前 言本文主要介绍HLS案例的使用说明,适用开发环境:Windows 7/10 64bit、Xilinx Vivado 2017.4、Xilinx Vivado HLS 2017.4、Xilinx SDK 2017.4。
Xilinx Vivado HLS(High-Level Synthesis,高层次综合)工具支持将C、C++等语言转化成硬件描述语言,同时支持基于OpenCL等框架对Xilinx可编程逻辑器件进行开发,可加速算法开发的进程,缩短产品上市时间。
本次案例用到的是创龙科技的TLZ7x-EasyEVM-S
开发板,它是一款基于Xilinx Zynq-7000系列XC7Z010/XC7Z020高性能低功耗处理器设计的异构多核SoC评估板,处理器集成PS端双核ARM Cortex-A9 + PL端Ar
tix-7架构28nm可编程逻辑资源,评估板由核心板和评估底板组成。核心板经过专业的
PCB Layout和高低温测试验证,稳定可靠,可满足各种工业应用环境。
TLZ7x-EasyEVM-S评估板
TLZ7x-EasyEVM-S评估板评估板接口资源丰富,引出千兆网口、双路CAMERA、USB、Micro SD、CAN、UART等接口,支持LCD显示拓展及Qt图形界面开发,方便快速进行产品方案评估与技术预研。
matrix_demo案例
案例功能:实现32*32浮点矩阵乘法运算功能,同时提供提高运算效率的方法。
HLS工程说明
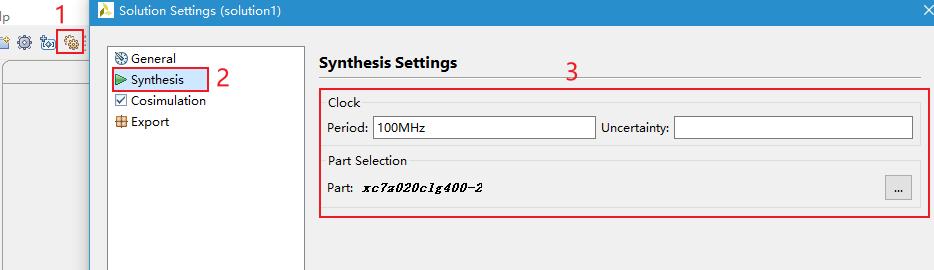
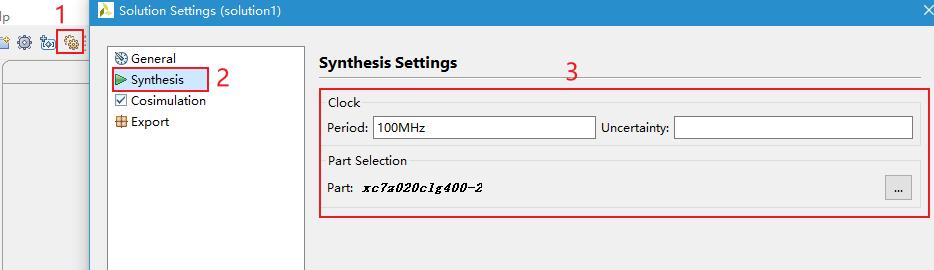
HLS工程配置的时钟为100MHz。如需修改时钟频率,请打开HLS工程后点击后,在弹出的界面中的Synthesis栏目进行修改。
图 42
(2)顶层函数
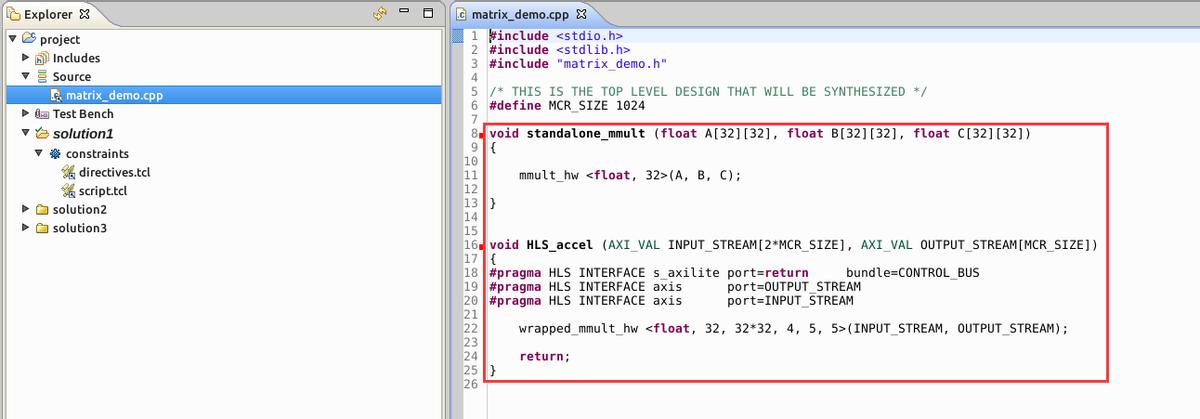
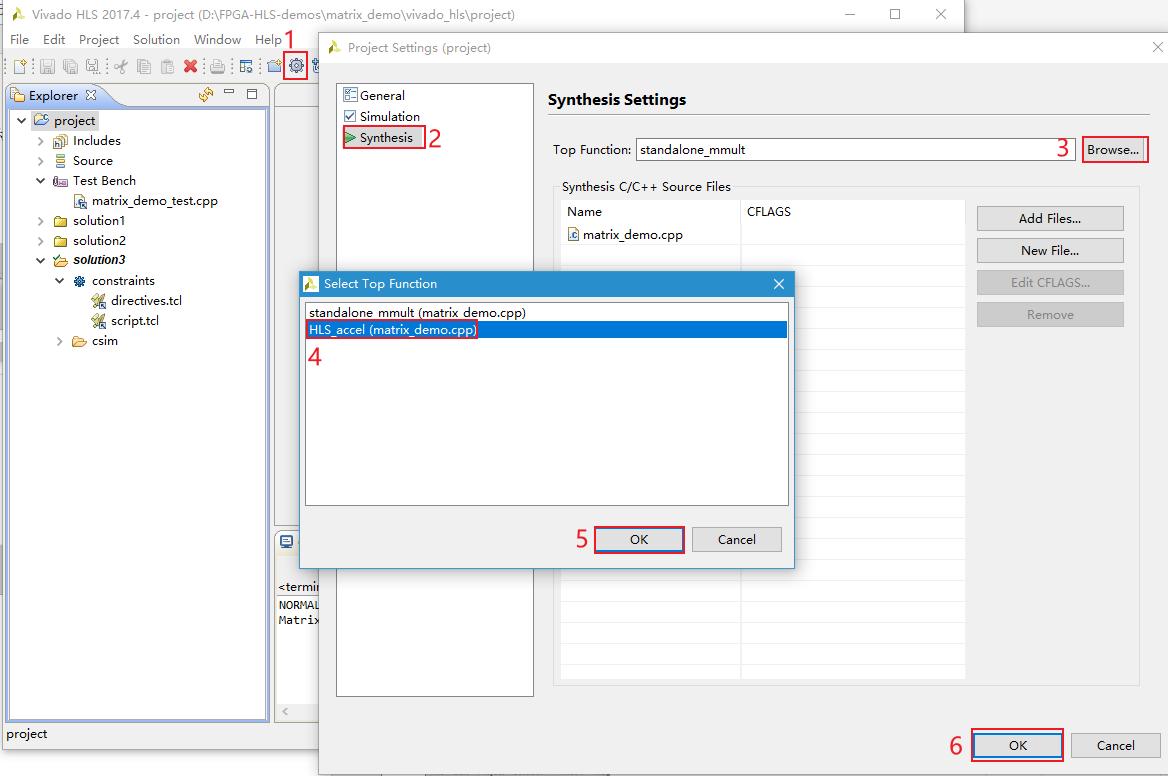
案例有两个可选的顶层函数,分别为standalone_mmult()和HLS_accel()。前者为矩阵乘法运算函数,用于
仿真阶段;后者基于前者将数据输入输出接口封装成AXI4-Stream接口,用于综合阶段。工程默认配置为standalone_mmult()。
图 43
点击后矩阵乘法运算函数如下:
图 44
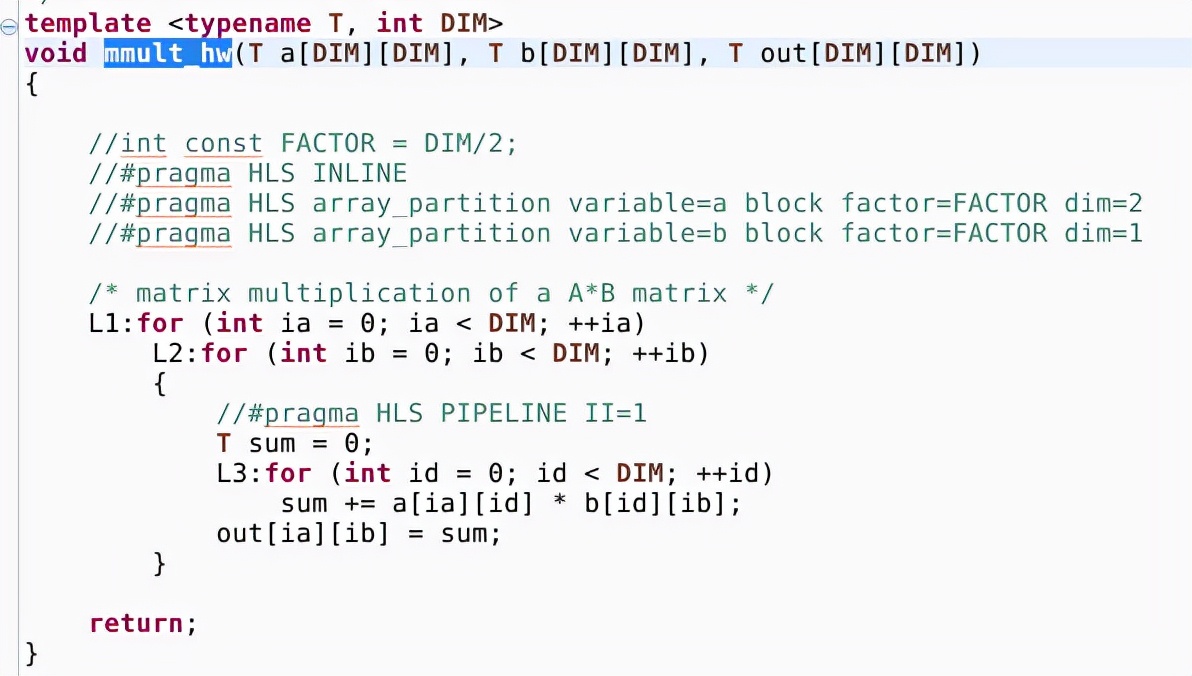
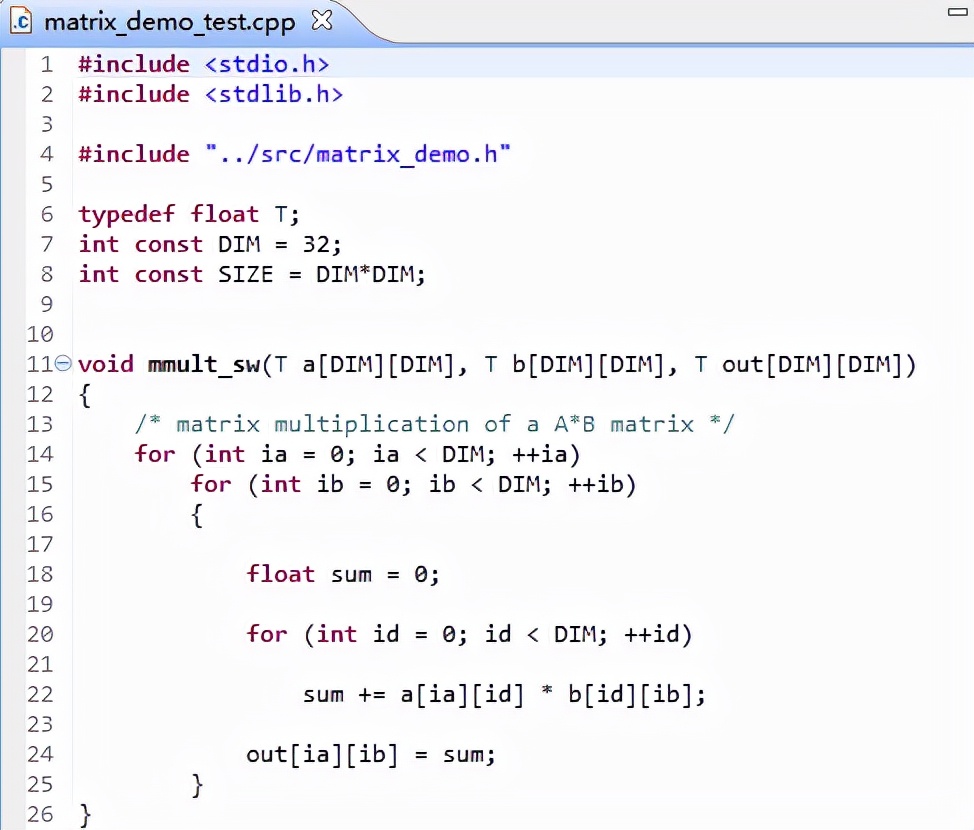
矩阵乘法运算函数如下:
图 45
matrix_demo_test.cpp中提供了矩阵乘法运算函数mmult_sw(),程序将mmult_sw()的运算结果和顶层函数standalone_mmult()的运算结果进行对比。如结果一致,则说明顶层函数逻辑正确。mmult_sw()函数不调用逻辑资源,而standalone_mmult()函数调用逻辑资源。
图 46
图 47
编译与仿真请参考本文档HLS开发流程说明章节,进行编译。编译完成后,进入仿真界面点击综合
图 48
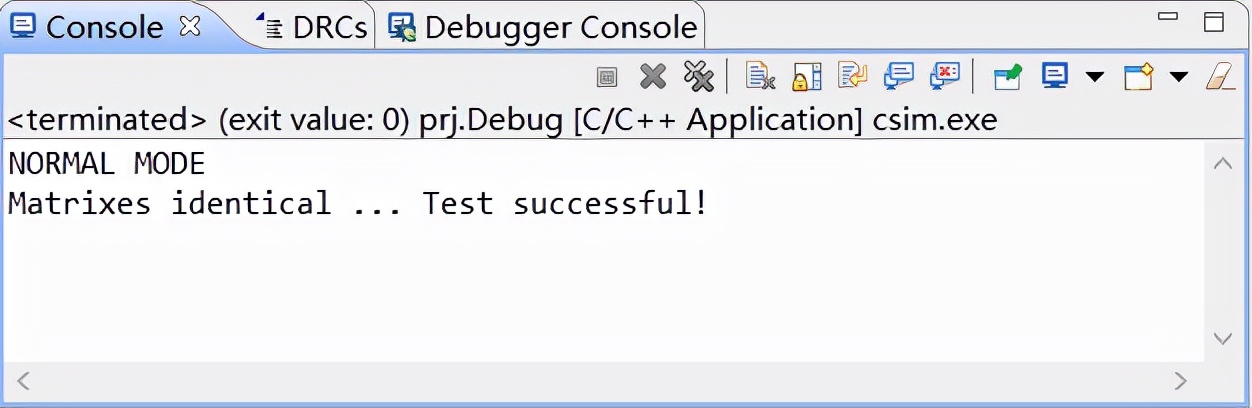
运行完毕后,将在Console窗口打印如下提示信息,说明顶层函数逻辑正确。
图 49
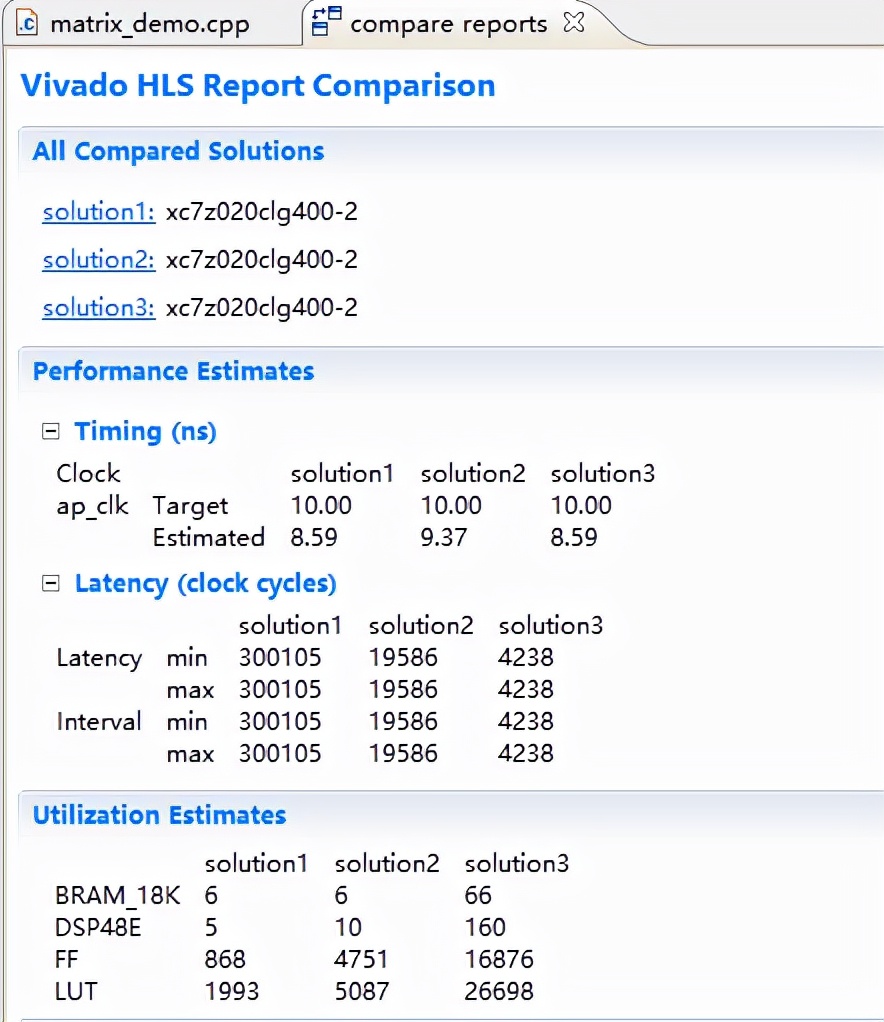
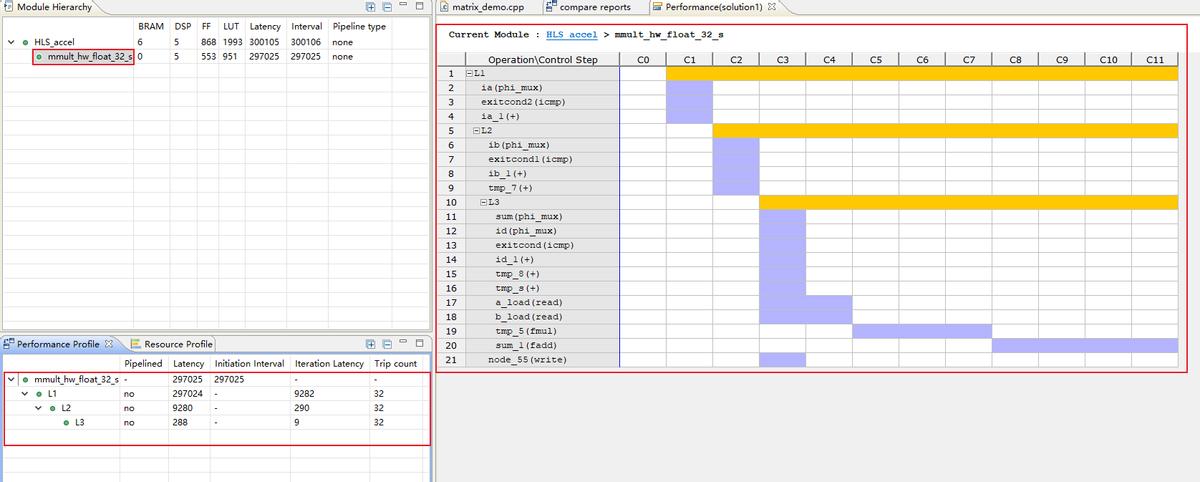
综合案例提供三个solution,每个solution的算法运行效率不同。由于solution3所用资源较多,xc7z010无法满足资源要求,因此案例默认使用solution2生成IP核。
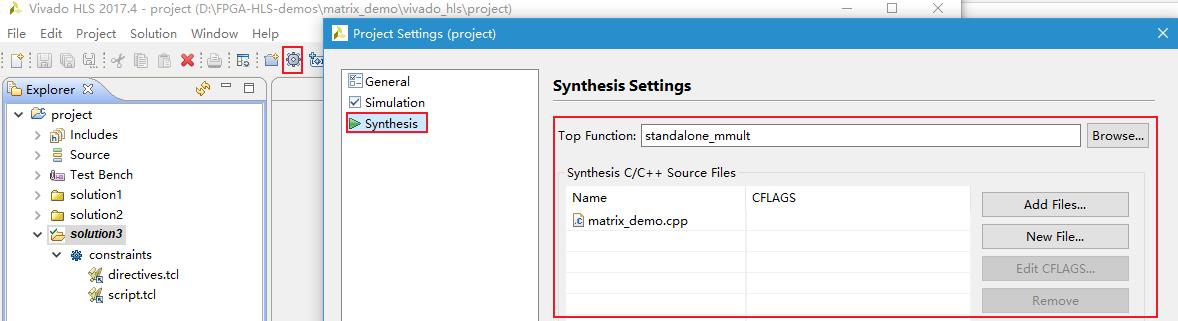
进行综合时,需将顶层函数修改为HLS_accel()。修改顶层函数后请点击。
图 50
图 51
综合完成后,可看到三个solution的详细信息。
图 52
从上图可看出solution3的运行效率最高,但消耗资源最多。
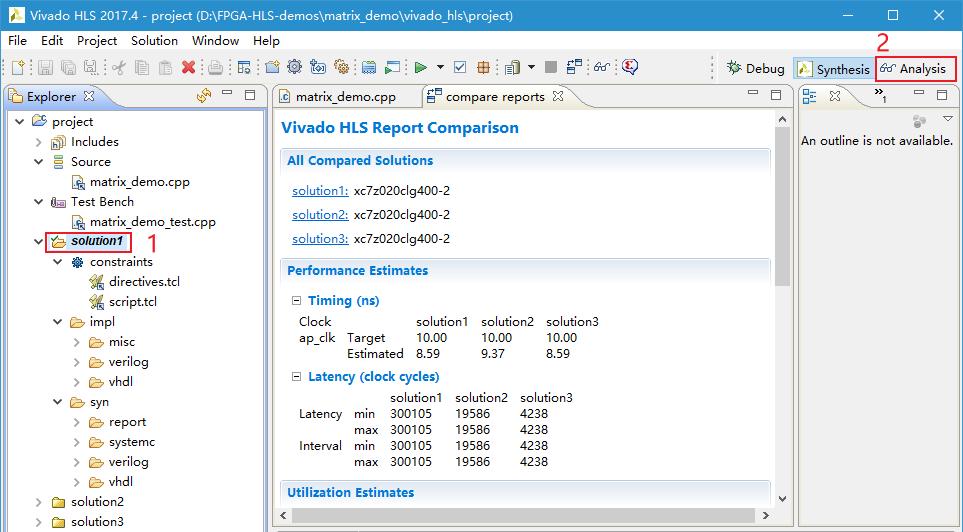
双击选中solution1,然后点击Analysis。
图 53
图 54
可看到矩阵乘法运算函数里的三个for循环均为顺序运行,因此耗时最长。
2.solution2分析
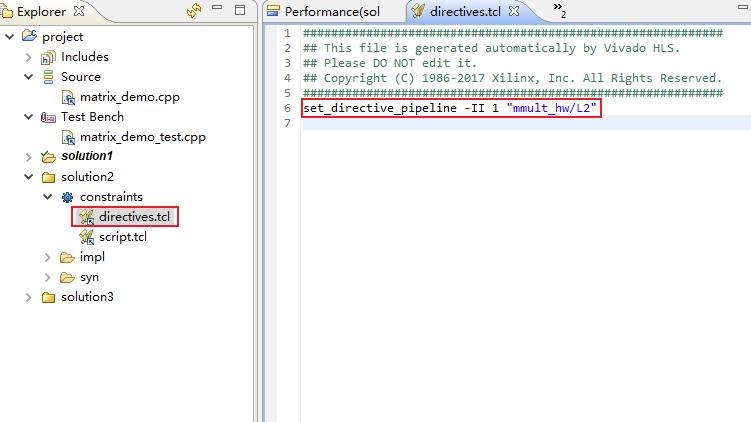
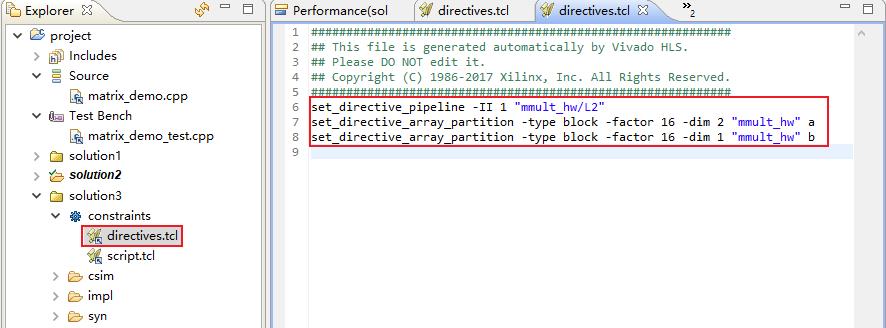
双击打开solution2的directives.tcl,可看到下图语句。
图 55
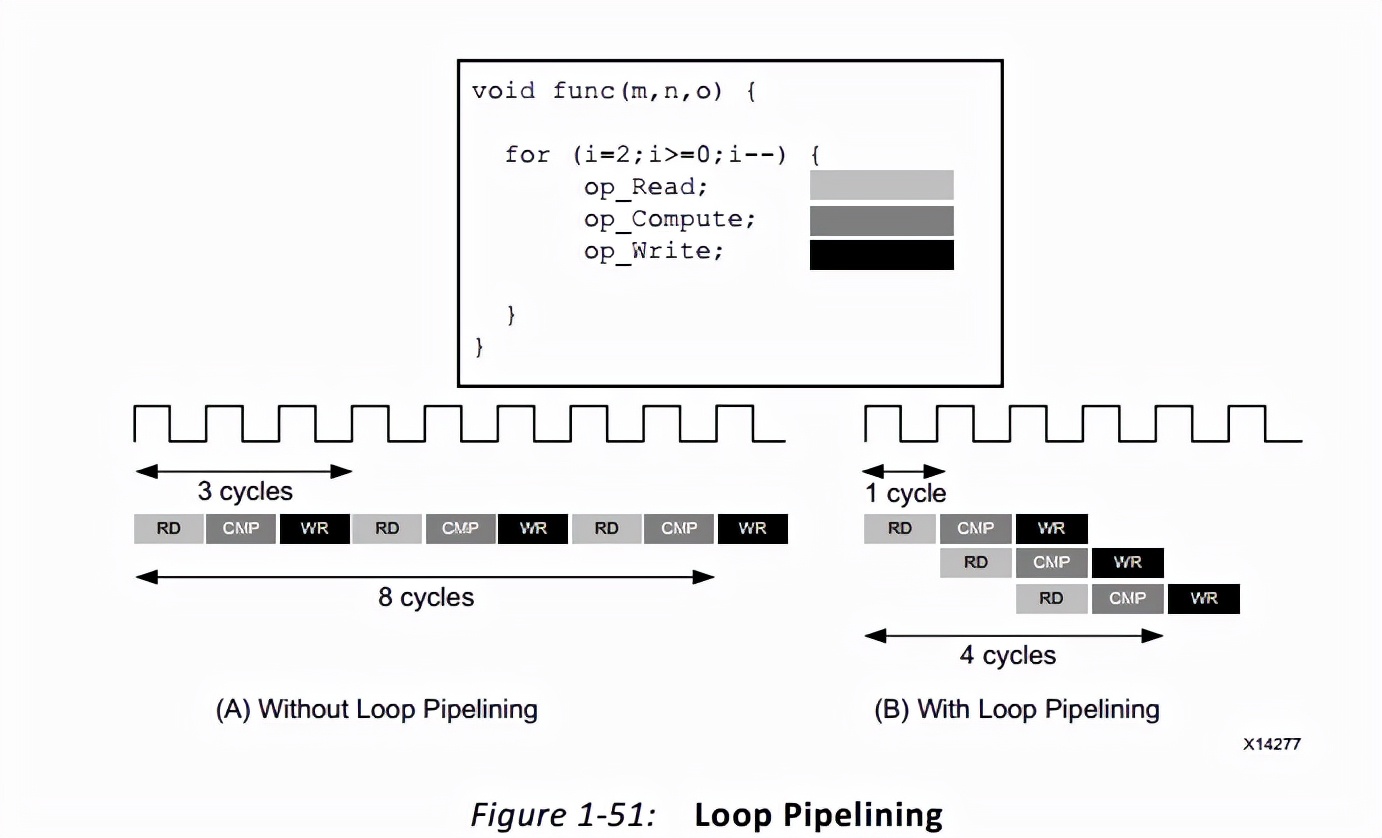
PIPELINE的作用是允许在函数中并发执行操作,减少函数运行时间。
图 56
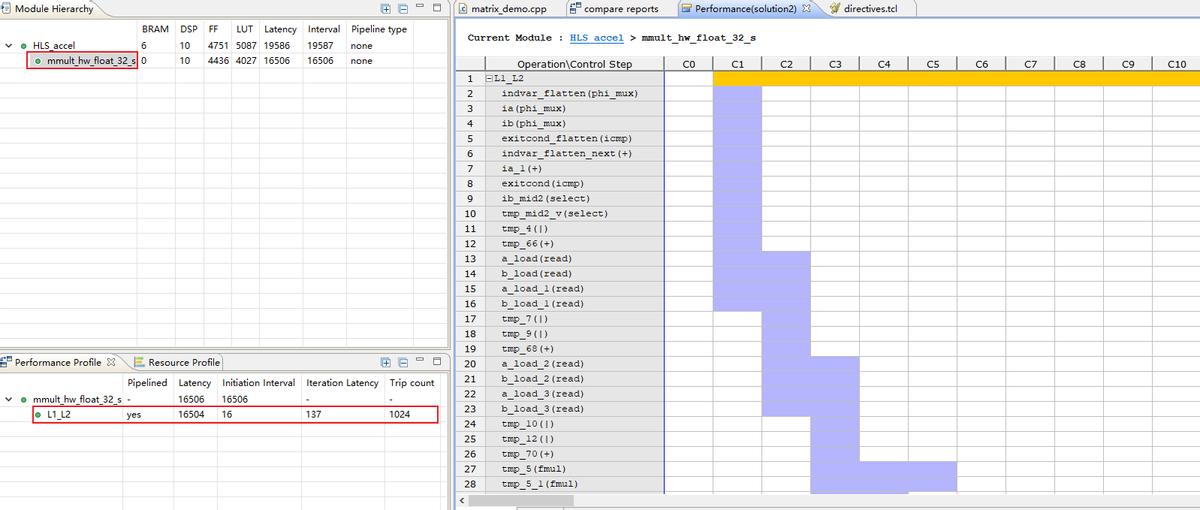
solution2将mmult_hw()的L2 for循环进行了PIPELINE优化。打开solution2的Analysis,可看到矩阵乘法运算函数里的L1/L2 for循环并行执行,因此耗时较短。
图 57
3.solution3分析
双击打开solution3的directives.tcl,可看到下图语句。
图 58
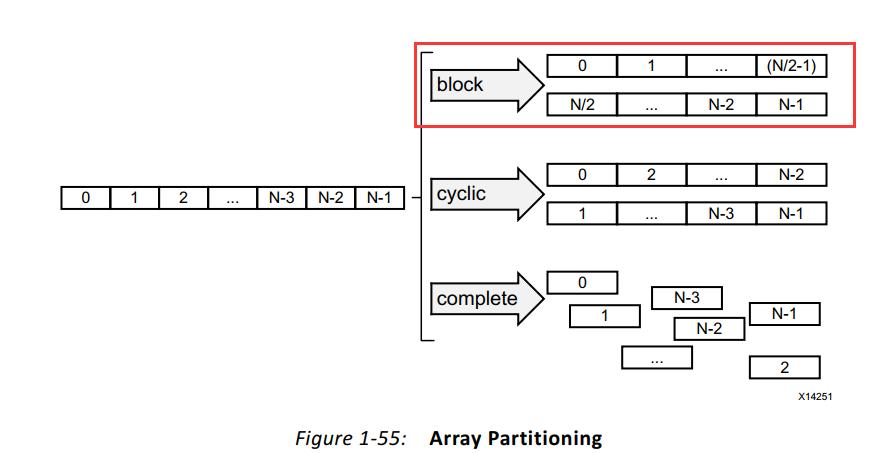
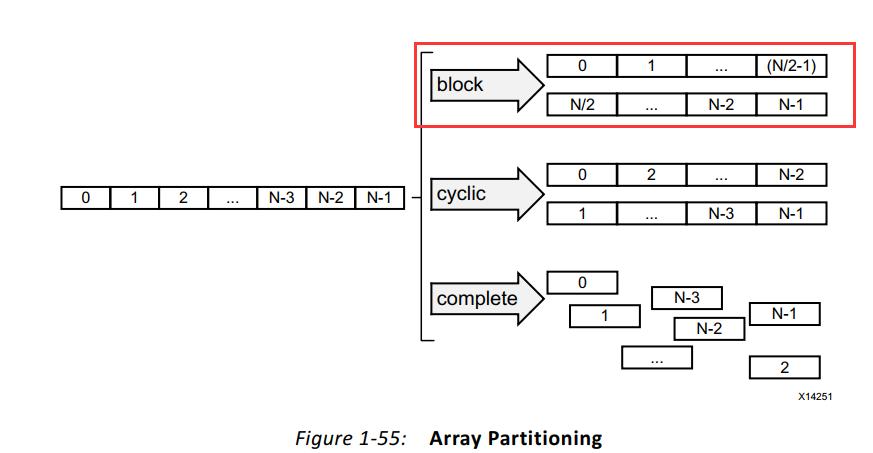
ARRAY_PARTITION指令的作用是将大数组划分为多个小数组或单独的寄存器,以提高对数据的访问效率。
图 59
solution3在solution2的基础上,使用了ARRAY_PARTITION指令将函数mmult_hw()的数组a、b分别分拆为16个数组,增加了数据吞吐量,提高了运算效率。
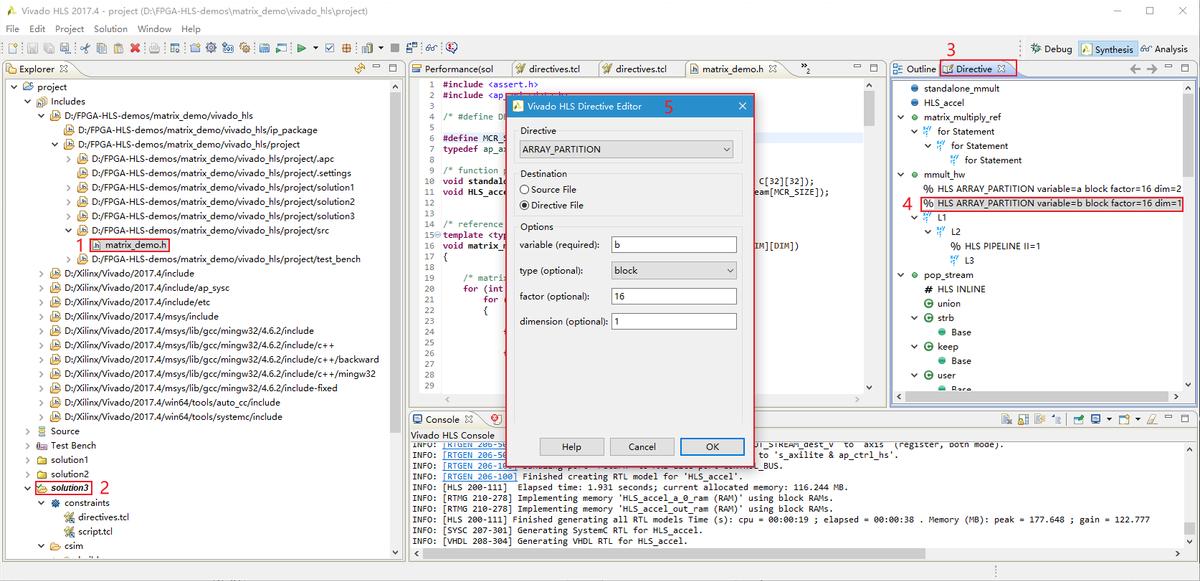
打开头文件matrix_demo.h,然后双击选中solution3打开工程Directive,可对编译指令进行修改或优化。
图 60
IP核测试请参考本文档HLS开发流程说明章节,完成IP核测试前的准备工作。
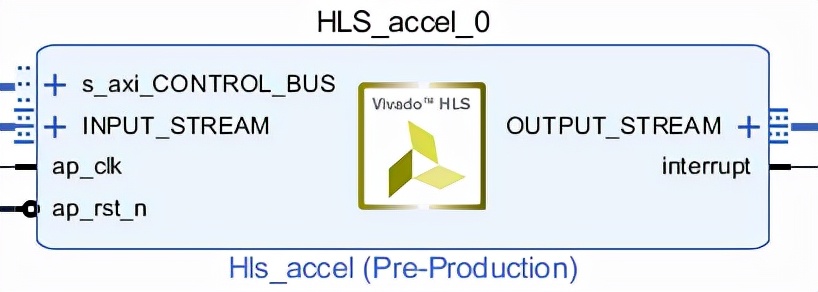
HLS工程生成的IP核为HLS_accel_0。
图 61
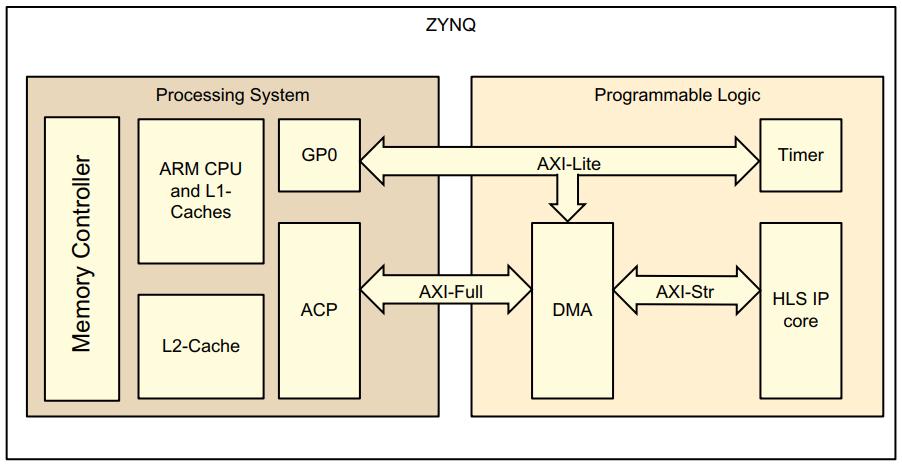
PL端IP核测试Vivado工程说明浮点矩阵乘法运算加速器IP核通过AXI DMA IP核连接到PS端ACP接口,从而连通到PS端L2缓存。ACP为64位AXI从接口,它提供了一个异步缓存相关接入点,实现了PS和PL端加速器之间的低延迟路径。
AXI Timer IP核用于计数,可通过其寄存器来计算浮点矩阵乘法运算加速器IP核的运算时间。
图 62
PS端IP核测试裸机工程说明PS端运行32*32的浮点矩阵乘法运算,并将PS端和PL端用时进行比较。PL端的浮点矩阵乘法运算用时从AXI Timer IP核中读取。
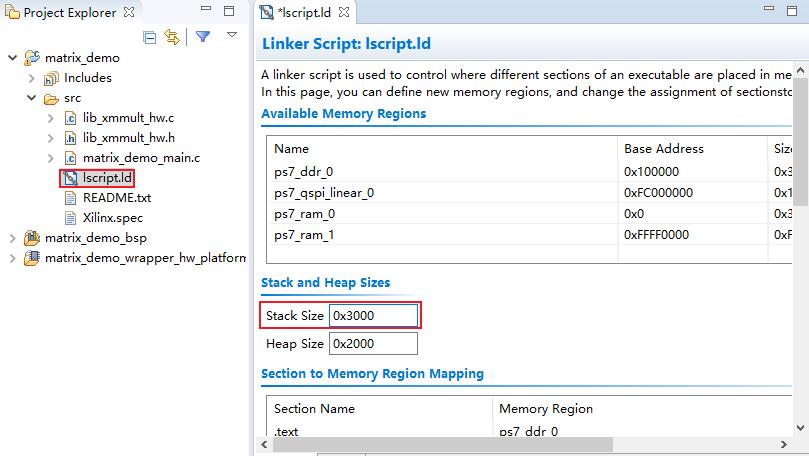
打开裸机工程,确保lscript.ld文件的“Stack Size”为0x3000,然后进行编译。
图 63
图 64
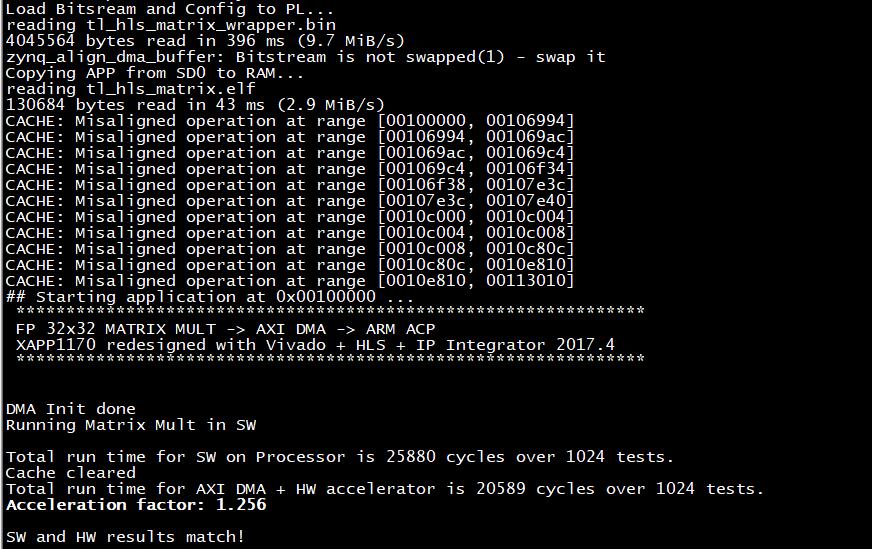
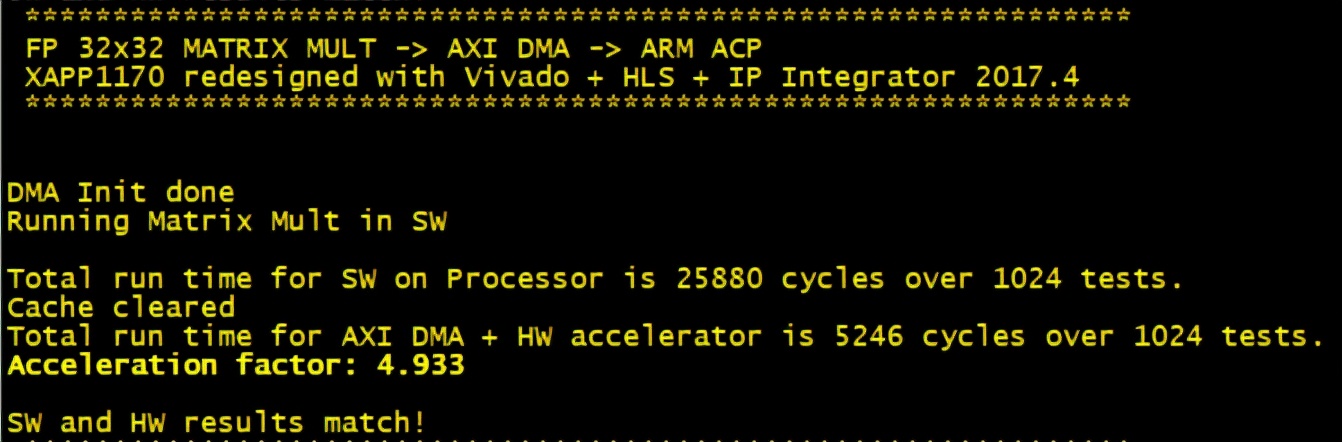
测试说明参考PS端裸机与FreeRTOS案例开发手册说明,加载PS端裸机.elf格式可执行文件、PL端.bit格式可执行文件后,即可看到PS端串口调试终端打印如下信息。
可看出PS端执行矩阵乘法运算消耗了25880个时钟,PL端(solution2)消耗了20587个时钟,PL端运行效率为PS端的1.256倍。
图 65
若使用solution3生成的IP核,PL端消耗了5246个时钟,PL端运行效率为PS端的4.933倍。
图 66
sobel_demo案例案例功能:对YUV格式视频进行Sobel(边缘检测)算法处理。
Sobel详细开发说明可参考产品资料“6-开发参考资料Xilinx官方参考文档”目录下的如下文档。
- xapp1167.pdf
- xapp890-zynq-sobel-vivado-hls.pdf
HLS工程说明
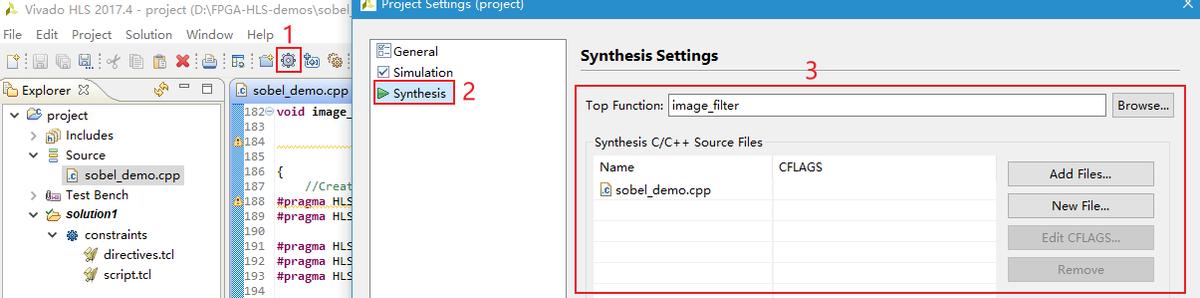
HLS工程配置的时钟为100MHz。如需修改时钟频率,请打开HLS工程后点击,在弹出的界面中的Synthesis栏目进行修改。
图 67
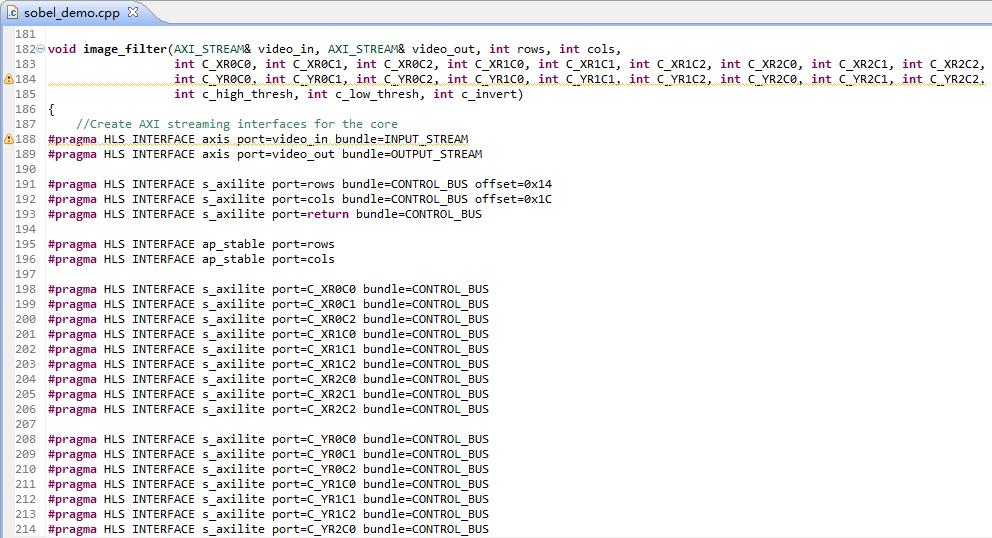
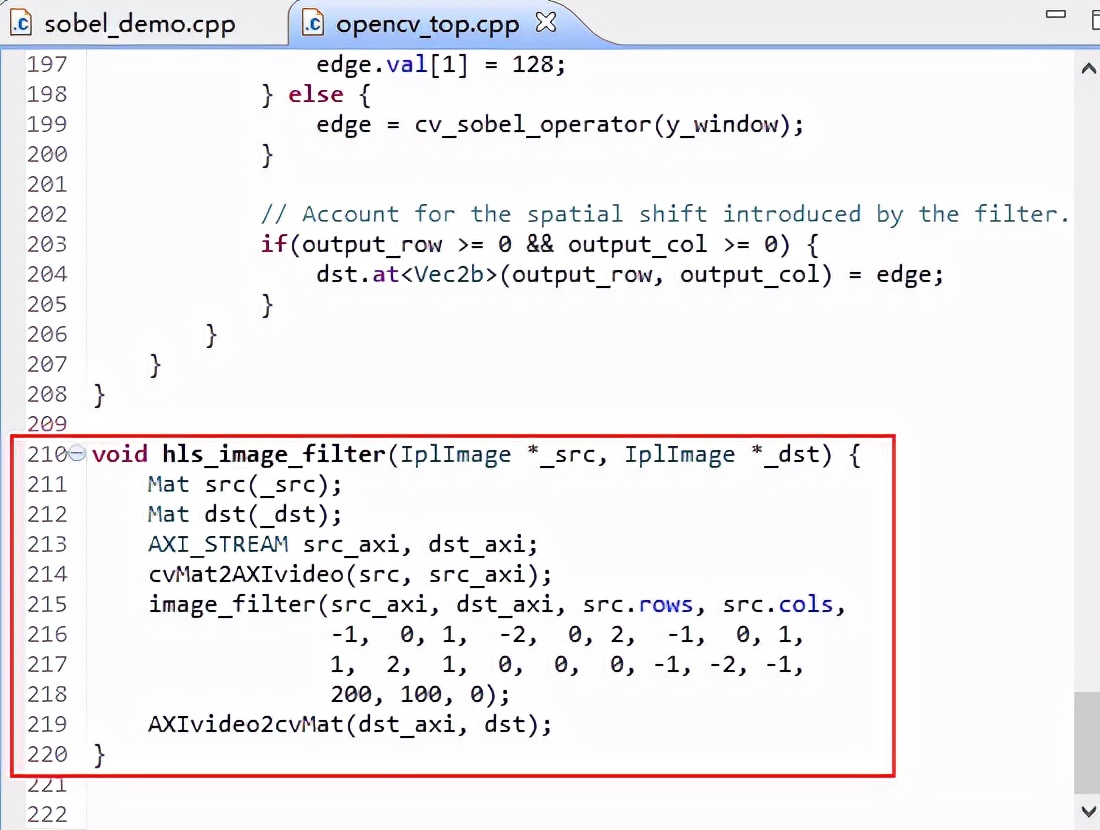
案例顶层函数为opencv_top.cpp中的hls_image_filter()。首先在sobel_demo.cpp中调用image_filter(),最终调用opencv_top.cpp中的顶层函数hls_image_filter()。
图 68
图69
点击后,可在弹出的界面中的Synthesis栏目查看或设置顶层函数。
图 70
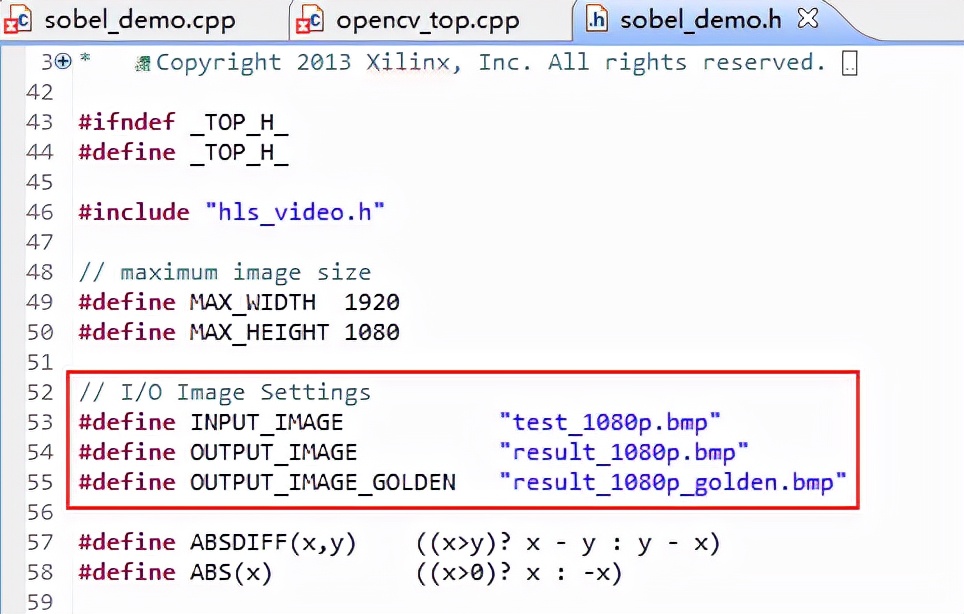
输入输出图像在sobel_demo.h中已定义,分辨率均为1920*1080。
图 71
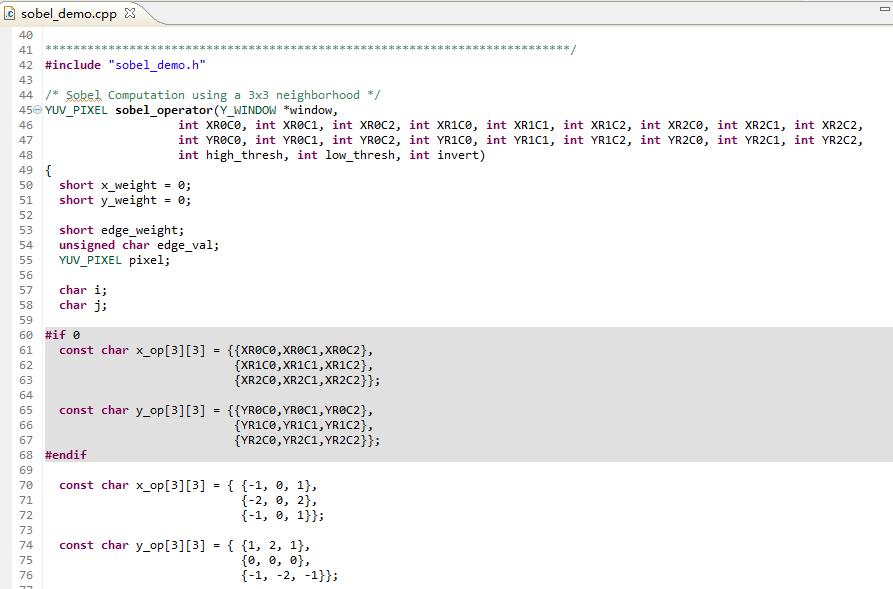
Sobel算子在sobel_demo.cpp中已定义。
图 72
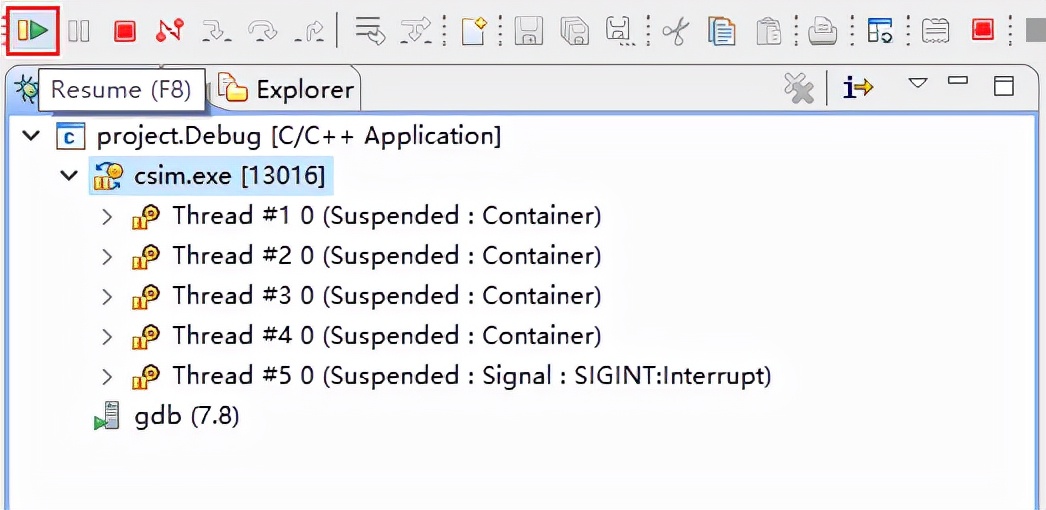
编译与仿真请参考本文档HLS开发流程说明章节,进行编译。编译完成后,进入仿真界面点击进行全速运行。
运行完毕后,将在Console窗口打印如下提示信息,说明顶层函数逻辑正确。
图 73
图 74
同时得到经过hls_image_filter()和opencv_image_filter()函数处理的图片。
程序将opencv_image_filter()的运算结果和顶层函数hls_image_filter()的运算结果进行对比。如结果一致,则说明顶层函数逻辑正确。opencv_image_filter()函数不调用逻辑资源,而hls_image_filter()函数调用逻辑资源。
图 75 hls_image_filter()处理结果
图 76 opencv_image_filter()处理结果
图 77 原始图像
IP核测试请参考本文档HLS开发流程说明章节,完成IP核测试前的准备工作。
HLS工程生成的IP核为image_filter_0。
图 78
由于产品资料“4-软件资料DemoAll-Programmable-SoC-demos”目录下的camera_edge_display案例使用到本案例IP核,因此请参考PS + PL异构多核案例开发手册的camera_edge_display案例说明进行IP核测试。