钟极性和相位可以进行配置,时钟极性(CPOL)对传输协议没有重大的影响。如果 CPOL=0,串行同步时钟的空闲状态为低电平;如果CPOL=1,串行同步时钟的空闲状态为高电平。时钟相位(CPHA)能够配置用于选择两种不同的传输协议之一进行数据传输。如果CPHA=0,在串行同步时钟的第一个跳变沿(上升或下降)数据被采样;如果CPHA=1,在串行同步时钟的第二个跳变沿(上升或下降)数据被采样。SPI主模块和与之通信的外设备时钟相位和极性应该一致。
SPI总线包括1根串行同步时钟信号线以及2根数据线。
驱动层次
LINUX中,驱动在系统的什么层次
大致分为三类,字符驱动,块设备驱动,网络设备驱动。
字符设备可以看成是用字节流存取的文件
块设备则可以看成是可以任意存取字节数的字符设备,在应用上只是内核管理数据方式不同
网络设备可以是一个硬件设备,或者是软件设备,他没有相应的read write,它是面向流的一种特殊设备。
1.你平常是怎么用C写嵌入式系统的死循环的?
while(1)
{
//…
}
或者
for(;?
{
//…
{
2.写一条命令,实现在dir以及其子目录下找出所有包含“hello world”字符串的文件
参考答案:
grep -r “hello world” ./dir
或者grep -rHn “hello world” ./
3.下面的两段程序中,循环能否执行?为什么?
unsigned short i;
unsigned short index = 0;
for(i = 0; i
printf(“an”);
}
4>数据类型转换
当不同类型数据进行运算时,需要进行数据类型
转换.
1) 隐式转换------由小类型向大类型转换,
由系统自动转换
char --> short -->int->unsigned int-->
long -->unsigned long -->long long -->
unsigned long long--> float à double-->
long double
例如: 7 + 2.5 ----- > 7.0 + 2.5
====> 9.5
2) 强制转换------由大类型向小类型转换,由程序员
自己转换,一般会丢失数据
char <--short <--- int <--- unsigned int
<--- long <--- unsigned long <---
long long <---unsigned long long
<--- float <--- double <--- long double
例如: 7+2.5 ----> 7 + (int)2.5 ======> 9
不能,unsigned short 0 ~ 65536
(2 Bytes),short -32768 ~ + 32767
(2 Bytes)。int -2147483648 ~
+2147483647 (4 Bytes)当执行到语句
i
的index和1相减时会发生隐式类型转换
,即index将被转换成有符号整型 ,
转换之后的index还是0,因此程序片段
A中的index-1的结果就是 -1 ,此时
判断 i
成立。立即退出循环。
unsigned short i;
unsigned long index = 0;
for(i = 0; i
printf(“bn”);
}
能,index是unsigned long型,当执行到
语句 i
边的index和1相减时也会发生由低精度类型
向高精度方向的隐式类型转换 ,即1将被转
换成无符号长整型 ,因此程序片段B中的
index-1的过程用十六进制数表示实际上就
是0x00000-0x0001=0xffff,此时再把
左边的 i 隐式转换成无符号长整型之后判
断 i
立。立即进入循环。
隐式类型转换规则:
C语言自动转换不同类型的行为称之为隐式类型转换 ,转换的基本原则是:低精度类型向高精度类型转换,具体是:
int -> unsigned int -> long -> unsigned long -> long long -> unsigned long long -> float -> double -> long double
注意,上面的顺序并不一定适用于你的机器,比如当int和long具有相同字长时,unsigned int的精度就会比long的精度高(事实上大多数针对32机的编译器都是如此)。另外需要注意的一点是并没有将char和short型写入上式,原因是他们可以被提升到int也可能被提升到unsigned int。
提升数据的精度通常是一个平滑无损害的过程,但是降低数据的精度可能导致真正的问题。原因很简单:一个较低精度的类型可能不够大,不能存放一个具有更高精度的完整的数据。一个1字节的char变量可以存放整数101但不能存放整数12345。当把浮点类型数据转换为整数类型时,他们被趋零截尾或舍入。
强制类型转换:
通常我们应该避免自动类型转换,当我们需要手动指定一个准确的数据类型时,我们可以用强制类型转换机制来达到我们的目的,使用方法很简单,在需要强制转换类型的变量或常量前面加上(type),例如(double)i; 即把变量 i 强制转换成double型。
4.一个计划跑LINUX系统的ARM系统把bootloader烧录进去后,上电后串口上没有任何输出,硬件和软件各应该去检查什么?
提示: 1.跑LINUX的系统一般都需要外扩DRAM,一般的系统也经常有NOR或NAND FLASH
2.bootloader一般是由汇编和C编写的裸奔程序[5分]
参考答案:
单片机系统:
硬件上:
1.确认电源电压是否正常。用电压表测量接地引脚跟电源引脚之间的电压,看是否是电源电压,例如常用的5V。
2.检查复位引脚电压是否正常。分别测量按下复位按钮和放开复位按钮的电压值,看是否正确。
3.检查晶振是否起振了,一般用示波器来看晶振引脚的波形,另一个办法是测量复位状态下的IO口电平,按住复位键不放,然后测量IO口(没接外部上拉的IO口除外)的电压,看是否是高电平,如果不是高电平,则多半是因为晶振没有起振。
4.检查基本的外扩设备(这里主要是DRAM,特别是DDR/DDR2/DDR3)的pcb layout的走线是否符合要求
软件上:
如果软件代码中:
1.检查CPU和DRAM是否正确初始化(CPU的初始化包括一些典型步骤如: 关闭看门狗,关键FIQ,IRQ中断,关闭MMU和CACHE,调整CPU的频率)
2.检查堆栈指针是否正确设置了
2. 若如NAND FLASH做系统启动部分,则需注意一般需要的从NAND FLASH中拷贝代码到DRAM中的步骤是否能正常完成
5.列举最少3种你所知道的嵌入式的体系结构,并请说明什么是ARM体系结构。[7分]
参考答案:
嵌入式的体系结构包括ARM,MIPS,POWERPC,X86,AVR32,SH等
这个没有非常标准的答案,但由经常面试的时候会问到,关于什么是ARM体系结构主要请参考讲义的ARM相关章节去总结,下面是我的总结,仅供参考:
什么是ARM体系结构?
答:首先,ARM体系结构是ARM公司设计,并授权其合作伙伴生产的占嵌入式市场份额最大的一种RISC(精简指令集)的CPU,它具有高性能、低功耗、低成本的特点。
ARM体系结构从工作模式、工作状态,指令集几个方面简述以下ARM:
ARM体系支持7种工作模式,包括系统(Sys)、未定义指令(und)、数据存取异常(abt)、 管理(SVC)、中断(IRQ)、快速中断(FIQ)、用户模式(usr).其中,除了用户模式以外的其它模式,我们称之为特权模式.它们之间的区别在于有些操作只能在特权模式下才被允许,如直接改变模式和中断使能等. 除了用户模式和系统模式以外的其它5种模式,我们又称之为异常模式。当特定的异常出现的时候,程序就会进入到相应的异常模式中。
备注: 在LINUX系统中, Linux的应用程序工作在usr模式,而内核在正常情况下工作在svc模式,当中断或异常时工作在异常模式
ARM体系结构中CPU有2种工作状态,thumb(指令为16位)和ARM状态(指令为32位),相对寄存器不多,总共37个,它包括通用寄存器r0~r12(FIQ 有自己的r8 ~ r12),栈指针寄存器SP(r13),链接寄存器lr(r14),PC指针寄存器PC(r15),程序状态寄存器CPSR和保存程序状态寄存器SPSR,在上面提到几种异常中,用户(usr)和系统模式(sys)使用相同寄存器, 而其他异常模式有自己独立的SP,LR,SPSR寄存器。
当异常产生时, 硬件上(ARM core)会完成以下动作:
拷贝 程序状态寄存器CPSR 到 保存程序状态寄存器
SPSR_
设置适当的 CPSR 位:
改变处理器状态进入 ARM 态
改变处理器模式进入相应的异常模式
设置中断禁止位禁止相应中断 (如果需要)}保存返回地址到 LR_
设置 PC 为相应的异常向量
返回时, 软件的异常处理程序需要:
从 SPSR_恢复CPSR
从LR_恢复PC
Note:这些操作只能在 ARM 态执行.
ARM处理器是基于精简指令集计算机(RISC)原理设计的,发展过程中商用的指令集经过了v4,v5,v6,v7(cortex系列) 4个系列,ARM内核的通用处理器型号比较常见的有arm7tdmi(v4),arm920/arm920t/arm926ejs,arm10,
arm11,cortex-a8。
为了提高指令执行效率,大部分的ARM指令为单周期指令,并从软件设计角度看,ARM处理器的指令流水线采用3级流水线模型,并提供了LDM/STM类似的批量数据操作指令。
为了提高CPU访问外部设备数据效率,ARM处理器除部分ARM7采用冯.洛伊曼结构外,其他得都采用
哈佛架构,从而实现了**对指令和数据存储器的同时访问。**并且,ARM CPU提供了现代操作系统所需的虚拟内存管理机制(MMU)和指令、数据cache,并提供了协议处理器(cp15)来协助管理CPU的MMU和CACHE。
扩展概念:以上叙述里面提及的概念也要稍微去总结一下,比如:
1.什么是RISC?
RISC(reduced instruction set computer,精简指令集计算机)是一种执行较少类型计算机指令的微处理器,起源于80 年代的MIPS主机(即RISC 机),RISC机中采用的微处理器统称RISC处理器。这样一来,它能够以更快的速度执行操作(每秒执行更多百万条指令,即MIPS)。因为计算机执行每个指令类型都需要额外的晶体管和电路元件,计算机指令集越大就会使微处理器更复杂,执行操作也会更慢。
2.LINUX中为什么需要把中断分为上半部分,下半部分
中断服务程序异步执行,可能会中断其他的重要代码,包括其他中断服务程序。因此,为了避免被中断的代码延迟太长的时间,中断服务程序需要尽快运行,而且执行的时间越短越好,所以中断程序只作必须的工作,其他工作推迟到以后处理。所以Linux把中断处理切为两个部分:上半部和下半部。上半部就是中断处理程序,它需要完成的工作越少越好,执行得越快越好,一旦接收到一个中断,它就立即开始执行。像对时间敏感、与硬件相关、要求保证不被其他中断打断的任务往往放在中断处理程序中执行;而剩下的与中断有相关性但是可以延后的任务,如对数据的操作处理,则推迟一点由下半部完成。下半部分延后执行且执行期间可以相应所有中断,这样可使系统处于中断屏蔽状态的时间尽可能的短,提高了系统的响应能力。实现了程序运行快同时完成的工作量多的目标
3.MMU和CACHE的一些基本原理和知识
嵌入式Linux下ARM9的中断嵌套问题
ARM 下七种exception, 各种exception优先级不同,级别高的可以打断级别低的,如reset可以打断FIQ, FIQ可以打断IRQ, 对于同一种exception,如IQR, 是不可以被另一个IRQ打断的,因为在执行ISR时,该exception(IRQ)已经被关闭了,不可能再响应,这也是为什么我们的exception处理分为了ISR和BH。中断来了之后,CPU只是屏蔽了对应中断的中断信号,其他中断信号线是没有被屏蔽的,中断处理完后应该使能对应的中断信号线同一类型的硬件中断是可以通过软件设置它们之间的优先级的
6.请简述下面这段代码的功能
mov r12, #0x0
ldr r13, =0x30100000
mov r14, #4096
loop:
ldmia r12!, {r0-r11}
stmia r13!, {r0-r11}
cmp r12, r14
blo loop [2分]
参考答案:
借助r0~r11,将内存地址0x0开始的4KB数据拷贝到0x30100000
7.嵌入式中常用的文件系统有哪些?说出它们的主要特点和应用场合?[5分]
参考答案:
嵌入式相关的文件系统: 嵌入式文件系统包括只读和可读写文件系统,一般情况下,只读文件系统启动速度快于可读写的文件系统
嵌入式相关的文件系统包括以下几种:
只读文件系统
cramfs: 压缩的只读文件系统
特点: 启动快,文件最大支持256MB,单个文件最大16MB
squashfs: 只读文件系统
特点: 压缩比最大,启动比cramfs慢
案例:路由器,ubuntu的发行光盘 可结合LZMA压缩算法
可读写的文件系统:
JFFS2: 支持NOR 和NAND FLASH (对NAND的支持天生不足)
特点:
1.可读写
2. 挂载慢(特别是在小文件很多的文件系统中,就更慢)
3. 当数据占到JFFS2分区的75~80%左右时,性能会急剧下降
YAFFS2: 只支持NAND FLASH
特点: 1.可读写
2. 挂载快(特别是在小文件很多的文件系统中,优势更明显)
3.它不是标准内核中的,需通过补丁添加
ubifs:
起码支持NAND FLASH
特点: 1.可读写
2. 挂载快
3.它的实现和其他的文件系统不一样,引进了一个"卷"的概念
在内存中的文件系统:
ramdisk: 描述的是功能,不是格式
启动快,防止用户修改
ramfs: 在内存中的文件系统
tmpfs: 临时文件系统
实时反映系统状态: procfs, sysfs
另外,一些支持SD卡,U盘功能的系统还需要支持
windows文件系统: fat: FAT32
另外,一些带硬盘的嵌入式系统(比如DVR)还需要支持
硬盘的文件系统: EXT3/EXT4
另外,很重要很重要的一点,需要去总结文件过程中遇到的问题,总结比如文件体系挂不上的可能原因
(给个提示,可能有比如网卡或FLASH驱动没加载,内核启动参数传的不对,文件系统制作的步骤不对等好像原因)
制作可烧录的根文件系统镜像
1>linux内核支持的根文件系统镜像的种类
cramfs ----- 只读压缩的文件系统镜像
jffs2 ----- 可读可写压缩的文件系统镜像
yaffs ----- 可读可写不压缩的文件系统镜像
2>制作cramfs类型的文件系统镜像
1) 用命令: mkfs.cramfs制作cramfs镜像
farsight@ubuntu:/opt$ mkfs.cramfs myrootfs/ rootfs.cramfs
2) 将rootfs.cramfs拷贝到 /tftpboot
cp rootfs.cramfs /tftpboot/
3) 将文件系统镜像烧录到nand的rootfs分区中
重启开发板:
FS210 # tftp 40008000 rootfs.cramfs
FS210 # nand erase 0x500000 0x1000000
FS210 # nand write 40008000 0x500000 0x1000000
重新配置uboot参数:
FS210 # set bootargs root=/dev/mtdblock2 rootfstype=cramfs ip=192.168.7.5 init=/linuxrc console=ttySAC0,115200
FS210 # sa
4) 测试:
重启开发板,进入系统后创建一个文件:
[root@farsight /]# touch 1.txt
touch: 1.txt: Read-only file system //提示不同创建文件,文件系统为只读的-----cramfs类型
3>制作jffs2类型的文件系统镜像
1)在线安装mtd包
sudo apt-get install mtd-utils
2) 用命令:mkfs.jffs2制作cramfs镜像
farsight@ubuntu:/opt$ mkfs.jffs2 -r myrootfs/ -o rootfs.jffs2 -e 0x20000 --pad=0x400000 -n
-e nand块大小
--pad 指定rootfs.jffs2的大小,一般分区大小一致 ------该选项是可选,可以不写
-n 不打印不必要的调试信息
3) 将rootfs.jffs2拷贝到 /tftpboot
cp rootfs.jffs2 /tftpboot/
4) 将文件系统镜像烧录到nand的rootfs分区中
重启开发板:
FS210 # tftp 40008000 rootfs.jffs2
FS210 # nand erase 0x500000 0x1000000
FS210 # nand write 40008000 0x500000 0x1000000
重新配置uboot参数:
FS210 # set bootargs root=1f02 rootfstype=jffs2 ip=192.168.7.5 init=/linuxrc console=ttySAC0,115200
FS210 # sa
5) 测试:
重启开发板,进入系统后创建一个文件:
[root@farsight /]# touch 1.txt //可以创建文件,说明该文件系统为可读可写----jffs2类型
[root@farsight /]# ls
1.txt dev home linuxrc opt root sys
bin etc lib mnt proc ***in tmp
4>混合烧录
1) 在 /myrootfs/etc/init.d/rcS脚本文件中添加以下内容:
echo "-------ready to mount /dev/mtdblock3 to /home----------"
/bin/mount -t jffs2 /dev/mtdblock3 /home
2) 重新制作cramfs类型的文件系统镜像
farsight@ubuntu:/opt$ mkfs.cramfs myrootfs/ rootfs.cramfs
3) 将rootfs.cramfs拷贝到 /tftpboot
cp rootfs.cramfs /tftpboot/
4) 将文件系统镜像烧录到nand的rootfs分区中
重启开发板:
FS210 # tftp 40008000 rootfs.cramfs
FS210 # nand erase 0x500000 0x1000000
FS210 # nand write 40008000 0x500000 0x1000000
5) 再制作一个空的文件系统,类型为jffs2
mkdir userdata
mkfs.jffs2 -r userdata/ -o userdata.jffs2 -e 0x20000 --pad=0x400000 -n
cp userdata.jffs2 /tftpboot/
6) 将userdata.jffs2烧录到开发板的nand的userdata分区
31 3 16384 mtdblock3 -----------------
----------------------------------------------- |
0x000000000000-0x000000100000 : "myuboot" |
0x000000100000-0x000000500000 : "kernel" |
0x000000500000-0x000001500000 : "rootfs" |
0x000001500000-0x000002500000 : "userdata" ----|
0x000002500000-0x000040000000 : "usr spec"
FS210 # tftp 40008000 userdata.jffs2
FS210 # nand erase 0x1500000 0x1000000
FS210 # nand write 40008000 0x1500000 0x1000000
7)重新配置uboot参数:
FS210 # set bootargs root=/dev/mtdblock2 rootfstype=cramfs ip=192.168.7.5 init=/linuxrc console=ttySAC0,115200
FS210 # sa
8) 测试:
3,内核烧录
重启开发板,在uboot中:
FS210 # tftp 20008000 zImage_new
FS210 # nand erase 0x100000 0x400000
FS210 # nand write 20008000 0x100000 0x400000
配置uboot:
FS210 # set bootcmd nand read 0x40008000 0x100000 0x400000 ; bootm 0x40008000
FS210 # sa
8.某外设寄存器rGpioBase的地址是0x56000000,寄存器的015位有效,请写出给外设寄存器高八位(8`15位)设置成0xc3的代码[7分]
参考答案:
#define rGpioBase (*((volatile unsigned int *)0x56000000))rGpioBase &= ~0xff00;rGpioBase |= 0xc300; 9.根据时序图和说明编写程序:
 GPIO已经设置好,只需要调用函数gpio_seet_level(int gpio, int level)即课使某个GPIO输出高电平或者低电平。图中用于产生时序的gpio已经分别定义为SSP_XCS,SSP_SCLK,SSP_DIN,level的定义分别为GPIO_LO和GPIO_HI,需要编写函数的原型为:void ssp_io_write_word(u32 command),该函数用来输出一个字(如上图中的A0到C0一组9位),这9个位是在参数command中的低9位. [5分]
参考答案:
这道题立意非常好,做为一个底层工程师,看时序是必须的,相关的代码写法:
GPIO已经设置好,只需要调用函数gpio_seet_level(int gpio, int level)即课使某个GPIO输出高电平或者低电平。图中用于产生时序的gpio已经分别定义为SSP_XCS,SSP_SCLK,SSP_DIN,level的定义分别为GPIO_LO和GPIO_HI,需要编写函数的原型为:void ssp_io_write_word(u32 command),该函数用来输出一个字(如上图中的A0到C0一组9位),这9个位是在参数command中的低9位. [5分]
参考答案:
这道题立意非常好,做为一个底层工程师,看时序是必须的,相关的代码写法:
void ssp_io_wirte_word(u32 command)
{
int i;
//片选
gpio_set_level(SSP_XCS, GPIO_LO);
//送COMMAND
for (i=0; i++; i<9) { //依次送A0,C7~C0
gpio_set_level(SSP_SCLK,GPIO_LO);
gpio_set_level(SSP_DIN, (command >>(8-i))&0x1);
gpio_set_level(SSP_SCLK,GPIO_HI);
}
//结束片选
gpio_set_level(SSP_SCLK,GPIO_LO);
gpio_set_level(SSP_XCS, GPIO_HI);
return;
如果实际结果并没有把数据正确的送出,那
么就需用示波器或者逻辑分析仪看一下波形
是否正确,再根据计算得到的CLK周期看一
下CLK的延时是否合适,否则就加一定延迟
处理
================================
另外,这道题还提醒我们,I2C的时序是要能
记得的,如果不记得,再去复习I2C协议
如果实际结果并没有把数据正确的送出,那么就需用示波器或者逻辑分析仪看一下波形是否正确,再根据计算得到的CLK周期看一下CLK的延时是否合适,否则就加一定延迟处理================================ 另外,这道题还提醒我们,I2C的时序是要能记得的,如果不记得,再去复习I2C协议 10.简述LINUX系统从上电开始到系统起来的主要流程?
提示: 1.可以uboot、内核和文件系统的主要功能去总结
2.这个题主要是在笔试之后的面试,需要在3~5分钟之内表述清楚[8分]
参考答案:
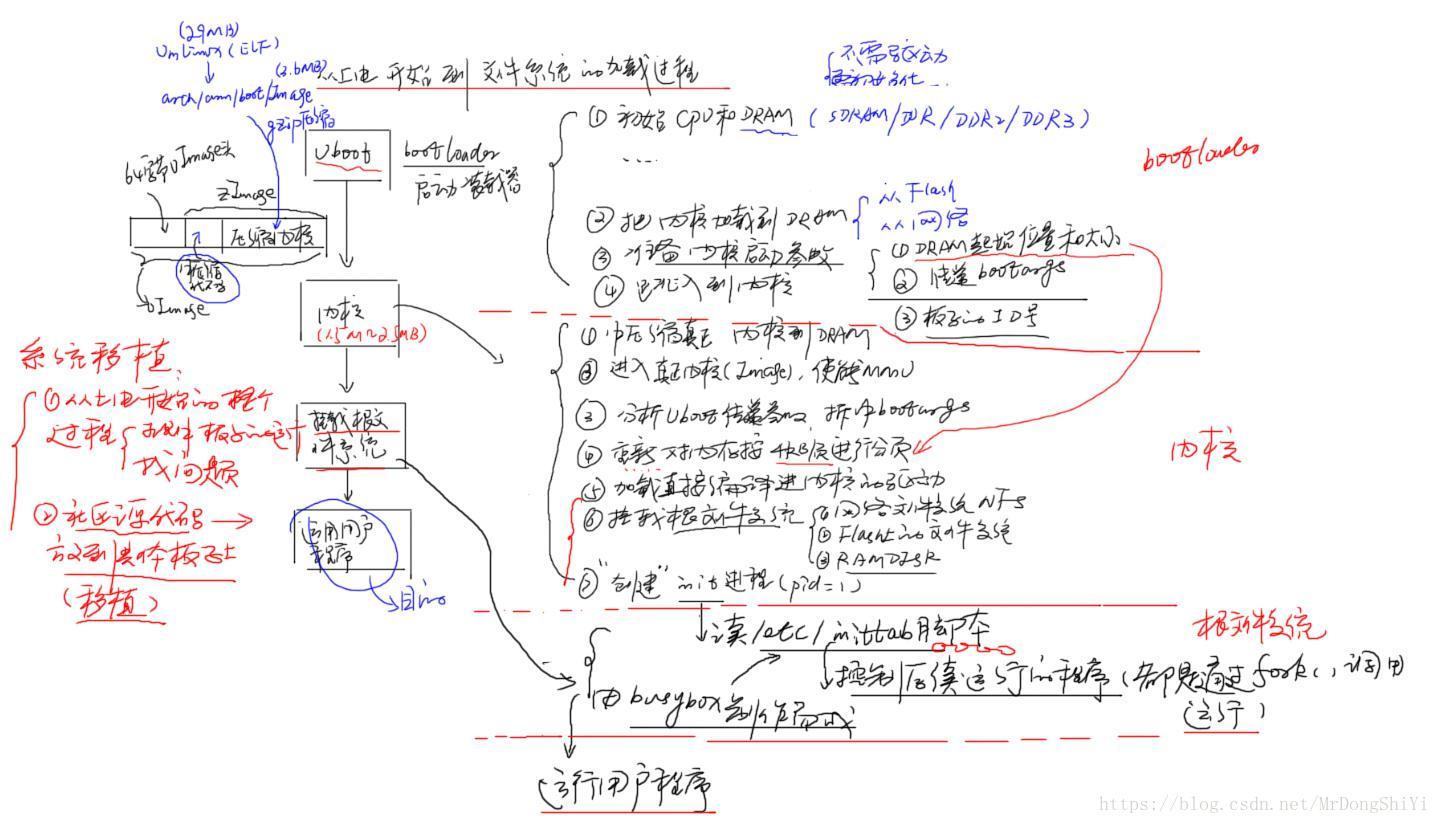
系统启动流程应该从4个方面去总结,bootloader,内核,文件系统挂载,应用程序运行4个方面去总结,先总结大功能,再总结小功能:下面的手绘稿中,先说第一层,再说分开说第二层,在说第二层的时候,可以三星的ARMCPU,以从NAND FLASH启动为例,并在我们的图上加上硬件的相应部分:CPU上电时,CPU里面的ROMCODE负责把booloader的前面部分代码搬移到SRAM,并把SRAM映射成0x0地址,然后跳到0x0地址,另外,bootloader第二层里面,说完初始化CPU(可补充一下CPU的初始化包括进入到管理模式,关闭看门狗,中断,MMU和CACHE)和DRAM后,省略号(…)的位置是在补充一行文字: 把bootloader完整代码拷贝到DRAM中
另外,很重要很重要的一点,需要去总结移植过程中遇到的典型问题和以及自己当时是怎么思考这个问题,并找到解决方法的过程(至少应该总结2~3个问题),也到网上去以比如(uboot, ARM 移植,问题)或(内核 移植 问题)和(文件 移植 问题)这样的关键词去搜看看别人经常遇到什么问题,总结一下!!
 11.如何编写一个LINUX驱动?
提示:主要说字符设备的编写过程 [7分]
参考答案:
这个得对着自己相应模块的驱动的找出其初始化部分并总结,下面是我总结的,仅仅供参考,不要照搬这些东西:切忌照搬,得自己去总结一下主要流程,
以字符设备为例,现在平台设备的驱动一般包括(注意,以下部分要结合一个具体的驱动去说):
一.在系统的资源文件代码中定义platform_device,里面填写对应设备的外设IO起始地址,地址长度,中断,DMA资源等信息资源信息,并把资源信息添加到系统启动初始化流程里面,比如:
11.如何编写一个LINUX驱动?
提示:主要说字符设备的编写过程 [7分]
参考答案:
这个得对着自己相应模块的驱动的找出其初始化部分并总结,下面是我总结的,仅仅供参考,不要照搬这些东西:切忌照搬,得自己去总结一下主要流程,
以字符设备为例,现在平台设备的驱动一般包括(注意,以下部分要结合一个具体的驱动去说):
一.在系统的资源文件代码中定义platform_device,里面填写对应设备的外设IO起始地址,地址长度,中断,DMA资源等信息资源信息,并把资源信息添加到系统启动初始化流程里面,比如:
/* LCD Controller */
static struct resource s3c_lcd_resource[] =
{
[0] = {
.start = S3C24XX_PA_LCD,
.end = S3C24XX_PA_LCD + S3C24XX_SZ_LCD - 1,
.flags = IORESOURCE_MEM,
},
[1] = {
.start = IRQ_LCD,
.end = IRQ_LCD,
.flags = IORESOURCE_IRQ,
}
};
static u64 s3c_device_lcd_dmamask = 0xffffffffUL;
struct platform_device s3c_device_lcd = {
.name = "s3c2410-lcd",
.id = -1,
.num_resources = ARRAY_SIZE(s3c_lcd_resource),
.resource = s3c_lcd_resource,
.dev = {
.dma_mask = &s3c_device_lcd_dmamask,
.coherent_dma_mask = 0xffffffffUL }};
EXPORT_SYMBOL(s3c_device_lcd);
二. 通过module_init(xxx_init)和moule_exit(xxx_init)定义驱动入口和出口函数;
三.写出模块加载xxx_init()和退出的实际处理函数xxx_exit(),这里以xxx_init()为例:
static struct platform_driver s3c2410fb_driver = {
.probe = s3c2410fb_probe,
.remove = s3c2410fb_remove,
.driver = {
.name = "s3c2410-lcd",
.owner = THIS_MODULE,
},
};
五、在xxx_probe()函数里面主要做一下事情:
1.获取平台设备资源的外设IO地址,中断,DMA资源等信息
2.映射外设控制寄存器的外设IO地址到内核的虚拟地址空间
3.使能外设时钟,注册外设中断的处理函数(如果有中断)
4.扫描和初始化硬件
5.最后向LINUX内核注册相应设备并通知应用层的udev/mdev守护进程创建相应的设备节点,或者通过子系统(比如输入子系统,I2C子系统等)注册相应设备并创建设备节点
6.然后,根据字符设备相应的数据结构file_operations的实现里面的比如open,release,read,write,mmap等关键函数,或者通过子系统去注册的话,按子系统要求去实现相应的代码就行了
12.简述LINUX驱动中字符设备和块设备的区别?[5分]
参考答案:
字符设备的特点是数据以字符流的方式进行访问,数据的顺序不能错序,乱序和随机读写,字符设备内核中不需要读写的缓冲,其驱动不支持lseek()函数
块设备的特点是数据是固定块大小(典型值有512字节,2KB,4KB)进行读写,块设备可以随机读写,读写的时候内核中需要缓冲,驱动支持lseek()函数,块设备中数据的访问需要先mount到LINUX的目录文件后才能访问里面的数据
LINUX中字符设备架构相对简单,应用编程的系统调用open,close,read,write和ioctl等函数驱动里面有相应的file_operations结构体里面的函数与之对应
LINUX中块设备架构相对复杂,应用程序的读写会通过块设备里面的文件系统转化为读写的IO请求,块设备驱动里面通过gendisk结构体抽象块设备,并通过对请求队列的处理来实现对块设备的读写曹。
13.试总结单片机底层开发与LINUX驱动开发有哪些异同?[4分]
参考答案:
相同点:
单片机开发和LINUX的驱动开发都有对硬件的操作,最底层对硬件的寄存器操作,对时序的理解是一致的。
不同点:
1.单片机是对外设的IO实地址进行直接操作,而LINUX里面,由于使能了MMU,所以对外设IO地址的操作必须先通过ioremap()或者通过静态映射,把外设IO地址映射到内核的虚拟地址空间后才能正确操作
2.在单片机编写对应设备的驱动不用考虑系统太多的系统分层问题,重用其他的代码量比较小,而LINUX采用分层抽象的思想,在LINUX中编写设备驱动,要按照LINUX已经搭建好的层次结构进行驱动编写,经常调用LINUX提供的函数和机制,代码重用性大
3.由于LINUX是一个多任务的系统,即使在单核CPU上也存在资源竞争的情况(思考一下,LINUX里面那些地方可能导致资源竞争),所以在对驱动的编写的时候,对竞争资源需要采用一定的资源保护机制,比如原子变量,自旋锁等
4.单片机中断处理时,一般直接在产生中断的进入到中断处理函数里面在关中断的情况下处理完中断就可以。而LINUX里面把中断分为2部分,上半部分和下班部分,在上半部分中,是在关中断情况下,只做最基本和最核心的部分,然后在下半部分在开中断情况下,通过LINUX提供的各种机制来处理(思考: LINUX中断的底半部分有哪些模式)
14.请从网卡、USB HOST、LCD驱动器、NAND FLASH、WIFI 、音频芯片中选择一个或者2个(可以以具体的芯片为例),对下面的问题做答:
1.如果是外部扩展芯片,请说出你用的芯片的型号
请注意相应nand flash芯片型号,LCD屏厂家,型号;WIFI型号,音频芯片型号 [每空5分]
15.画出上题中你选定相应硬件模块与CPU的主要引脚连线[5分]
参考答案:
请在纸上自己把自己项目中做的设备的CPU和引脚连线多画几次。
这个需要根据具体模块,画出主要引脚包括数据线,控制线(比如片选,读写控制,以及控制重要时序的引脚),地址线(如有地址的话)
16. 编写上题中你选定相应硬件模块相应LINUX驱动的流程?[6分]
参考答案:
这个对着自己相应模块的驱动的初始化部分,总结一下主要流程,
现在平台设备的驱动一般包括(注意,以下部分要结合你自己的驱动去说):
1.获取平台设备资源的外设IO地址,中断,DMA资源等信息
2.映射外设控制寄存器的外设IO地址到内核的虚拟地址空间
3.使能外设时钟,注册外设中断的处理函数(如果有中断)
4.扫描和初始化硬件
5.最后向LINUX内核注册相应设备
6.然后,根据对应设备是字符设备,块设备,网络设备还是各种子系统的不同
,再提供相应的数据结构里面的关键函数(比如字符设备里面file_operations,块设备里面的gendisk,网络设备里面的net_device)的实现。
ARP和DHCP分别有什么作用
首先,DHCP是动态地址而不是静态地址。
静态ARP,应该就是所谓的ARP绑定,就是将主机的IP地址和MAC地址绑定起来。
在路由器的使用中,如果打开的DHCP,将无需为每台PC手动指定IP地址,PC将会根据路由器里面的DHCP信息进行自动分配。当然,这样就导致同一个IP地址在不同时间里会有不同的PC使用,如果再做ARP绑定,可能会造成PC无法上网的情况。所以,如果要做ARP绑定,建议使用静态IP地址分配。这样可以防止未添加的PC加入网络。
路由器的IP带宽控制指的是通过IP地址来控制带宽,和ARP绑定不是同一个东西。

 ISO的七层模型是什么?TCP/UDP属于哪一层?TCP/UDP有什么优缺点?
应用层
表示层
会话层
运输层
网络层
物理链路层
物理层
tcp /udp属于运输层
TCP 服务提供了数据流传输、可靠性、有效流控制、全双工操作和多路复用技术等。
与 TCP 不同, UDP 并不提供对 IP 协议的可靠机制、流控制以及错误恢复功能等。
由于 UDP 比 较简单, UDP 头包含很少的字节,比 TCP 负载消耗少。
tcp: 提供稳定的传输服务,有流量控制,缺点是包头大,冗余性不好,开销大,实时性较差。
udp: 包头小,开销小 ,占用资源少,实时性较好,缺点是不可靠。
tcp是面向连接的可靠字节流
udp是无连接的不可靠报文传递
已知一个数组table,用一个宏定义,求出数据的元素个数
#define size(array) sizeof(array)/sizeof(array[0]) sizeof(array)就是求整个数组的大小,sizeof(array[0])就是求第一个元素的大小,整个大小除第一个元素的大小就是个数了
用C语言的switch语句和整除试编写一个程序,输入今天是星期几,计算并输出100天后是星期几.
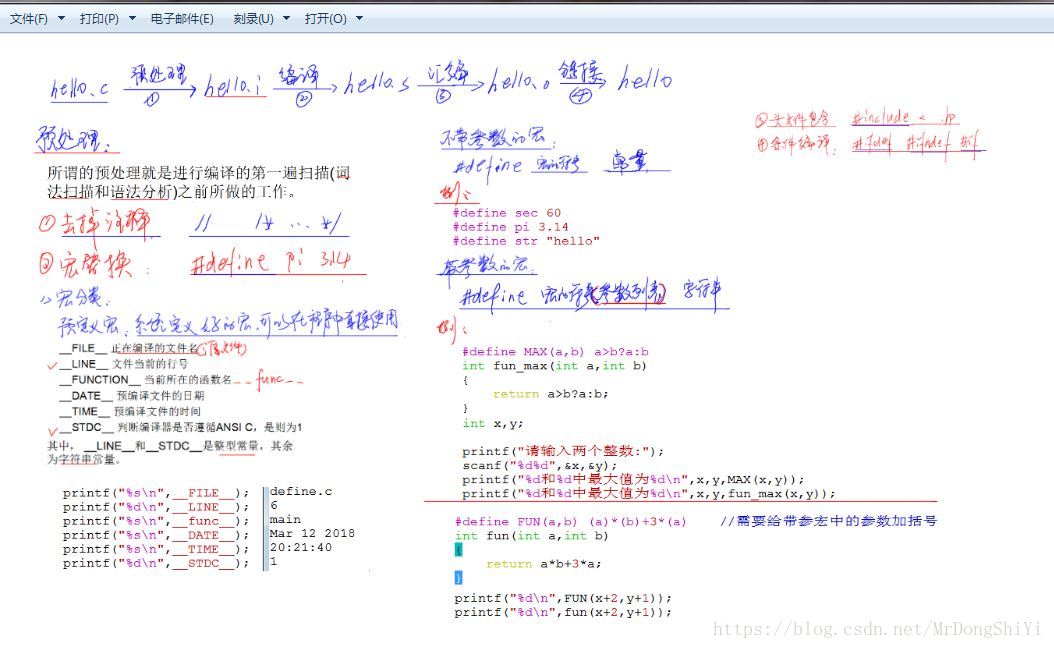
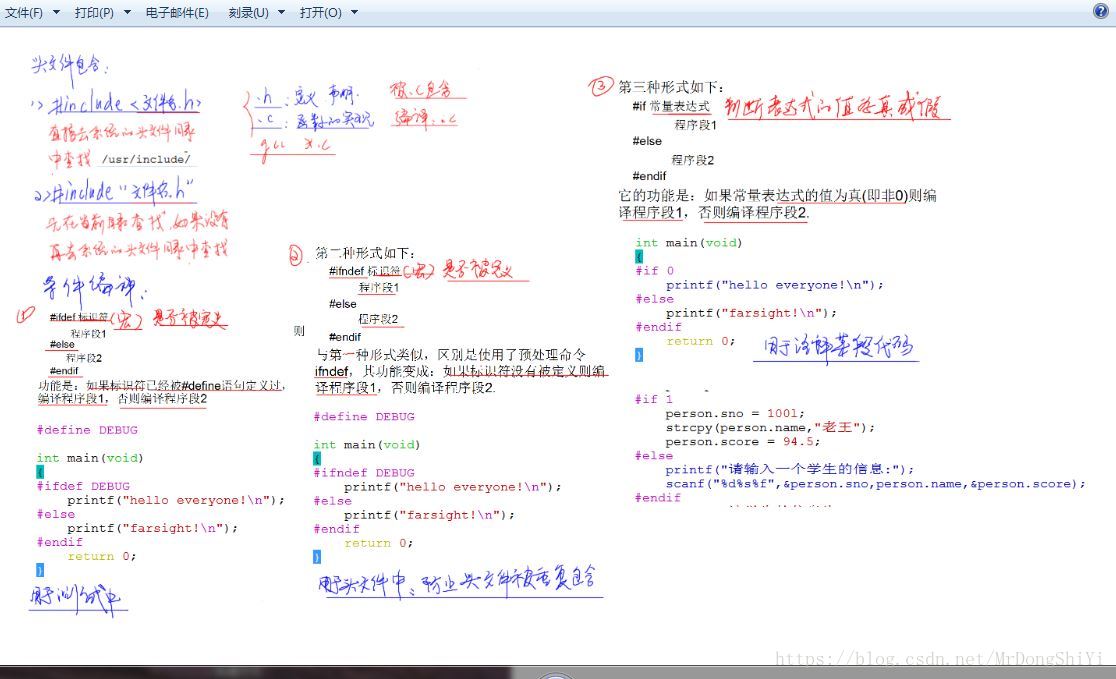
#include"stdio.h"char xq[7][10]={"星期一","星期二","星期三","星期四","星期五","星期六","星期日"};void get_result(int day){int day_after100;//用来保存100后是星期几day_after100=(day-1+100%7)%7;//计算100天后是星期几printf("100天后是:%sn",xq[day_after100]);//输出结果}void main(){int day;printf("今天是星期几:");scanf("%d",&day);while(day<1||day>7){printf("必须是1至7之间的一个数,请重新输入:");scanf("%d",&day);}//当输入的数据不满足规则时,循环输入直到满足规则为止get_result(day);} 什么是预编译
1,宏替换
2,条件编译
3,去掉注释
4,头文件包含
ISO的七层模型是什么?TCP/UDP属于哪一层?TCP/UDP有什么优缺点?
应用层
表示层
会话层
运输层
网络层
物理链路层
物理层
tcp /udp属于运输层
TCP 服务提供了数据流传输、可靠性、有效流控制、全双工操作和多路复用技术等。
与 TCP 不同, UDP 并不提供对 IP 协议的可靠机制、流控制以及错误恢复功能等。
由于 UDP 比 较简单, UDP 头包含很少的字节,比 TCP 负载消耗少。
tcp: 提供稳定的传输服务,有流量控制,缺点是包头大,冗余性不好,开销大,实时性较差。
udp: 包头小,开销小 ,占用资源少,实时性较好,缺点是不可靠。
tcp是面向连接的可靠字节流
udp是无连接的不可靠报文传递
已知一个数组table,用一个宏定义,求出数据的元素个数
#define size(array) sizeof(array)/sizeof(array[0]) sizeof(array)就是求整个数组的大小,sizeof(array[0])就是求第一个元素的大小,整个大小除第一个元素的大小就是个数了
用C语言的switch语句和整除试编写一个程序,输入今天是星期几,计算并输出100天后是星期几.
#include"stdio.h"char xq[7][10]={"星期一","星期二","星期三","星期四","星期五","星期六","星期日"};void get_result(int day){int day_after100;//用来保存100后是星期几day_after100=(day-1+100%7)%7;//计算100天后是星期几printf("100天后是:%sn",xq[day_after100]);//输出结果}void main(){int day;printf("今天是星期几:");scanf("%d",&day);while(day<1||day>7){printf("必须是1至7之间的一个数,请重新输入:");scanf("%d",&day);}//当输入的数据不满足规则时,循环输入直到满足规则为止get_result(day);} 什么是预编译
1,宏替换
2,条件编译
3,去掉注释
4,头文件包含
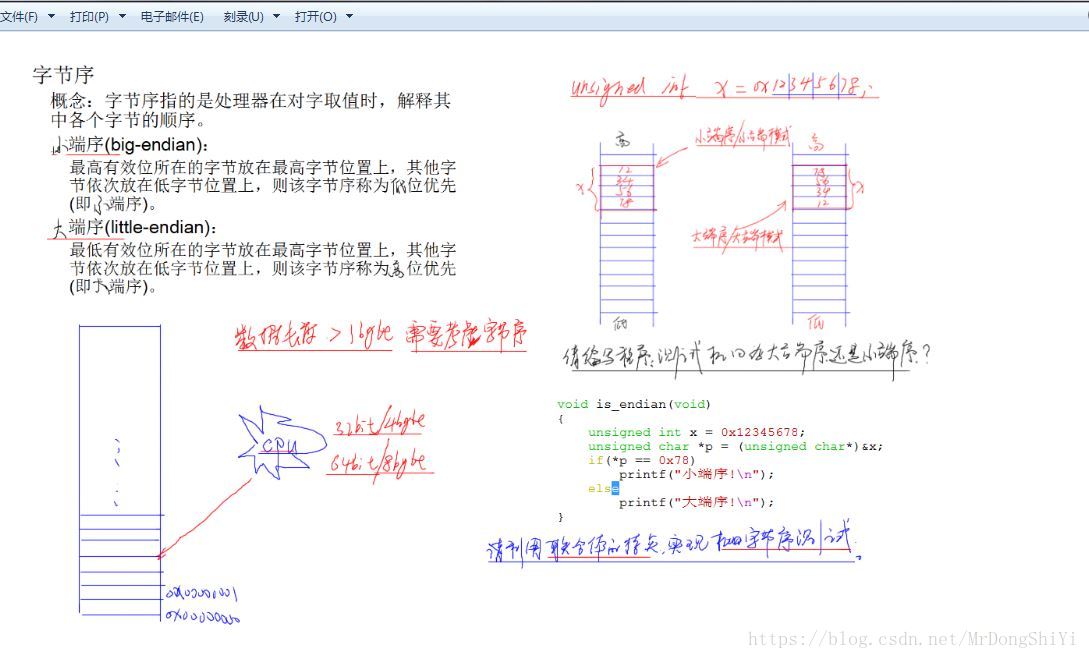
 字节序判断 什么是大端序和小端序
数据的存储方式不一样,大端是高位低字节,低位高字节,小端是低位低字节,高位高字节,既大端序高位先存,小端序低位先存。
采用大小模式对数据进行存放的主要区别在于在存放的字节顺序,大端方式将高位存放在低地址,小端方式将低位存放在高地址。采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。到目前为止,采用大端或者小端进行数据存放,其孰优孰劣也没有定论。
字节序判断 什么是大端序和小端序
数据的存储方式不一样,大端是高位低字节,低位高字节,小端是低位低字节,高位高字节,既大端序高位先存,小端序低位先存。
采用大小模式对数据进行存放的主要区别在于在存放的字节顺序,大端方式将高位存放在低地址,小端方式将低位存放在高地址。采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。到目前为止,采用大端或者小端进行数据存放,其孰优孰劣也没有定论。
 交换两个变量的值,不使用第三个变量,即a=3,b=5,交换之后,a=5,b=3
``
a=a+b; //这个得到的是a和b的和;也就是这一步运行之后当前的a的值就是a,b之和。
b=a-b;//既然a是他们两个的和,那么a-b得出的肯定是最初的a的值;这一步运行之后,b的只就是原始a的值;
a=a-b;//既然b是原始a的值,a是原始a和原始b的和,那么差值肯定就是原始b的值。
如何引用一个已经定义过的全局变量
用extern关键字
头文件包含
可以在不同的C文件中声明同名的全局变量,前提是其中只能有一个C文件中对此变量赋初值,此时连接不会出错。
可以用引用头文件的方式,也可以用extern关键字的方式来引用定义过的全局变量
如果用引用头文件方式来引用某个在头文件中声明的全局变理,假定你将那个变量写错了,那么在编译期间会报错。
全局变量可不可以定义在可被多个.c文件包含的头文件中,为什么
可以,在不同的C文件中以static形式来声明同名全局变量。
可以在不同的C文件中声明同名的全局变量,前提是其中只能有一个C文件中对此变量赋初值,此时连接不会出错
** switch()中不允许的数据类型有**
交换两个变量的值,不使用第三个变量,即a=3,b=5,交换之后,a=5,b=3
``
a=a+b; //这个得到的是a和b的和;也就是这一步运行之后当前的a的值就是a,b之和。
b=a-b;//既然a是他们两个的和,那么a-b得出的肯定是最初的a的值;这一步运行之后,b的只就是原始a的值;
a=a-b;//既然b是原始a的值,a是原始a和原始b的和,那么差值肯定就是原始b的值。
如何引用一个已经定义过的全局变量
用extern关键字
头文件包含
可以在不同的C文件中声明同名的全局变量,前提是其中只能有一个C文件中对此变量赋初值,此时连接不会出错。
可以用引用头文件的方式,也可以用extern关键字的方式来引用定义过的全局变量
如果用引用头文件方式来引用某个在头文件中声明的全局变理,假定你将那个变量写错了,那么在编译期间会报错。
全局变量可不可以定义在可被多个.c文件包含的头文件中,为什么
可以,在不同的C文件中以static形式来声明同名全局变量。
可以在不同的C文件中声明同名的全局变量,前提是其中只能有一个C文件中对此变量赋初值,此时连接不会出错
** switch()中不允许的数据类型有**
- char、short、int、long、bool 基本类型都可以用于switch语句。
- float、double都不能用于switch语句。
- enum类型,即枚举类型可以用于switch语句。
- 所有类型的对象都不能用于switch语句。
- 字符串也不能用于switch语句
6.布尔类型是可以按整数形式转换的。
case标签必须是整型常量表达式
请记住整型常量这四个字,不满足这个特性的不能作为case值,编译会报错。这也决定了switch的参数必须是整型的。 整型,意味着浮点数是不合法的,如case 3.14:不可以;常量,意味着变量是不合法的,如case ival: ival不能是变量。 (1)C++中的const int,注意仅限于C++中的const,C中的const是只读变量,不是常量; (2)单个字符,如case 'a': 是合法的,因为文字字符是常量,被转成ASCII码,为整型; (3)使用#define定义的整型,#define定义的一般为常量,比如#define pi 3.14,但是也必须是整型才可以; (4)使用enum定义的枚举成员。因为枚举成员是const的,且为整型。如果不手动指定枚举值,则默认枚举值为从0开始,依次加1
笔试题
const用法
int const *p 表示限制指针P不可变
int * const p 表示 限制p值不可变
int const * const p 表示限制指针P和 p值不可变
osi七层
网络协议osi的分层,路由器在哪一层
应用层,表示层,会话层,传输层,网络层,数据链路层,物理层
路由器在网络层
jni java本地接口
在android系统中,JAVA层是通过java本地接口(JNI)实现本地调用
wifi路由器安全的加密方式
无线路由器主要提供了三种无线安全类型:WPA-PSK/WPA2-PSK和WEP。不同的安全类型下,安全设置项不同。
1、WPA-PSK/WPA2-PSK。
WPA-PSK/WPA2-PSK安全类型其实是WPA/WPA2的一种简化版本,它是基于共享密钥的WPA模式,安全性很高,设置也比较简单,适合普通家庭用户和小型企业使用。其具体设置项见下图所示:该项用来选择系统采用的安全模式,即自动、WPA-PSK、WPA2-PSK。自动:若选择该项,路由器会根据主机请求自动选择WPA-PSK或WPA2-PSK安全模式。
2、WEP
WEP是Wired Equivalent Privacy的缩写,它是一种基本的加密方法,其安全性不如另外两种安全类型高。选择WEP安全类型,路由器将使用802.11基本的WEP安全模式。这里需要注意的是因为802.11N不支持此加密方式,如果您选择此加密方式,路由器可能会工作在较低的传输速率上。
SPI协议简介
SPI,是英语Serial Peripheral interface的缩写,顾名思义就是串行外围设备接口。是Motorola首先在其MC68HCXX系列处理器上定义的。
SPI的通信原理很简单,它以主从方式工作,这种模式通常有一个主设备和一个或多个从设备,需要至少4根线,事实上3根也可以(单向传输时)。也是所有基于SPI的设备共有的,它们是SDI(数据输入),SDO(数据输出),SCK(时钟),CS(片选)。
(1)SDO – 主设备数据输出,从设备数据输入
(2)SDI – 主设备数据输入,从设备数据输出
(3)SCLK – 时钟信号,由主设备产生
(4)CS – 从设备使能信号,由主设备控制 其中CS是控制芯片是否被选中的,也就是说只有片选信号为预先规定的使能信号时(高电位或低电位),对此芯片的操作才有效。这就允许在同一总线上连接多个SPI设备成为可能。
接下来就负责通讯的3根线了。通讯是通过数据交换完成的,这里先要知道SPI是串行通讯协议,也就是说数据是一位一位的传输的。这就是SCK时钟线存在的原因,由SCK提供时钟脉冲,SDI,SDO则基于此脉冲完成数据传输。数据输出通过 SDO线,数据在时钟上升沿或下降沿时改变,在紧接着的下降沿或上升沿被读取。完成一位数据传输,输入也使用同样原理。这样,在至少8次时钟信号的改变(上沿和下沿为一次),就可以完成8位数据的传输。
SPI还是一个数据交换协议:因为SPI的数据输入和输出线独立,所以允许同时完成数据的输入和输出。不同的SPI设备的实现方式不尽相同,主要是数据改变和采集的时间不同,在时钟信号上沿或下沿采集有不同定义,具体请参考相关器件的文档。 在点对点的通信中,SPI接口不需要进行寻址操作,且为全双工通信,显得简单高效。在多个从设备的系统中,每个从设备需要独立的使能信号,硬件上比I2C系统要稍微复杂一些。
AT91RM9200的SPI接口主要由4个引脚构成:SPICLK、MOSI、MISO及 /SS,其中SPICLK是整个SPI总线的公用时钟,MOSI、MISO作为主机,从机的输入输出的标志,MOSI是主机的输出,从机的输入,MISO 是主机的输入,从机的输出。/SS是从机的标志管脚,在互相通信的两个SPI总线的器件,/SS管脚的电平低的是从机,相反/SS管脚的电平高的是主机。
二 SPI协议举例
SPI是一个环形总线结构,由ss(cs)、sck、sdi、sdo构成,其时序其实很简单,主要是在sck的控制下,两个双向移位寄存器进行数据交换。
那么第一个上升沿来的时候 数据将会是sdo=1;寄存器=0101010x。下降沿到来的时候,sdi上的电平将所存到寄存器中去,那么这时寄存器=0101010sdi,这样在 8个时钟脉冲以后,两个寄存器的内容互相交换一次。这样就完成里一个spi时序。
举例:
假设主机和从机初始化就绪:并且主机的***uff=0xaa,从机的***uff=0x55,下面将分步对spi的8个时钟周期的数据情况演示一遍:假设上升沿发送数据这样就完成了两个寄存器8位的交换,上面的上表示上升沿、下表示下降沿,sdi、sdo相对于主机而言的。其中ss引脚作为主机的时候,从机可以把它拉底被动选为从机,作为从机的是时候,可以作为片选脚用。根据以上分析,一个完整的传送周期是16位,即两个字节,因为,首先主机要发送命令过去,然后从机根据主机的命令准备数据,主机在下一个8位时钟周期才把数据读回来。
SPI总线四种工作方式
SPI 模块为了和外设进行数据交换,根据外设工作要求,其输出串行同步时钟极性和相位可以进行配置,时钟极性(CPOL)对传输协议没有重大的影响。如果 CPOL=0,串行同步时钟的空闲状态为低电平;如果CPOL=1,串行同步时钟的空闲状态为高电平。时钟相位(CPHA)能够配置用于选择两种不同的传输协议之一进行数据传输。如果CPHA=0,在串行同步时钟的第一个跳变沿(上升或下降)数据被采样;如果CPHA=1,在串行同步时钟的第二个跳变沿(上升或下降)数据被采样。SPI主模块和与之通信的外设备时钟相位和极性应该一致。
SPI总线包括1根串行同步时钟信号线以及2根数据线。
驱动层次
LINUX中,驱动在系统的什么层次
大致分为三类,字符驱动,块设备驱动,网络设备驱动。
字符设备可以看成是用字节流存取的文件
块设备则可以看成是可以任意存取字节数的字符设备,在应用上只是内核管理数据方式不同
网络设备可以是一个硬件设备,或者是软件设备,他没有相应的read write,它是面向流的一种特殊设备。
1.你平常是怎么用C写嵌入式系统的死循环的?
while(1)
{
//…
}
或者
for(;?
{
//…
{
2.写一条命令,实现在dir以及其子目录下找出所有包含“hello world”字符串的文件
参考答案:
grep -r “hello world” ./dir
或者grep -rHn “hello world” ./
3.下面的两段程序中,循环能否执行?为什么?
unsigned short i;
unsigned short index = 0;
for(i = 0; i
printf(“an”);
}
4>数据类型转换
当不同类型数据进行运算时,需要进行数据类型
转换.
1) 隐式转换------由小类型向大类型转换,
由系统自动转换
char --> short -->int->unsigned int-->
long -->unsigned long -->long long -->
unsigned long long--> float à double-->
long double
例如: 7 + 2.5 ----- > 7.0 + 2.5
====> 9.5
2) 强制转换------由大类型向小类型转换,由程序员
自己转换,一般会丢失数据
char <--short <--- int <--- unsigned int
<--- long <--- unsigned long <---
long long <---unsigned long long
<--- float <--- double <--- long double
例如: 7+2.5 ----> 7 + (int)2.5 ======> 9
不能,unsigned short 0 ~ 65536
(2 Bytes),short -32768 ~ + 32767
(2 Bytes)。int -2147483648 ~
+2147483647 (4 Bytes)当执行到语句
i
的index和1相减时会发生隐式类型转换
,即index将被转换成有符号整型 ,
转换之后的index还是0,因此程序片段
A中的index-1的结果就是 -1 ,此时
判断 i
成立。立即退出循环。
unsigned short i;
unsigned long index = 0;
for(i = 0; i
printf(“bn”);
}
能,index是unsigned long型,当执行到
语句 i
边的index和1相减时也会发生由低精度类型
向高精度方向的隐式类型转换 ,即1将被转
换成无符号长整型 ,因此程序片段B中的
index-1的过程用十六进制数表示实际上就
是0x00000-0x0001=0xffff,此时再把
左边的 i 隐式转换成无符号长整型之后判
断 i
立。立即进入循环。
隐式类型转换规则:
C语言自动转换不同类型的行为称之为隐式类型转换 ,转换的基本原则是:低精度类型向高精度类型转换,具体是:
int -> unsigned int -> long -> unsigned long -> long long -> unsigned long long -> float -> double -> long double
注意,上面的顺序并不一定适用于你的机器,比如当int和long具有相同字长时,unsigned int的精度就会比long的精度高(事实上大多数针对32机的编译器都是如此)。另外需要注意的一点是并没有将char和short型写入上式,原因是他们可以被提升到int也可能被提升到unsigned int。
提升数据的精度通常是一个平滑无损害的过程,但是降低数据的精度可能导致真正的问题。原因很简单:一个较低精度的类型可能不够大,不能存放一个具有更高精度的完整的数据。一个1字节的char变量可以存放整数101但不能存放整数12345。当把浮点类型数据转换为整数类型时,他们被趋零截尾或舍入。
强制类型转换:
通常我们应该避免自动类型转换,当我们需要手动指定一个准确的数据类型时,我们可以用强制类型转换机制来达到我们的目的,使用方法很简单,在需要强制转换类型的变量或常量前面加上(type),例如(double)i; 即把变量 i 强制转换成double型。
4.一个计划跑LINUX系统的ARM系统把bootloader烧录进去后,上电后串口上没有任何输出,硬件和软件各应该去检查什么?
提示: 1.跑LINUX的系统一般都需要外扩DRAM,一般的系统也经常有NOR或NAND FLASH
2.bootloader一般是由汇编和C编写的裸奔程序[5分]
参考答案:
单片机系统:
硬件上:
1.确认电源电压是否正常。用电压表测量接地引脚跟电源引脚之间的电压,看是否是电源电压,例如常用的5V。
2.检查复位引脚电压是否正常。分别测量按下复位按钮和放开复位按钮的电压值,看是否正确。
3.检查晶振是否起振了,一般用示波器来看晶振引脚的波形,另一个办法是测量复位状态下的IO口电平,按住复位键不放,然后测量IO口(没接外部上拉的IO口除外)的电压,看是否是高电平,如果不是高电平,则多半是因为晶振没有起振。
4.检查基本的外扩设备(这里主要是DRAM,特别是DDR/DDR2/DDR3)的pcb layout的走线是否符合要求
软件上:
如果软件代码中:
1.检查CPU和DRAM是否正确初始化(CPU的初始化包括一些典型步骤如: 关闭看门狗,关键FIQ,IRQ中断,关闭MMU和CACHE,调整CPU的频率)
2.检查堆栈指针是否正确设置了
2. 若如NAND FLASH做系统启动部分,则需注意一般需要的从NAND FLASH中拷贝代码到DRAM中的步骤是否能正常完成
5.列举最少3种你所知道的嵌入式的体系结构,并请说明什么是ARM体系结构。[7分]
参考答案:
嵌入式的体系结构包括ARM,MIPS,POWERPC,X86,AVR32,SH等
这个没有非常标准的答案,但由经常面试的时候会问到,关于什么是ARM体系结构主要请参考讲义的ARM相关章节去总结,下面是我的总结,仅供参考:
什么是ARM体系结构?
答:首先,ARM体系结构是ARM公司设计,并授权其合作伙伴生产的占嵌入式市场份额最大的一种RISC(精简指令集)的CPU,它具有高性能、低功耗、低成本的特点。
ARM体系结构从工作模式、工作状态,指令集几个方面简述以下ARM:
ARM体系支持7种工作模式,包括系统(Sys)、未定义指令(und)、数据存取异常(abt)、 管理(SVC)、中断(IRQ)、快速中断(FIQ)、用户模式(usr).其中,除了用户模式以外的其它模式,我们称之为特权模式.它们之间的区别在于有些操作只能在特权模式下才被允许,如直接改变模式和中断使能等. 除了用户模式和系统模式以外的其它5种模式,我们又称之为异常模式。当特定的异常出现的时候,程序就会进入到相应的异常模式中。
备注: 在LINUX系统中, Linux的应用程序工作在usr模式,而内核在正常情况下工作在svc模式,当中断或异常时工作在异常模式
ARM体系结构中CPU有2种工作状态,thumb(指令为16位)和ARM状态(指令为32位),相对寄存器不多,总共37个,它包括通用寄存器r0~r12(FIQ 有自己的r8 ~ r12),栈指针寄存器SP(r13),链接寄存器lr(r14),PC指针寄存器PC(r15),程序状态寄存器CPSR和保存程序状态寄存器SPSR,在上面提到几种异常中,用户(usr)和系统模式(sys)使用相同寄存器, 而其他异常模式有自己独立的SP,LR,SPSR寄存器。
当异常产生时, 硬件上(ARM core)会完成以下动作:
拷贝 程序状态寄存器CPSR 到 保存程序状态寄存器
SPSR_
设置适当的 CPSR 位:
改变处理器状态进入 ARM 态
改变处理器模式进入相应的异常模式
设置中断禁止位禁止相应中断 (如果需要)}保存返回地址到 LR_
设置 PC 为相应的异常向量
返回时, 软件的异常处理程序需要:
从 SPSR_恢复CPSR
从LR_恢复PC
Note:这些操作只能在 ARM 态执行.
ARM处理器是基于精简指令集计算机(RISC)原理设计的,发展过程中商用的指令集经过了v4,v5,v6,v7(cortex系列) 4个系列,ARM内核的通用处理器型号比较常见的有arm7tdmi(v4),arm920/arm920t/arm926ejs,arm10,
arm11,cortex-a8。
为了提高指令执行效率,大部分的ARM指令为单周期指令,并从软件设计角度看,ARM处理器的指令流水线采用3级流水线模型,并提供了LDM/STM类似的批量数据操作指令。
为了提高CPU访问外部设备数据效率,ARM处理器除部分ARM7采用冯.洛伊曼结构外,其他得都采用
哈佛架构,从而实现了**对指令和数据存储器的同时访问。**并且,ARM CPU提供了现代操作系统所需的虚拟内存管理机制(MMU)和指令、数据cache,并提供了协议处理器(cp15)来协助管理CPU的MMU和CACHE。
扩展概念:以上叙述里面提及的概念也要稍微去总结一下,比如:
1.什么是RISC?
RISC(reduced instruction set computer,精简指令集计算机)是一种执行较少类型计算机指令的微处理器,起源于80 年代的MIPS主机(即RISC 机),RISC机中采用的微处理器统称RISC处理器。这样一来,它能够以更快的速度执行操作(每秒执行更多百万条指令,即MIPS)。因为计算机执行每个指令类型都需要额外的晶体管和电路元件,计算机指令集越大就会使微处理器更复杂,执行操作也会更慢。
2.LINUX中为什么需要把中断分为上半部分,下半部分
中断服务程序异步执行,可能会中断其他的重要代码,包括其他中断服务程序。因此,为了避免被中断的代码延迟太长的时间,中断服务程序需要尽快运行,而且执行的时间越短越好,所以中断程序只作必须的工作,其他工作推迟到以后处理。所以Linux把中断处理切为两个部分:上半部和下半部。上半部就是中断处理程序,它需要完成的工作越少越好,执行得越快越好,一旦接收到一个中断,它就立即开始执行。像对时间敏感、与硬件相关、要求保证不被其他中断打断的任务往往放在中断处理程序中执行;而剩下的与中断有相关性但是可以延后的任务,如对数据的操作处理,则推迟一点由下半部完成。下半部分延后执行且执行期间可以相应所有中断,这样可使系统处于中断屏蔽状态的时间尽可能的短,提高了系统的响应能力。实现了程序运行快同时完成的工作量多的目标
3.MMU和CACHE的一些基本原理和知识
嵌入式Linux下ARM9的中断嵌套问题
ARM 下七种exception, 各种exception优先级不同,级别高的可以打断级别低的,如reset可以打断FIQ, FIQ可以打断IRQ, 对于同一种exception,如IQR, 是不可以被另一个IRQ打断的,因为在执行ISR时,该exception(IRQ)已经被关闭了,不可能再响应,这也是为什么我们的exception处理分为了ISR和BH。中断来了之后,CPU只是屏蔽了对应中断的中断信号,其他中断信号线是没有被屏蔽的,中断处理完后应该使能对应的中断信号线同一类型的硬件中断是可以通过软件设置它们之间的优先级的
6.请简述下面这段代码的功能
mov r12, #0x0
ldr r13, =0x30100000
mov r14, #4096
loop:
ldmia r12!, {r0-r11}
stmia r13!, {r0-r11}
cmp r12, r14
blo loop [2分]
参考答案:
借助r0~r11,将内存地址0x0开始的4KB数据拷贝到0x30100000
7.嵌入式中常用的文件系统有哪些?说出它们的主要特点和应用场合?[5分]
参考答案:
嵌入式相关的文件系统: 嵌入式文件系统包括只读和可读写文件系统,一般情况下,只读文件系统启动速度快于可读写的文件系统
嵌入式相关的文件系统包括以下几种:
只读文件系统
cramfs: 压缩的只读文件系统
特点: 启动快,文件最大支持256MB,单个文件最大16MB
squashfs: 只读文件系统
特点: 压缩比最大,启动比cramfs慢
案例:路由器,ubuntu的发行光盘 可结合LZMA压缩算法
可读写的文件系统:
JFFS2: 支持NOR 和NAND FLASH (对NAND的支持天生不足)
特点:
1.可读写
2. 挂载慢(特别是在小文件很多的文件系统中,就更慢)
3. 当数据占到JFFS2分区的75~80%左右时,性能会急剧下降
YAFFS2: 只支持NAND FLASH
特点: 1.可读写
2. 挂载快(特别是在小文件很多的文件系统中,优势更明显)
3.它不是标准内核中的,需通过补丁添加
ubifs:
起码支持NAND FLASH
特点: 1.可读写
2. 挂载快
3.它的实现和其他的文件系统不一样,引进了一个"卷"的概念
在内存中的文件系统:
ramdisk: 描述的是功能,不是格式
启动快,防止用户修改
ramfs: 在内存中的文件系统
tmpfs: 临时文件系统
实时反映系统状态: procfs, sysfs
另外,一些支持SD卡,U盘功能的系统还需要支持
windows文件系统: fat: FAT32
另外,一些带硬盘的嵌入式系统(比如DVR)还需要支持
硬盘的文件系统: EXT3/EXT4
另外,很重要很重要的一点,需要去总结文件过程中遇到的问题,总结比如文件体系挂不上的可能原因
(给个提示,可能有比如网卡或FLASH驱动没加载,内核启动参数传的不对,文件系统制作的步骤不对等好像原因)
制作可烧录的根文件系统镜像
1>linux内核支持的根文件系统镜像的种类
cramfs ----- 只读压缩的文件系统镜像
jffs2 ----- 可读可写压缩的文件系统镜像
yaffs ----- 可读可写不压缩的文件系统镜像
2>制作cramfs类型的文件系统镜像
1) 用命令: mkfs.cramfs制作cramfs镜像
farsight@ubuntu:/opt$ mkfs.cramfs myrootfs/ rootfs.cramfs
2) 将rootfs.cramfs拷贝到 /tftpboot
cp rootfs.cramfs /tftpboot/
3) 将文件系统镜像烧录到nand的rootfs分区中
重启开发板:
FS210 # tftp 40008000 rootfs.cramfs
FS210 # nand erase 0x500000 0x1000000
FS210 # nand write 40008000 0x500000 0x1000000
重新配置uboot参数:
FS210 # set bootargs root=/dev/mtdblock2 rootfstype=cramfs ip=192.168.7.5 init=/linuxrc console=ttySAC0,115200
FS210 # sa
4) 测试:
重启开发板,进入系统后创建一个文件:
[root@farsight /]# touch 1.txt
touch: 1.txt: Read-only file system //提示不同创建文件,文件系统为只读的-----cramfs类型
3>制作jffs2类型的文件系统镜像
1)在线安装mtd包
sudo apt-get install mtd-utils
2) 用命令:mkfs.jffs2制作cramfs镜像
farsight@ubuntu:/opt$ mkfs.jffs2 -r myrootfs/ -o rootfs.jffs2 -e 0x20000 --pad=0x400000 -n
-e nand块大小
--pad 指定rootfs.jffs2的大小,一般分区大小一致 ------该选项是可选,可以不写
-n 不打印不必要的调试信息
3) 将rootfs.jffs2拷贝到 /tftpboot
cp rootfs.jffs2 /tftpboot/
4) 将文件系统镜像烧录到nand的rootfs分区中
重启开发板:
FS210 # tftp 40008000 rootfs.jffs2
FS210 # nand erase 0x500000 0x1000000
FS210 # nand write 40008000 0x500000 0x1000000
重新配置uboot参数:
FS210 # set bootargs root=1f02 rootfstype=jffs2 ip=192.168.7.5 init=/linuxrc console=ttySAC0,115200
FS210 # sa
5) 测试:
重启开发板,进入系统后创建一个文件:
[root@farsight /]# touch 1.txt //可以创建文件,说明该文件系统为可读可写----jffs2类型
[root@farsight /]# ls
1.txt dev home linuxrc opt root sys
bin etc lib mnt proc ***in tmp
4>混合烧录
1) 在 /myrootfs/etc/init.d/rcS脚本文件中添加以下内容:
echo "-------ready to mount /dev/mtdblock3 to /home----------"
/bin/mount -t jffs2 /dev/mtdblock3 /home
2) 重新制作cramfs类型的文件系统镜像
farsight@ubuntu:/opt$ mkfs.cramfs myrootfs/ rootfs.cramfs
3) 将rootfs.cramfs拷贝到 /tftpboot
cp rootfs.cramfs /tftpboot/
4) 将文件系统镜像烧录到nand的rootfs分区中
重启开发板:
FS210 # tftp 40008000 rootfs.cramfs
FS210 # nand erase 0x500000 0x1000000
FS210 # nand write 40008000 0x500000 0x1000000
5) 再制作一个空的文件系统,类型为jffs2
mkdir userdata
mkfs.jffs2 -r userdata/ -o userdata.jffs2 -e 0x20000 --pad=0x400000 -n
cp userdata.jffs2 /tftpboot/
6) 将userdata.jffs2烧录到开发板的nand的userdata分区
31 3 16384 mtdblock3 -----------------
----------------------------------------------- |
0x000000000000-0x000000100000 : "myuboot" |
0x000000100000-0x000000500000 : "kernel" |
0x000000500000-0x000001500000 : "rootfs" |
0x000001500000-0x000002500000 : "userdata" ----|
0x000002500000-0x000040000000 : "usr spec"
FS210 # tftp 40008000 userdata.jffs2
FS210 # nand erase 0x1500000 0x1000000
FS210 # nand write 40008000 0x1500000 0x1000000
7)重新配置uboot参数:
FS210 # set bootargs root=/dev/mtdblock2 rootfstype=cramfs ip=192.168.7.5 init=/linuxrc console=ttySAC0,115200
FS210 # sa
8) 测试:
3,内核烧录
重启开发板,在uboot中:
FS210 # tftp 20008000 zImage_new
FS210 # nand erase 0x100000 0x400000
FS210 # nand write 20008000 0x100000 0x400000
配置uboot:
FS210 # set bootcmd nand read 0x40008000 0x100000 0x400000 ; bootm 0x40008000
FS210 # sa
8.某外设寄存器rGpioBase的地址是0x56000000,寄存器的015位有效,请写出给外设寄存器高八位(8`15位)设置成0xc3的代码[7分]
参考答案:
#define rGpioBase (*((volatile unsigned int *)0x56000000))rGpioBase &= ~0xff00;rGpioBase |= 0xc300; 9.根据时序图和说明编写程序:
GPIO已经设置好,只需要调用函数gpio_seet_level(int gpio, int level)即课使某个GPIO输出高电平或者低电平。图中用于产生时序的gpio已经分别定义为SSP_XCS,SSP_SCLK,SSP_DIN,level的定义分别为GPIO_LO和GPIO_HI,需要编写函数的原型为:void ssp_io_write_word(u32 command),该函数用来输出一个字(如上图中的A0到C0一组9位),这9个位是在参数command中的低9位. [5分]
参考答案:
这道题立意非常好,做为一个底层工程师,看时序是必须的,相关的代码写法:
void ssp_io_wirte_word(u32 command)
{
int i;
//片选
gpio_set_level(SSP_XCS, GPIO_LO);
//送COMMAND
for (i=0; i++; i<9) { //依次送A0,C7~C0
gpio_set_level(SSP_SCLK,GPIO_LO);
gpio_set_level(SSP_DIN, (command >>(8-i))&0x1);
gpio_set_level(SSP_SCLK,GPIO_HI);
}
//结束片选
gpio_set_level(SSP_SCLK,GPIO_LO);
gpio_set_level(SSP_XCS, GPIO_HI);
return;
如果实际结果并没有把数据正确的送出,那
么就需用示波器或者逻辑分析仪看一下波形
是否正确,再根据计算得到的CLK周期看一
下CLK的延时是否合适,否则就加一定延迟
处理
================================
另外,这道题还提醒我们,I2C的时序是要能
记得的,如果不记得,再去复习I2C协议
如果实际结果并没有把数据正确的送出,那么就需用示波器或者逻辑分析仪看一下波形是否正确,再根据计算得到的CLK周期看一下CLK的延时是否合适,否则就加一定延迟处理================================ 另外,这道题还提醒我们,I2C的时序是要能记得的,如果不记得,再去复习I2C协议 10.简述LINUX系统从上电开始到系统起来的主要流程?
提示: 1.可以uboot、内核和文件系统的主要功能去总结
2.这个题主要是在笔试之后的面试,需要在3~5分钟之内表述清楚[8分]
参考答案:
系统启动流程应该从4个方面去总结,bootloader,内核,文件系统挂载,应用程序运行4个方面去总结,先总结大功能,再总结小功能:下面的手绘稿中,先说第一层,再说分开说第二层,在说第二层的时候,可以三星的ARMCPU,以从NAND FLASH启动为例,并在我们的图上加上硬件的相应部分:CPU上电时,CPU里面的ROMCODE负责把booloader的前面部分代码搬移到SRAM,并把SRAM映射成0x0地址,然后跳到0x0地址,另外,bootloader第二层里面,说完初始化CPU(可补充一下CPU的初始化包括进入到管理模式,关闭看门狗,中断,MMU和CACHE)和DRAM后,省略号(…)的位置是在补充一行文字: 把bootloader完整代码拷贝到DRAM中
另外,很重要很重要的一点,需要去总结移植过程中遇到的典型问题和以及自己当时是怎么思考这个问题,并找到解决方法的过程(至少应该总结2~3个问题),也到网上去以比如(uboot, ARM 移植,问题)或(内核 移植 问题)和(文件 移植 问题)这样的关键词去搜看看别人经常遇到什么问题,总结一下!!
11.如何编写一个LINUX驱动?
提示:主要说字符设备的编写过程 [7分]
参考答案:
这个得对着自己相应模块的驱动的找出其初始化部分并总结,下面是我总结的,仅仅供参考,不要照搬这些东西:切忌照搬,得自己去总结一下主要流程,
以字符设备为例,现在平台设备的驱动一般包括(注意,以下部分要结合一个具体的驱动去说):
一.在系统的资源文件代码中定义platform_device,里面填写对应设备的外设IO起始地址,地址长度,中断,DMA资源等信息资源信息,并把资源信息添加到系统启动初始化流程里面,比如:
/* LCD Controller */
static struct resource s3c_lcd_resource[] =
{
[0] = {
.start = S3C24XX_PA_LCD,
.end = S3C24XX_PA_LCD + S3C24XX_SZ_LCD - 1,
.flags = IORESOURCE_MEM,
},
[1] = {
.start = IRQ_LCD,
.end = IRQ_LCD,
.flags = IORESOURCE_IRQ,
}
};
static u64 s3c_device_lcd_dmamask = 0xffffffffUL;
struct platform_device s3c_device_lcd = {
.name = "s3c2410-lcd",
.id = -1,
.num_resources = ARRAY_SIZE(s3c_lcd_resource),
.resource = s3c_lcd_resource,
.dev = {
.dma_mask = &s3c_device_lcd_dmamask,
.coherent_dma_mask = 0xffffffffUL }};
EXPORT_SYMBOL(s3c_device_lcd);
二. 通过module_init(xxx_init)和moule_exit(xxx_init)定义驱动入口和出口函数;
三.写出模块加载xxx_init()和退出的实际处理函数xxx_exit(),这里以xxx_init()为例:
static struct platform_driver s3c2410fb_driver = {
.probe = s3c2410fb_probe,
.remove = s3c2410fb_remove,
.driver = {
.name = "s3c2410-lcd",
.owner = THIS_MODULE,
},
};
五、在xxx_probe()函数里面主要做一下事情:
1.获取平台设备资源的外设IO地址,中断,DMA资源等信息
2.映射外设控制寄存器的外设IO地址到内核的虚拟地址空间
3.使能外设时钟,注册外设中断的处理函数(如果有中断)
4.扫描和初始化硬件
5.最后向LINUX内核注册相应设备并通知应用层的udev/mdev守护进程创建相应的设备节点,或者通过子系统(比如输入子系统,I2C子系统等)注册相应设备并创建设备节点
6.然后,根据字符设备相应的数据结构file_operations的实现里面的比如open,release,read,write,mmap等关键函数,或者通过子系统去注册的话,按子系统要求去实现相应的代码就行了
12.简述LINUX驱动中字符设备和块设备的区别?[5分]
参考答案:
字符设备的特点是数据以字符流的方式进行访问,数据的顺序不能错序,乱序和随机读写,字符设备内核中不需要读写的缓冲,其驱动不支持lseek()函数
块设备的特点是数据是固定块大小(典型值有512字节,2KB,4KB)进行读写,块设备可以随机读写,读写的时候内核中需要缓冲,驱动支持lseek()函数,块设备中数据的访问需要先mount到LINUX的目录文件后才能访问里面的数据
LINUX中字符设备架构相对简单,应用编程的系统调用open,close,read,write和ioctl等函数驱动里面有相应的file_operations结构体里面的函数与之对应
LINUX中块设备架构相对复杂,应用程序的读写会通过块设备里面的文件系统转化为读写的IO请求,块设备驱动里面通过gendisk结构体抽象块设备,并通过对请求队列的处理来实现对块设备的读写曹。
13.试总结单片机底层开发与LINUX驱动开发有哪些异同?[4分]
参考答案:
相同点:
单片机开发和LINUX的驱动开发都有对硬件的操作,最底层对硬件的寄存器操作,对时序的理解是一致的。
不同点:
1.单片机是对外设的IO实地址进行直接操作,而LINUX里面,由于使能了MMU,所以对外设IO地址的操作必须先通过ioremap()或者通过静态映射,把外设IO地址映射到内核的虚拟地址空间后才能正确操作
2.在单片机编写对应设备的驱动不用考虑系统太多的系统分层问题,重用其他的代码量比较小,而LINUX采用分层抽象的思想,在LINUX中编写设备驱动,要按照LINUX已经搭建好的层次结构进行驱动编写,经常调用LINUX提供的函数和机制,代码重用性大
3.由于LINUX是一个多任务的系统,即使在单核CPU上也存在资源竞争的情况(思考一下,LINUX里面那些地方可能导致资源竞争),所以在对驱动的编写的时候,对竞争资源需要采用一定的资源保护机制,比如原子变量,自旋锁等
4.单片机中断处理时,一般直接在产生中断的进入到中断处理函数里面在关中断的情况下处理完中断就可以。而LINUX里面把中断分为2部分,上半部分和下班部分,在上半部分中,是在关中断情况下,只做最基本和最核心的部分,然后在下半部分在开中断情况下,通过LINUX提供的各种机制来处理(思考: LINUX中断的底半部分有哪些模式)
14.请从网卡、USB HOST、LCD驱动器、NAND FLASH、WIFI 、音频芯片中选择一个或者2个(可以以具体的芯片为例),对下面的问题做答:
1.如果是外部扩展芯片,请说出你用的芯片的型号
请注意相应nand flash芯片型号,LCD屏厂家,型号;WIFI型号,音频芯片型号 [每空5分]
15.画出上题中你选定相应硬件模块与CPU的主要引脚连线[5分]
参考答案:
请在纸上自己把自己项目中做的设备的CPU和引脚连线多画几次。
这个需要根据具体模块,画出主要引脚包括数据线,控制线(比如片选,读写控制,以及控制重要时序的引脚),地址线(如有地址的话)
16. 编写上题中你选定相应硬件模块相应LINUX驱动的流程?[6分]
参考答案:
这个对着自己相应模块的驱动的初始化部分,总结一下主要流程,
现在平台设备的驱动一般包括(注意,以下部分要结合你自己的驱动去说):
1.获取平台设备资源的外设IO地址,中断,DMA资源等信息
2.映射外设控制寄存器的外设IO地址到内核的虚拟地址空间
3.使能外设时钟,注册外设中断的处理函数(如果有中断)
4.扫描和初始化硬件
5.最后向LINUX内核注册相应设备
6.然后,根据对应设备是字符设备,块设备,网络设备还是各种子系统的不同
,再提供相应的数据结构里面的关键函数(比如字符设备里面file_operations,块设备里面的gendisk,网络设备里面的net_device)的实现。
ARP和DHCP分别有什么作用
首先,DHCP是动态地址而不是静态地址。
静态ARP,应该就是所谓的ARP绑定,就是将主机的IP地址和MAC地址绑定起来。
在路由器的使用中,如果打开的DHCP,将无需为每台PC手动指定IP地址,PC将会根据路由器里面的DHCP信息进行自动分配。当然,这样就导致同一个IP地址在不同时间里会有不同的PC使用,如果再做ARP绑定,可能会造成PC无法上网的情况。所以,如果要做ARP绑定,建议使用静态IP地址分配。这样可以防止未添加的PC加入网络。
路由器的IP带宽控制指的是通过IP地址来控制带宽,和ARP绑定不是同一个东西。
ISO的七层模型是什么?TCP/UDP属于哪一层?TCP/UDP有什么优缺点?
应用层
表示层
会话层
运输层
网络层
物理链路层
物理层
tcp /udp属于运输层
TCP 服务提供了数据流传输、可靠性、有效流控制、全双工操作和多路复用技术等。
与 TCP 不同, UDP 并不提供对 IP 协议的可靠机制、流控制以及错误恢复功能等。
由于 UDP 比 较简单, UDP 头包含很少的字节,比 TCP 负载消耗少。
tcp: 提供稳定的传输服务,有流量控制,缺点是包头大,冗余性不好,开销大,实时性较差。
udp: 包头小,开销小 ,占用资源少,实时性较好,缺点是不可靠。
tcp是面向连接的可靠字节流
udp是无连接的不可靠报文传递
已知一个数组table,用一个宏定义,求出数据的元素个数
#define size(array) sizeof(array)/sizeof(array[0]) sizeof(array)就是求整个数组的大小,sizeof(array[0])就是求第一个元素的大小,整个大小除第一个元素的大小就是个数了
用C语言的switch语句和整除试编写一个程序,输入今天是星期几,计算并输出100天后是星期几.
#include"stdio.h"char xq[7][10]={"星期一","星期二","星期三","星期四","星期五","星期六","星期日"};void get_result(int day){int day_after100;//用来保存100后是星期几day_after100=(day-1+100%7)%7;//计算100天后是星期几printf("100天后是:%sn",xq[day_after100]);//输出结果}void main(){int day;printf("今天是星期几:");scanf("%d",&day);while(day<1||day>7){printf("必须是1至7之间的一个数,请重新输入:");scanf("%d",&day);}//当输入的数据不满足规则时,循环输入直到满足规则为止get_result(day);} 什么是预编译
1,宏替换
2,条件编译
3,去掉注释
4,头文件包含
字节序判断 什么是大端序和小端序
数据的存储方式不一样,大端是高位低字节,低位高字节,小端是低位低字节,高位高字节,既大端序高位先存,小端序低位先存。
采用大小模式对数据进行存放的主要区别在于在存放的字节顺序,大端方式将高位存放在低地址,小端方式将低位存放在高地址。采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。到目前为止,采用大端或者小端进行数据存放,其孰优孰劣也没有定论。
交换两个变量的值,不使用第三个变量,即a=3,b=5,交换之后,a=5,b=3
``
a=a+b; //这个得到的是a和b的和;也就是这一步运行之后当前的a的值就是a,b之和。
b=a-b;//既然a是他们两个的和,那么a-b得出的肯定是最初的a的值;这一步运行之后,b的只就是原始a的值;
a=a-b;//既然b是原始a的值,a是原始a和原始b的和,那么差值肯定就是原始b的值。
如何引用一个已经定义过的全局变量
用extern关键字
头文件包含
可以在不同的C文件中声明同名的全局变量,前提是其中只能有一个C文件中对此变量赋初值,此时连接不会出错。
可以用引用头文件的方式,也可以用extern关键字的方式来引用定义过的全局变量
如果用引用头文件方式来引用某个在头文件中声明的全局变理,假定你将那个变量写错了,那么在编译期间会报错。
全局变量可不可以定义在可被多个.c文件包含的头文件中,为什么
可以,在不同的C文件中以static形式来声明同名全局变量。
可以在不同的C文件中声明同名的全局变量,前提是其中只能有一个C文件中对此变量赋初值,此时连接不会出错
** switch()中不允许的数据类型有**
- char、short、int、long、bool 基本类型都可以用于switch语句。
- float、double都不能用于switch语句。
- enum类型,即枚举类型可以用于switch语句。
- 所有类型的对象都不能用于switch语句。
- 字符串也不能用于switch语句
6.布尔类型是可以按整数形式转换的。
case标签必须是整型常量表达式
请记住整型常量这四个字,不满足这个特性的不能作为case值,编译会报错。这也决定了switch的参数必须是整型的。 整型,意味着浮点数是不合法的,如case 3.14:不可以;常量,意味着变量是不合法的,如case ival: ival不能是变量。 (1)C++中的const int,注意仅限于C++中的const,C中的const是只读变量,不是常量; (2)单个字符,如case 'a': 是合法的,因为文字字符是常量,被转成ASCII码,为整型; (3)使用#define定义的整型,#define定义的一般为常量,比如#define pi 3.14,但是也必须是整型才可以; (4)使用enum定义的枚举成员。因为枚举成员是const的,且为整型。如果不手动指定枚举值,则默认枚举值为从0开始,依次加1

 举报
举报




