简而言之,许多领域都可以从事件抽取技术和系统的进步中受益。
尽管有很好的应用前景,但事件提取仍然是一项相当具有挑战性的任务,因为事件具有不同的结构和组件;而自然语言往往存在语义歧义和语篇风格。此外,事件抽取也与其他NLP任务密切相关,如命名实体识别(NER)、词性标注(POS)、语法解析等,这些任务的执行方式和输出结果可能会促进事件抽取,也可能会对其性能产生负面影响。为了促进事件抽取的发展和应用,人们开展了许多公开评估计划,提供任务定义、标注语料库和公开竞赛,以促进事件抽取等信息抽取研究,这些研究也吸引了许多人才贡献新的算法、技术和系统。下面我们简单介绍一下这些知名的节目。
A. 公开评估项目
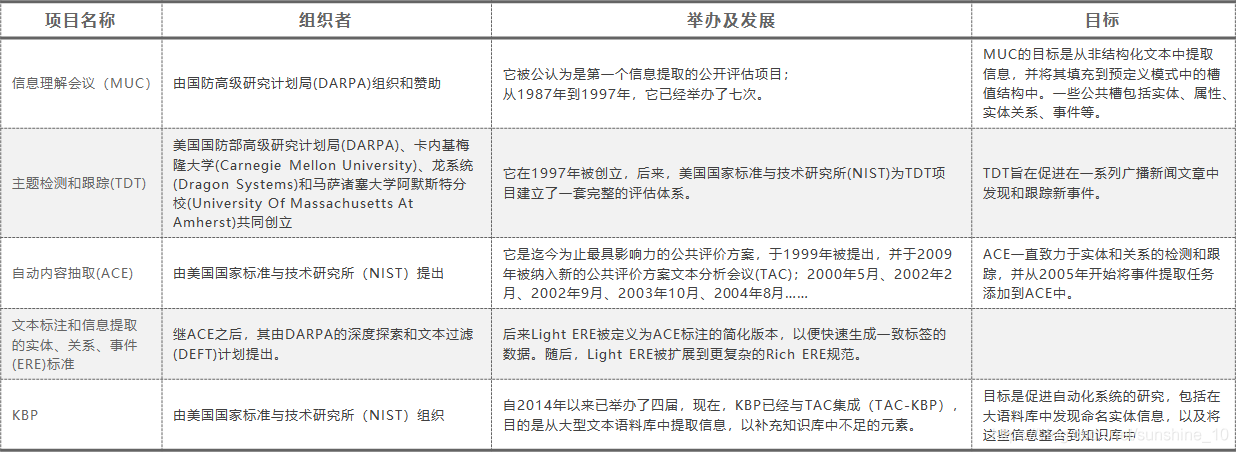
1997年,美国国防部高级研究计划局(DARPA)、卡内基梅隆大学(Carnegie Mellon University)、龙系统(Dragon Systems)和马萨诸塞大学阿默斯特分校(University Of Massachusetts At Amherst)共同创立了另一个公共评估项目,名为主题检测和跟踪(TDT),以促进在一系列广播新闻文章中发现和跟踪新事件。后来,美国国家标准与技术研究所(NIST)为TDT项目建立了一套完整的评估体系。
需要注意的是,同一事件可能在不同的句子或文档中被多次提及。如何区分同一事件的多个事件提及属于另一个关键的自然语言处理任务,称为事件共指。在本文中,我们不考虑事件提及共同参考解决方案。
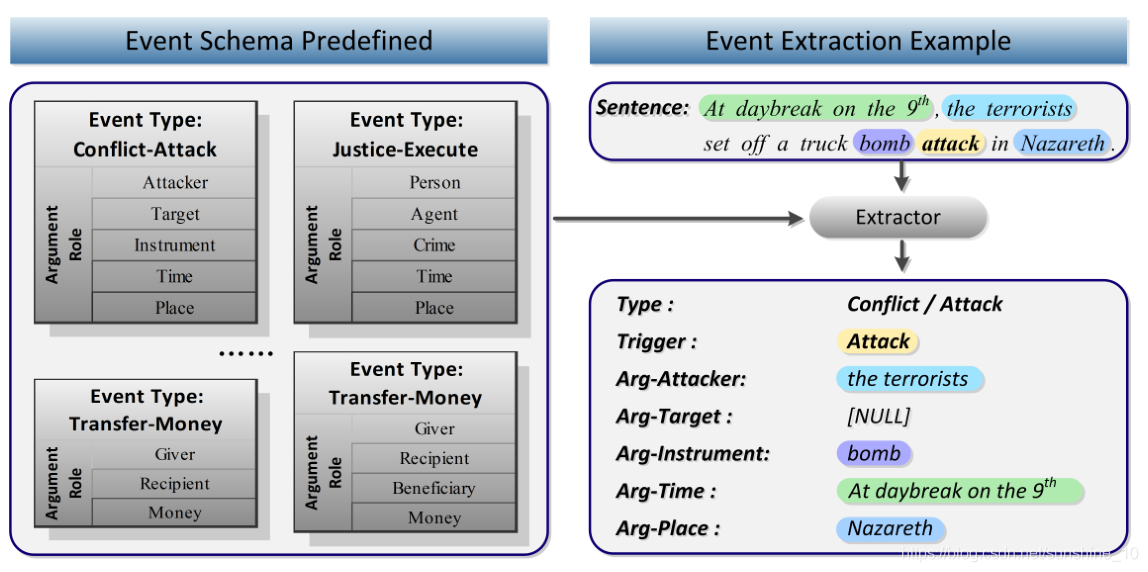
Ahn 首先提出将ACE事件提取任务分为四个子任务:触发器检测、事件/触发器类型识别、事件论元检测、论元角色识别。例如,考虑以下句子:
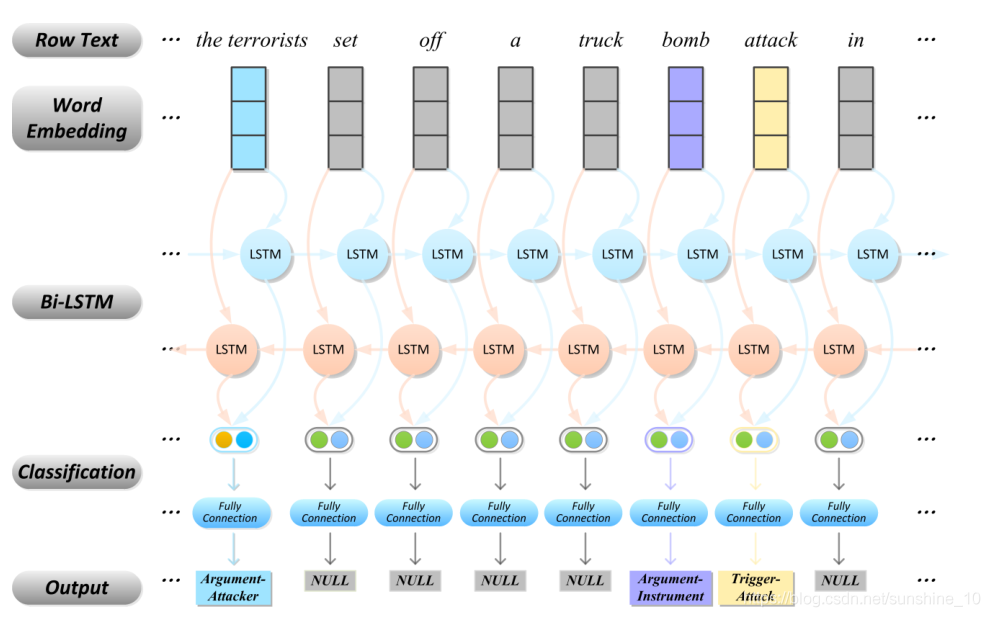
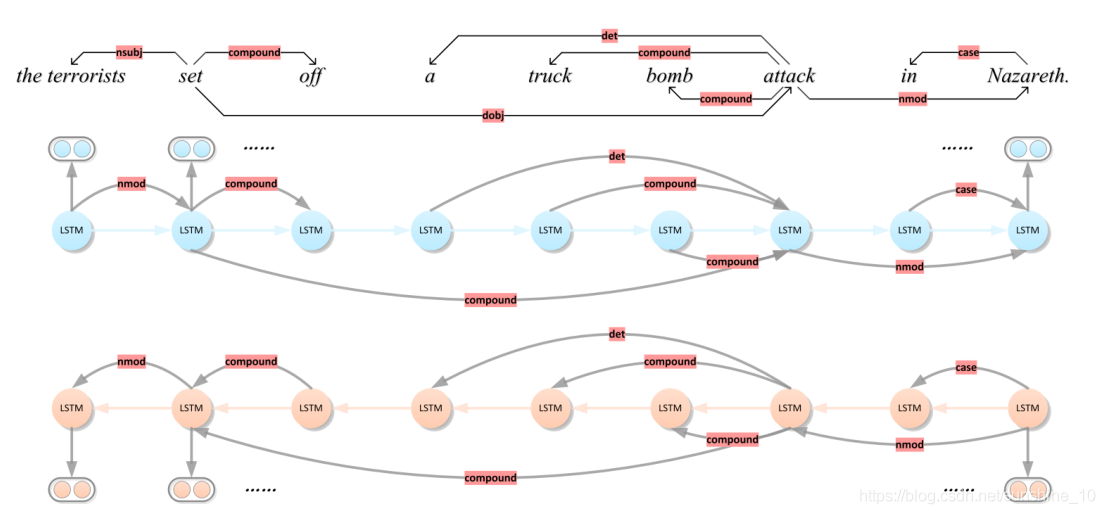
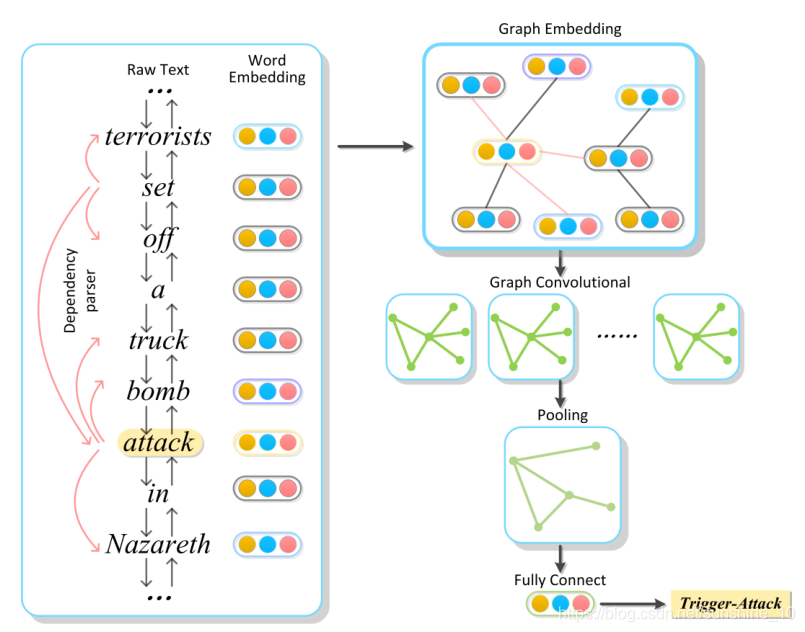
sentence 1:At daybreak on the 9th, the terrorists set off a truck bomb attack in Nazareth.
句子1:9日黎明时分,***在拿撒勒发动了一场卡车炸弹袭击。
在此句中存在“Conflict/Attract”事件。事件提取器应该通过检测句子中的触发词“Attract”并将其分类为“Conflict/Attract”事件,接下来,应该从文本中提取与该事件相关的论元,并根据预定义的事件结构标识它们各自的角色。
本部分主要介绍事件抽取任务的语料库资源。通常,公开评测程序为事件抽取的任务评测提供了多个语料库。公共评测程序根据任务定义对语料库进行人工标注,并用于机器学习方法中的模型训练和验证;样本标注由具有领域知识的专业人员或专家完成,标注后的样本可视为带有ground truth标签。然而,由于标注过程成本高昂,许多公共语料库规模较小,覆盖率较低。
A. ACE事件语料库
TAC-KBP中的事件块检测任务专注于检测对事件的明确提及及其在RichERE中定义的类型和子类型。由语言数据联盟(LDC)提供的TAC-KPB 2015语料库包括158个文档作为先前训练集,以及202个附加文档作为正式评估的测试集,这些文档来自新闻报道文章和论坛。
参照ACE语料库,定义了TAC-KBP(Rich Ere)中的事件类型和子类型,包括9种事件类型和38个子类型。此外,事件提及必须被分配到三个真实值中的一个:实际(实际发生)、一般(没有具体的时间或地点)和其他(非一般事件,如失败事件、未来事件和条件语句等)。
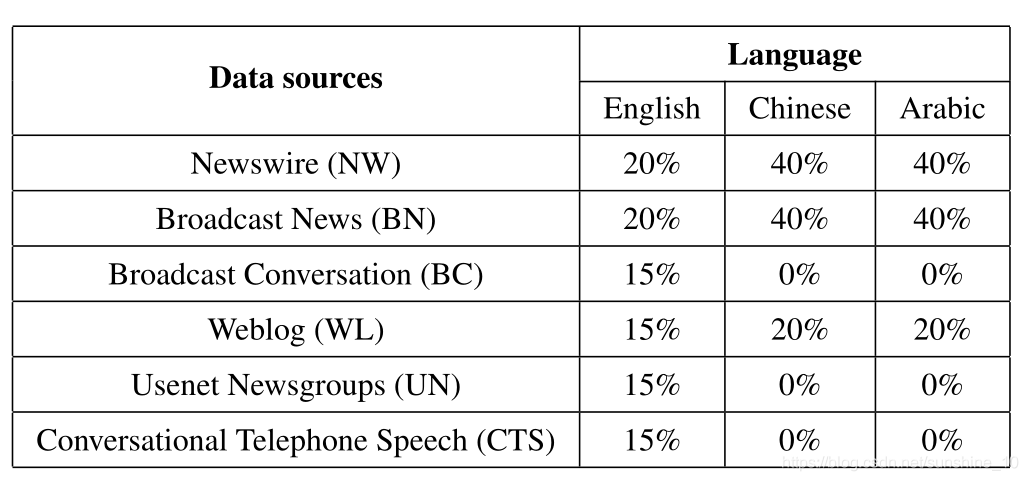
TAC-KBP 2015语料库仅用于英语评估,但在TAC-KBP 2016中为所有任务增加了汉语和西班牙语。
C. TDT语料库
在开放领域事件抽取方面,语言数据联盟LDC还提供了一系列语料库来支持从TDT-1到TDT-5的TDT研究,包括英文和中文的文本和语音(普通话)。
每个TDT语料库包含数百万个新闻故事,用数百个主题(事件)进行标注,这些主题(事件)来自多个来源,如新闻通讯社和广播文章。此外,所有的音频材料都由LDC转换为文本材料。
如果故事讨论的是目标主题,则为这些故事主题标签分配的值为YES;如果讨论的内容占故事的比例不到10%,则为Brief。否则,(默认)标记值为no。
D. 其它特定领域的语料库
语言模式不同于AutoSlog中的事件模式。在人工标注语料库中,利用语言模式自动建立事件模式;而事件模式用于事件提取。此外,AutoSlog被设计为使用单个事件论元提取事件,因此他们的语料库为每个事件都标注了单个论元。
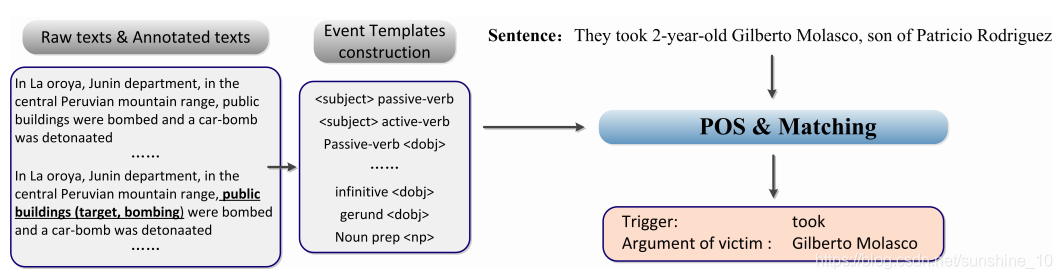
例如,在下面的句子中,划线的短语“public buildings”被标注为为具有“bombing”类型事件的“target”角色的论元。
sentence2:In Laoroya, Junin department, in the central Peruvian mountain range, public buildings (target, bombing) were bombed and a car-bomb was detonated.
句子2:在老罗亚,Junin省,在中部Peruvian山脉,公共建筑(目标,炸弹)被炸,一辆汽车炸弹被引爆。
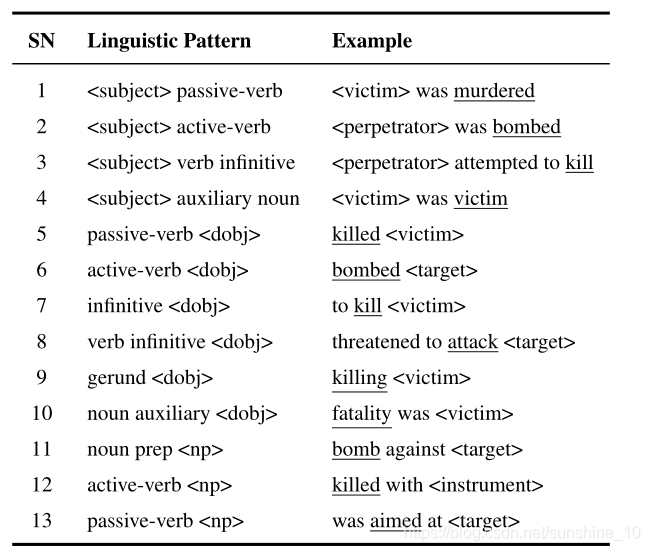
具体地说,AutoSlog使用句法分析器Circle来识别人工标注语料库中每个句子的词性(POS),如主语、谓语、宾语、介词等。随后,AutoSlog生成触发词词典和概念节点,它们可以被视为事件模式,涉及事件触发器、事件类型、事件论元和论元角色。在上句中“public buildings”被CIRCUS认定为主语,因为它后面跟着一个被动动词“bombed”,所以它与预定义的语言模式“passive-verb”相匹配,因此,它将“bombed”添加到触发词字典中,并生成具有轰炸类型的实践模式“was bombed”。在模式匹配(事件抽取)过程中,AutoSlog首先利用触发词词典查找候选事件语句,然后按CIRCUS对候选语句进行词性标注。然后,它将触发词的语法特征(即使用CIRCUS的POS输出)与事件模式向关联,以提取论元及事件角色。对于预定义的具有绑架类型的事件模式“took”,它的触发词“took”将定位候选句子,“they took 2-year-old Gilberto Molasco, son of Patricio Rodriguez”。使用CIRCUS进行词性分析的结果进一步证明了“Giberto Molasco”是DOBJ(直接宾语)。最后结合POS的结果和预定义的事件模式,AutoSlog可以提取绑架类型的事件,及其其触发词“took”和受害者“Gilberto Molasco”的论元。
为了增加可伸缩性,Kim等人设计了并行自动语言知识获取系统PALKA(Parallel Automatic Language Knowledge Acquisition),从标注语料库中自动获取事件模式。他们为事件模式定义了一种专门的表示,称为FP结构(框架-短语和模式结构)。在Palka中,事件模式以FP-Structure的形式构建,并通过语义约束的泛化进一步调整。此外,FP-Structure将单事件论元模式扩展为具有多个论元的事件模式,即一个事件可以包含多个论元。例如句子2中的“bombing”事件,除了“target”论元之外,还可能有多个潜在的事件论元,如“agent”,“patient”,“instrument”和“effect”。此外,PALKA将一句中的多个从句转换为多句形式,用于事件提取。
这两个阶段和四个子任务可以以流水线方式执行,其中多个独立的分类器各自被训练,并且一个分类器的输出也可以作为其后续分类器的输入的一部分。这四个子任务也可以联合执行,一个分类器执行多任务分类,并直接输出多个子任务的结果。
无论是PipeLine执行还是联合执行,学习分类器都需要首先执行一些特征工程工作,即从文本中提取特征作为分类模型的输入。因此,在这一部分中,我们首先介绍一些用于分类器训练的常见特征,然后回顾和比较文献中的流水线和联合分类方法。
A. 学习模型的文本特征
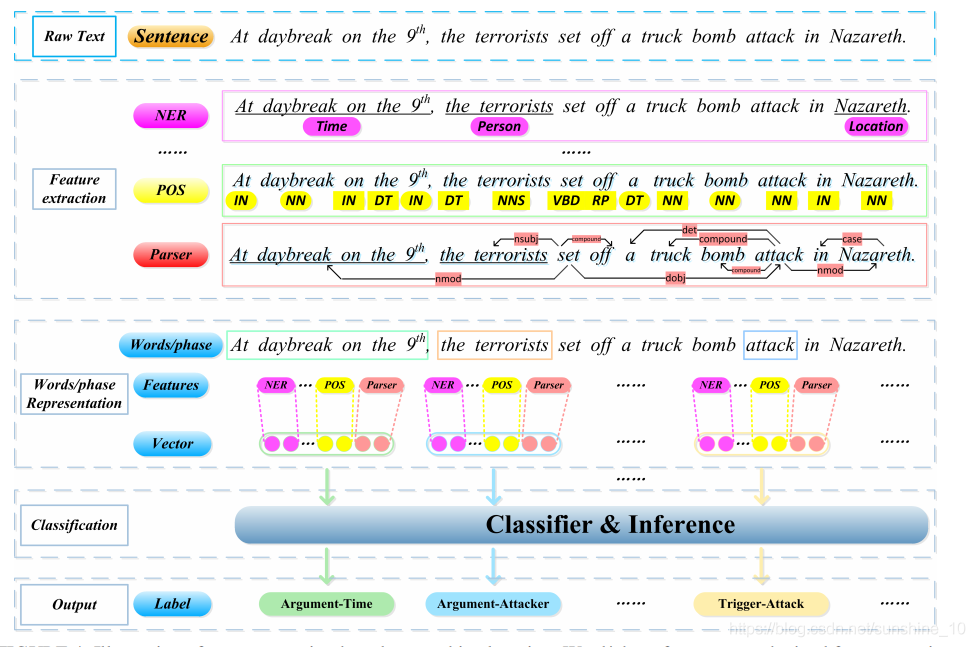
在句子级事件提取中,首先将句子标记为离散的token,然后根据特征工程的结果用特征向量表示每个token。在英语中,token通常是一个单词;然而,在某些语言中,token可以是一个字符或多个字符,也可以是一个单词或短语。分类器从语料库中带标记的文本进行训练,然后用于确定某个token是否为触发词(或事件论元)及其事件类型(或论元角色)。
David Ahn[27]提出了一个典型的PipeLine处理框架,由两个连续的分类器组成:第一个分类器TimBL采用最近邻学习算法检测触发器;第二个分类器MegaM采用最大熵学习器来识别论元。为了训练TimBL分类器,使用了词法特征、WordNet特征、上下文特征、依存特征和相关实体特征;使用触发词、事件类型、实体提及、实体类型、触发词与实体之间的依存路径等特征训练MegaM分类器。已经提出了许多不同的pipeline分类器,它们通过不同类型的特征进行训练。例如Chieu和Ng加入unigram、bigram等特征,采用最大熵分类器。在生物医学领域,更多特定领域的特征和专业知识被用于分类器训练,如频率特征、token特征、路径特征等。
一些研究者提出将模式匹配集成到到机器学习框架中。如前所述,事件模式可以提供更精确的事件结构,其中包含某些特定触发器及其关联论元之间的显式关系,尽管这种关系是人工设计的,没有太多的可扩展性。Grishman等人提出先进行模式匹配,预先分配一些潜在的事件类型,然后使用分类器识别剩余的事件提及。这两种方法在增强事件提取方面是相辅相成的。此外,在机器学习分类器检测到触发器后,也可以执行模式匹配。由于事件论元与触发器类型密切相关,因此应用一些良好的触发器-论元关系有助于改进论元识别。此外,事件模式也可以与token特征合并,作为机器学习分类的输入。
如事件标注事例图所示,在一些语言(如英语)中,句子token化是一项简单的任务,因为单词是由分隔符显式分隔的。然而,在其他一些语言中,如汉语和日语,句子由连续的字符组成,而不使用分隔符来分隔单词。因此,分词通常需要首先将一个句子分成许多离散的token(词/词)。由于分词可以独立于事件提取任务实现,如果有分词错误,则会传播到下游任务,降低其性能。此外,由于自然语言的多义性,在分词后,一个词很可能包含两个或两个以上的触发器;而触发器被分为两个或两个以上的单词。
为了解决这类标记化问题,Zhao等人提出,对于分句后的每个单词,首先从同义词字典中获取每个潜在触发器及其对应的事件类型。Chen和Ji提出同时使用词语级和字符级触发器标注策略。此外,他们提出使用字符级token(包括当前字符、前一个字符和下一个字符等)训练最大熵马尔科夫模型分类器用于触发检测。Li等人利用内部触发语的成分语义和触发词之间的语篇一致性来增强中文触发语的识别能力。具体来说,如果一个动词词的组成部分(一个或多个汉字)被标记为中文触发器,那么它就是一个触发器。为保证语篇一致性,对动词词的单个字符,如果属于已标注触发器,则将其与前一个字符和下一个字符合并,形成候选触发器。
2)文档级事件抽取
在上述方法中,只有句子中的单词或短语的局部信息和句子级别的上下文被用来训练分类器。然而,如果我们将事件提取任务放在更大的背景下,比如包含多个句子的文档或包含多个文档的集合,那么就可以利用许多全局信息来提高提取的准确性,即使只是为了从一个句子中提取事件。对于文档级事件抽取,两个关键的设计问题包括:可以使用什么样的全局信息;以及如何应用它们来辅助事件提取。对于第一个设计问题,可以从跨文档、跨句子、跨事件和跨实体的推断中挖掘全局信息,如词义、实体类型和论元提及。对于第二种,全局信息既可以作为局部分类器的补充模块使用,也可以作为局部分类器中的全局特征使用。
通过评估局部分类器输出的置信度,可以利用全局信息建立一个附加的推理模型来增强局部分类器。Ji和Grishman观察到,事件论元在句子和文档之间会保持一定的一致性,比如不同句子和相关文档中的词义一致性,以及相同或相关事件的不同提及之间的论元和角色的一致性。为了利用这些观察结果,他们建议为主题相关的文档簇建立两条全局推理规则,即每组一个触发意义和每组一个论元角色,以帮助提高句子级分类器的抽取置信度。Liao和Grishman后来扩展了这种全局信息推理的应用,并进一步提出了应用文档级跨事件信息。Liu等人探索了事件-事件关联和主题-事件关联两种全局信息,建立了概率软逻辑(PSL)模型,进一步处理来自局部分类器的初始判断,生成最终的抽取结果。
也可以利用全局信息和句子级特征作为全局特征来训练局部事件抽取分类器。Hong等人提出了一种跨实体推理模型,提取实体类型一致性作为关系特征。他们认为,一致类型的实体通常以相同的角色参与类似的事件。为此,他们定义了9个新的全局特征,包括实体子类型、领域中实体-子类型共现、论元实体-子类型等,训练一组句子级SVM分类器。在另外两篇文献中也采用了类似的办法。Liao和Grishman提出首先通过潜在的Dirichlet分配(LDA)模型计算每个文档的主题分布,并将这些主题特征编码到局部抽取分类器中。在另一篇论文中定义了三种全局特征,包括词汇桥特征、语篇桥特征和a角色填充分布特征,它们与局部特征一起用于训练抽取分类器。
C. 联合分类模型
典型的CNN结构通常使用一个max-pooling层对整个句子的表示进行max运算,然而,一个句子可能包含多个事件,这些事件共享论元,但角色不同。Chen等人提出了一种动态多池化卷积神经网络(DMCNN),通过提取词汇级和句子级特征的动态多池化层来评估句子的每个部分。在DMCNN中,根据预测的触发器将每个特征分为三个部分,并保留每个部分的最大值,以保留更多有价值的信息,而不是使用单一的max-pooling值。此外,他们的CNN模型还使用了一个skip-gram模型来捕捉单词的有意义的语义规则。
在上述方法中,卷积运算将k-gram的向量线性映射到特征空间中,在特征空间中,这些k-gram向量被获得为k个连续词得表示的级联。为了利用长范围和非连续依赖关系,Nguyen和Grishman[151]建议对句子中所有可能的非连续k-gram执行卷积操作,其中最大汇集函数用于计算卷积分数,以区分最重要的非连续k-gram进行事件检测。
一些学者对典型的CNN模型提出了一些改进。例如,Burel等人设计了一种语义增强的深度学习模型,称为Dual-CNN,它在典型的CNN中增加了一个语义层,以捕获上下文信息。Li等人提出了一种并行多池卷积神经网络(PMCNN),该网络可以捕获句子的成分语义特征,用于生物医学事件的提取。PMCNN还利用基于依存关系的嵌入来表示词的语义和句法,并使用矫正后的线性单元作为非线性函数。Kodelja等人采用bootstrapping方法构建了全局上下文的表示,并将其集成到CNN模型中进行事件提取。
B. 递归神经网络(RNN)
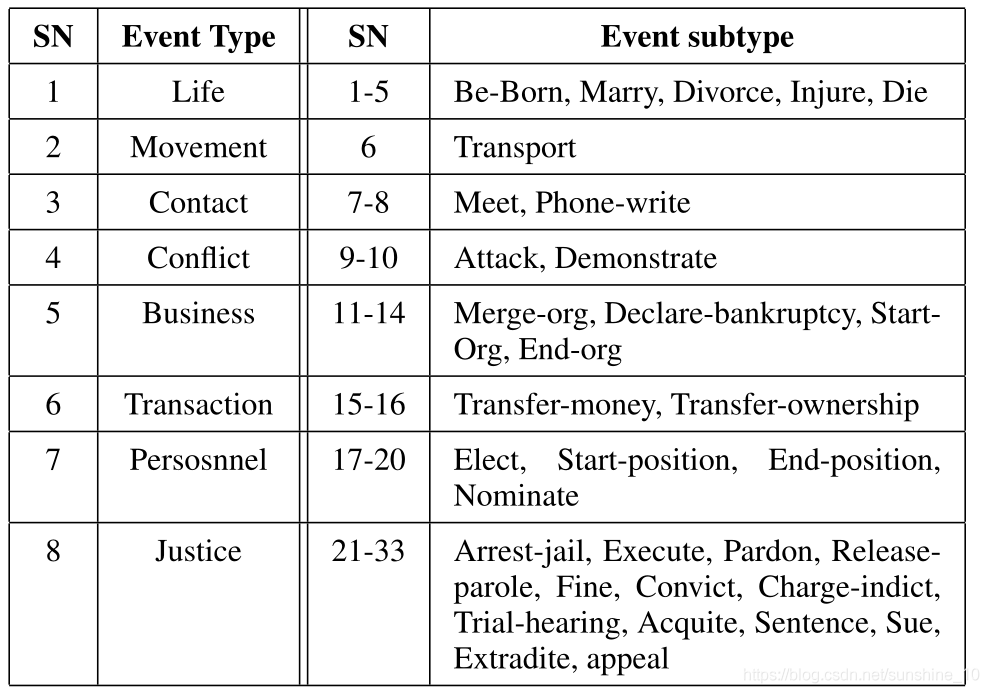
上述基于机器学习和深度学习技术的算法都是一种有监督的学习方法,需要有标注的语料库进行模型训练。由于深度学习方法通常涉及神经网络中的大量论元,通常标注的语料库越大,模型的训练效果就越好。然而,由于标注过程费时费力,因此获取标注语料库是一项相当昂贵的任务,在大多数情况下还需要领域专业知识和专业知识。正因为如此,许多标注语料库规模较小,覆盖率较低。例如,在ACE 2005语料库中,只定义了33种感兴趣的事件类型,对不同应用的覆盖率非常低;而且,在标记的事件中,大约60%的事件类型的实例少于100个,3个事件类型的实例甚至少于10个。
如何提高一小组标记黄金数据的提取精度已成为一个关键的挑战。一种简单的解决方案是首先自动生成更多的训练数据,然后使用包含原始黄金数据和新生成的数据的混合数据进行模型训练。在本节中,我们回顾了文献中的此类解决方案,尽管它们可能使用了不同的名称,如半监督、弱监督、远程监督等。我们注意到,尽管使用混合数据会影响模型的训练过程,但这些学习分类算法的基础与前两节中回顾的算法相似。在这一部分,我们主要关注他们如何将少量的标签数据扩展到更大的语料库,以及如何从混合数据中训练提取模型。
A. 联合数据扩展与模型训练
带标签的黄金数据集可能很小,然而,它们可以迭代地用于模型训练。这种通过数据替换的迭代模型训练是一种称为Bootstrapping的公知技术的变体。其基本思想是首先用一小部分有标签的数据训练分类器,对新的无标签数据进行分类。除了分类标签,分类器还输出新数据的分类置信度。然后,将置信度较高的数据加入到训练数据中,用于下一轮模型训练。
利用分类结果进行数据扩展的关键挑战在于如何评估新数据的分类可信度。由于事件具有复杂的结构,比如不同的事件类型包含不同的论元和不同的角色,因此计算事件提取置信度通常准确性较低。Liao和Grishman提出只使用新样本提取结果的一部分来进行数据扩展,特别是信心分数高的触发器及其论元。基于它们的提取模型,根据来自他们的触发器分类器和论元分类器的概率之间的乘积选择信心分数最高的。此外,他们使用了一种名为INDRI的信息检索系统来收集相关文档的群集,并应用了之前文献中提出的跨文档推理算法,以包含高置信度的训练数据。
Wang等人提出使用基于触发器的潜在实例来发现未标注的数据进行扩展。如果一个单词在黄金数据集中用作触发器,则在未标记的数据集中提及该单词的所有实例也可能表示相同的潜在实例。基于这样的假设,他们提出了一个对抗性的训练过程,以过滤掉噪声的实例,同时提取信息实例来包含新的数据。虽然包含来自分类器输出的新数据具有成本效益,但实际上不能保证新包含的数据具有完全正确的标注。在这方面,人工检查是非常必要的。Liao和Grishman提出了一种称为伪协同测试的主动学习策略,只使用最少的人工来标注那些高置信度的新数据。
上述算法侧重于训练数据的扩展,但事件类型与标记为黄金的算法相同。最近,一些研究人员提出了一种迁移学习算法,用与黄金数据集中的参考数据不同的事件类型来扩展训练数据。例如,Nguyen 等人提出了一种两阶段算法来训练CNN模型,该模型能够有效地将知识从旧事件类型转移到目标类型(新类型)。具体地说,第一阶段是基于旧事件类型的标记数据,用随机初始化权重矩阵训练CNN模型。第二阶段是利用第一阶段初始化的权重矩阵,基于一小部分目标类型的标记数据训练CNN模型。最后,将两阶段训练的CNN模型用于目标类型事件检测和旧型事件检测。
除了利用一小部分带有新类型的标签数据外,Huang等人还提出了一种zero-short迁移学习方法,用于提取具有新的不可见类型的事件,它只需要手动构造新的事件类型(例如,事件模式中的事件类型名称和论元角色名称)。特别是,他们首先通过训练基于黄金数据的CNN模型,构建了事件提及结构(来自事件实例的触发器、论元及其关系结构)和事件类型结构(来自事件模式的类型、角色及其关系结构)的向量表示。接下来,他们使用优化的CNN模型来表示新数据的事件提及结构和事件类型结构,并为每个新事件提及找到最接近的事件类型。
B. 知识库中的数据扩展
许多现有的知识库存储了大量的结构化信息,如FrameNet、Freebase、Wikipedia、WordNet,这些信息可以被利用来生成新的标注数据作为事件抽取的训练数据。
FrameNet定义了许多完整的语义框架,每个框架由一个词汇单元和一组名称元素组成。这样的框架与事件具有高度相似的结构。由于FrameNet中的许多帧实际上表示某些事件,一些研究人员已经探索了将帧映射到事件以进行数据扩展。例如,Liu等人通过使用从FrameNet中的给定例句中检测到的事件来扩展ACE训练数据。具体地说,他们首先学习了基于ACE标记数据的事件检测模型,然后使用该模型来产生对例句的初步判断。然后,基于“相同的词汇单位、相同的框架和相关的框架倾向于表达相同的事件”这一假设,将一组软约束应用于全局推理,并将初始判断和软约束形式化为一阶公式,并用概率软逻辑(PSL)对其建模以进行全局推理。最后,它们从给定的例句中检测事件以进行数据扩展。
类似地,Freebase(语义知识库)中的复合值类型(CVT)可视为事件模板,CVT实例可视为事件实例。CVT的类型、取值和论元分别被认为是事件类型、事件中的论元和事件中起作用的论元。Zeng等人利用Freebase中CVT的结构信息自动标注事件提及,以进行数据扩展。他们首先确定了CVT的关键论元,CVT在一个事件中发挥着重要作用。如果一个句子包含了CVT的所有关键论元,那么它很可能表达了CVT所呈现的事件。结果,他们记录了这句话中的单词或短语,以匹配CVT属性作为涉及的论元和它们的角色进行标注。
此外,Chen等人建议通过利用FrameNet和Freebase来扩展培训数据。Araki和Mitamura利用WordNet和Wikipedia生成新的训练数据。除了使用通用知识库外,一些研究还侧重于使用相关知识库进行特定领域的事件抽取。例如,Rao等人使用包含蛋白质之间关系的生物路径交换(BioPax)知识库来扩展来自PubMed12Central文章的训练数据。在金融领域,Yang等人利用金融事件知识库进行数据扩展,其中包含9种常见的金融事件类型。
C. 从多语言数据扩展数据
与监督和半监督学习不同,无监督学习不训练基于标记语料库的事件抽取模型。相反,无监督学习方法主要集中在开放领域的事件抽取任务上,如基于词分布表示的触发器和论元检测,以及根据事件实例和提及的相似性对它们进行聚类。
A. 事件提及检测和跟踪
事件提及是可以用一个或多个句子描述事件的关键字的集合。这些任务包括检测一篇文章中的事件提及,以及跟踪不同文章中类似的事件提及。请注意,不需要对触发器类型和(/或)论元角色进行分类,因为在此类任务中通常不预定义类型和角色。
TDT评测将主题定义为一组与一些有重大影响的现实事件密切相关的新闻和(/或)故事。然后,TDT任务定义为判断给定的文章是否与同一主题的事件群集相关,并为每篇文章提供具有{Y es,No,Brief}等简单标签的TDT语料库,以表明其与主题的相关性,其中Brief表示部分相关。
在许多TDT评测中,首先将句子转换为向量表示,然后计算向量距离来衡量事件检测中与某个主题的相似度。例如,Yang等人和Nallapati等人用他们的TF-IDF向量表示文档,这是使用术语袋(bag-of-terms)表示的传统向量空间模型。具体地说,文档中使用术语(单词或短语)频率(TF)和逆文档频率(IDF)进行统计加权。它们将k个排名靠前的术语保存在术语袋中,作为文档的表示向量。
Stokes和Carthy提出用词汇链来表示文档,通过探索文本的内聚结构来创建一个语义相关的词序列。例如,关于airplane的文档的词汇链可能由以下单词组成:plane、airplane、pilot、cockpit、airhostess、wing、engine。他们使用WordNet识别文档中的词汇链,WordNet用单个唯一标识符表示同义词。
根据TDT评测的任务定义,在没有使用TDT语料库的情况下,已经进行了一些其他研究,以检测各种网站上的新文章是否与已经识别的事件相关。例如,Naughton等人提出了利用聚合层次聚类算法对新闻文章和聚类句子进行词袋编码的句子向量化方法。
除了使用单词和句子嵌入之外,一些人还建议利用新闻文章的几个额外信息,如时间和地点,来增强事件提及检测。Ribeiro等人提出将时间、地点和内容维度综合到文本表示中,并采用全对相似度搜索算法和马尔可夫聚类算法对描述同一事件的新闻文章进行聚类。同样,Yu和Wu提出了一种Time2V EC表示技术,该技术通过上下文向量和时间向量构造文章表示,并采用双层聚类算法进行事件检测。最近,提出了一些新的事件检测和跟踪方法,包括负样本-剪枝支持向量机、基于卷积神经网络的多实例学习模型和基于加权无向二部图的排序框架。
B. 事件抽取和聚类
事件提及检测的任务主要是检测事件关键词,以便对表达同一事件的句子或文章进行聚类。一些研究提出进一步区分事件触发词和论元,以便对相似事件进行聚类,并构建相似事件的事件模式。
一种简单的方法是将句子中的动词视为事件触发器。例如,Rusu等人使用句子中的动词作为事件触发器,并利用触发器与命名实体、时间表达式、句子主语和句子宾语之间的依存路径来识别事件论元。此外,一些知识库还可以用于增强触发器和论元判别。Chambers和Jurafsky认为WordNet中的动词及其同义词集是触发器,而句法对象的实体是论元。Huang等人将OntoNotes中的所有名词和动词概念以及FrameNet中的动词和词汇单位视为候选事件触发器。此外,他们将所有与候选触发语有语义关系的概念都视为候选论元。然后,他们计算每对候选触发器和论元之间的相似度,以识别最终触发器和论元。
基于提取的触发器和论元,事件实例可以被聚集到不同的事件组中,每个事件组具有潜在的但不同的主题。例如,Chambers和Jurafsky提出使用概率潜在Dirichlet分配主题模型来计算事件相似度进行聚类。Romadhony等人提出利用结构化知识库对触发器和论元进行聚类。Jans等人基于skip-gram统计识别并聚集事件链,该事件链可以被视为由动词及其从属行为者组成的部分事件结构。
此外,对于每个事件组,还可以使用槽-值(slot-value)结构来建立事件模式,其中槽可以表示事件实例的某个论元角色和值(对应于事件实例的论元)。Yuan等人首先引入了一个新的事件分析问题,以填充开放领域新闻文档中的槽值事件结构。他们还提出了一种模式归纳框架,通过利用实体共现信息来提取槽模式。 Glavasˆ s 和ˆSnajder认为事件往往包含一些常见的论元角色,如施事、目标、时间和地点,并提出构建一个事件图结构来识别不同文献中提到的相同事件。
C. 从社交媒体抽取事件
简而言之,许多领域都可以从事件抽取技术和系统的进步中受益。
尽管有很好的应用前景,但事件提取仍然是一项相当具有挑战性的任务,因为事件具有不同的结构和组件;而自然语言往往存在语义歧义和语篇风格。此外,事件抽取也与其他NLP任务密切相关,如命名实体识别(NER)、词性标注(POS)、语法解析等,这些任务的执行方式和输出结果可能会促进事件抽取,也可能会对其性能产生负面影响。为了促进事件抽取的发展和应用,人们开展了许多公开评估计划,提供任务定义、标注语料库和公开竞赛,以促进事件抽取等信息抽取研究,这些研究也吸引了许多人才贡献新的算法、技术和系统。下面我们简单介绍一下这些知名的节目。
A. 公开评估项目
1997年,美国国防部高级研究计划局(DARPA)、卡内基梅隆大学(Carnegie Mellon University)、龙系统(Dragon Systems)和马萨诸塞大学阿默斯特分校(University Of Massachusetts At Amherst)共同创立了另一个公共评估项目,名为主题检测和跟踪(TDT),以促进在一系列广播新闻文章中发现和跟踪新事件。后来,美国国家标准与技术研究所(NIST)为TDT项目建立了一套完整的评估体系。
需要注意的是,同一事件可能在不同的句子或文档中被多次提及。如何区分同一事件的多个事件提及属于另一个关键的自然语言处理任务,称为事件共指。在本文中,我们不考虑事件提及共同参考解决方案。
Ahn 首先提出将ACE事件提取任务分为四个子任务:触发器检测、事件/触发器类型识别、事件论元检测、论元角色识别。例如,考虑以下句子:
sentence 1:At daybreak on the 9th, the terrorists set off a truck bomb attack in Nazareth.
句子1:9日黎明时分,***在拿撒勒发动了一场卡车炸弹袭击。
在此句中存在“Conflict/Attract”事件。事件提取器应该通过检测句子中的触发词“Attract”并将其分类为“Conflict/Attract”事件,接下来,应该从文本中提取与该事件相关的论元,并根据预定义的事件结构标识它们各自的角色。
本部分主要介绍事件抽取任务的语料库资源。通常,公开评测程序为事件抽取的任务评测提供了多个语料库。公共评测程序根据任务定义对语料库进行人工标注,并用于机器学习方法中的模型训练和验证;样本标注由具有领域知识的专业人员或专家完成,标注后的样本可视为带有ground truth标签。然而,由于标注过程成本高昂,许多公共语料库规模较小,覆盖率较低。
A. ACE事件语料库
TAC-KBP中的事件块检测任务专注于检测对事件的明确提及及其在RichERE中定义的类型和子类型。由语言数据联盟(LDC)提供的TAC-KPB 2015语料库包括158个文档作为先前训练集,以及202个附加文档作为正式评估的测试集,这些文档来自新闻报道文章和论坛。
参照ACE语料库,定义了TAC-KBP(Rich Ere)中的事件类型和子类型,包括9种事件类型和38个子类型。此外,事件提及必须被分配到三个真实值中的一个:实际(实际发生)、一般(没有具体的时间或地点)和其他(非一般事件,如失败事件、未来事件和条件语句等)。
TAC-KBP 2015语料库仅用于英语评估,但在TAC-KBP 2016中为所有任务增加了汉语和西班牙语。
C. TDT语料库
在开放领域事件抽取方面,语言数据联盟LDC还提供了一系列语料库来支持从TDT-1到TDT-5的TDT研究,包括英文和中文的文本和语音(普通话)。
每个TDT语料库包含数百万个新闻故事,用数百个主题(事件)进行标注,这些主题(事件)来自多个来源,如新闻通讯社和广播文章。此外,所有的音频材料都由LDC转换为文本材料。
如果故事讨论的是目标主题,则为这些故事主题标签分配的值为YES;如果讨论的内容占故事的比例不到10%,则为Brief。否则,(默认)标记值为no。
D. 其它特定领域的语料库
语言模式不同于AutoSlog中的事件模式。在人工标注语料库中,利用语言模式自动建立事件模式;而事件模式用于事件提取。此外,AutoSlog被设计为使用单个事件论元提取事件,因此他们的语料库为每个事件都标注了单个论元。
例如,在下面的句子中,划线的短语“public buildings”被标注为为具有“bombing”类型事件的“target”角色的论元。
sentence2:In Laoroya, Junin department, in the central Peruvian mountain range, public buildings (target, bombing) were bombed and a car-bomb was detonated.
句子2:在老罗亚,Junin省,在中部Peruvian山脉,公共建筑(目标,炸弹)被炸,一辆汽车炸弹被引爆。
具体地说,AutoSlog使用句法分析器Circle来识别人工标注语料库中每个句子的词性(POS),如主语、谓语、宾语、介词等。随后,AutoSlog生成触发词词典和概念节点,它们可以被视为事件模式,涉及事件触发器、事件类型、事件论元和论元角色。在上句中“public buildings”被CIRCUS认定为主语,因为它后面跟着一个被动动词“bombed”,所以它与预定义的语言模式“passive-verb”相匹配,因此,它将“bombed”添加到触发词字典中,并生成具有轰炸类型的实践模式“was bombed”。在模式匹配(事件抽取)过程中,AutoSlog首先利用触发词词典查找候选事件语句,然后按CIRCUS对候选语句进行词性标注。然后,它将触发词的语法特征(即使用CIRCUS的POS输出)与事件模式向关联,以提取论元及事件角色。对于预定义的具有绑架类型的事件模式“took”,它的触发词“took”将定位候选句子,“they took 2-year-old Gilberto Molasco, son of Patricio Rodriguez”。使用CIRCUS进行词性分析的结果进一步证明了“Giberto Molasco”是DOBJ(直接宾语)。最后结合POS的结果和预定义的事件模式,AutoSlog可以提取绑架类型的事件,及其其触发词“took”和受害者“Gilberto Molasco”的论元。
为了增加可伸缩性,Kim等人设计了并行自动语言知识获取系统PALKA(Parallel Automatic Language Knowledge Acquisition),从标注语料库中自动获取事件模式。他们为事件模式定义了一种专门的表示,称为FP结构(框架-短语和模式结构)。在Palka中,事件模式以FP-Structure的形式构建,并通过语义约束的泛化进一步调整。此外,FP-Structure将单事件论元模式扩展为具有多个论元的事件模式,即一个事件可以包含多个论元。例如句子2中的“bombing”事件,除了“target”论元之外,还可能有多个潜在的事件论元,如“agent”,“patient”,“instrument”和“effect”。此外,PALKA将一句中的多个从句转换为多句形式,用于事件提取。
这两个阶段和四个子任务可以以流水线方式执行,其中多个独立的分类器各自被训练,并且一个分类器的输出也可以作为其后续分类器的输入的一部分。这四个子任务也可以联合执行,一个分类器执行多任务分类,并直接输出多个子任务的结果。
无论是PipeLine执行还是联合执行,学习分类器都需要首先执行一些特征工程工作,即从文本中提取特征作为分类模型的输入。因此,在这一部分中,我们首先介绍一些用于分类器训练的常见特征,然后回顾和比较文献中的流水线和联合分类方法。
A. 学习模型的文本特征
在句子级事件提取中,首先将句子标记为离散的token,然后根据特征工程的结果用特征向量表示每个token。在英语中,token通常是一个单词;然而,在某些语言中,token可以是一个字符或多个字符,也可以是一个单词或短语。分类器从语料库中带标记的文本进行训练,然后用于确定某个token是否为触发词(或事件论元)及其事件类型(或论元角色)。
David Ahn[27]提出了一个典型的PipeLine处理框架,由两个连续的分类器组成:第一个分类器TimBL采用最近邻学习算法检测触发器;第二个分类器MegaM采用最大熵学习器来识别论元。为了训练TimBL分类器,使用了词法特征、WordNet特征、上下文特征、依存特征和相关实体特征;使用触发词、事件类型、实体提及、实体类型、触发词与实体之间的依存路径等特征训练MegaM分类器。已经提出了许多不同的pipeline分类器,它们通过不同类型的特征进行训练。例如Chieu和Ng加入unigram、bigram等特征,采用最大熵分类器。在生物医学领域,更多特定领域的特征和专业知识被用于分类器训练,如频率特征、token特征、路径特征等。
一些研究者提出将模式匹配集成到到机器学习框架中。如前所述,事件模式可以提供更精确的事件结构,其中包含某些特定触发器及其关联论元之间的显式关系,尽管这种关系是人工设计的,没有太多的可扩展性。Grishman等人提出先进行模式匹配,预先分配一些潜在的事件类型,然后使用分类器识别剩余的事件提及。这两种方法在增强事件提取方面是相辅相成的。此外,在机器学习分类器检测到触发器后,也可以执行模式匹配。由于事件论元与触发器类型密切相关,因此应用一些良好的触发器-论元关系有助于改进论元识别。此外,事件模式也可以与token特征合并,作为机器学习分类的输入。
如事件标注事例图所示,在一些语言(如英语)中,句子token化是一项简单的任务,因为单词是由分隔符显式分隔的。然而,在其他一些语言中,如汉语和日语,句子由连续的字符组成,而不使用分隔符来分隔单词。因此,分词通常需要首先将一个句子分成许多离散的token(词/词)。由于分词可以独立于事件提取任务实现,如果有分词错误,则会传播到下游任务,降低其性能。此外,由于自然语言的多义性,在分词后,一个词很可能包含两个或两个以上的触发器;而触发器被分为两个或两个以上的单词。
为了解决这类标记化问题,Zhao等人提出,对于分句后的每个单词,首先从同义词字典中获取每个潜在触发器及其对应的事件类型。Chen和Ji提出同时使用词语级和字符级触发器标注策略。此外,他们提出使用字符级token(包括当前字符、前一个字符和下一个字符等)训练最大熵马尔科夫模型分类器用于触发检测。Li等人利用内部触发语的成分语义和触发词之间的语篇一致性来增强中文触发语的识别能力。具体来说,如果一个动词词的组成部分(一个或多个汉字)被标记为中文触发器,那么它就是一个触发器。为保证语篇一致性,对动词词的单个字符,如果属于已标注触发器,则将其与前一个字符和下一个字符合并,形成候选触发器。
2)文档级事件抽取
在上述方法中,只有句子中的单词或短语的局部信息和句子级别的上下文被用来训练分类器。然而,如果我们将事件提取任务放在更大的背景下,比如包含多个句子的文档或包含多个文档的集合,那么就可以利用许多全局信息来提高提取的准确性,即使只是为了从一个句子中提取事件。对于文档级事件抽取,两个关键的设计问题包括:可以使用什么样的全局信息;以及如何应用它们来辅助事件提取。对于第一个设计问题,可以从跨文档、跨句子、跨事件和跨实体的推断中挖掘全局信息,如词义、实体类型和论元提及。对于第二种,全局信息既可以作为局部分类器的补充模块使用,也可以作为局部分类器中的全局特征使用。
通过评估局部分类器输出的置信度,可以利用全局信息建立一个附加的推理模型来增强局部分类器。Ji和Grishman观察到,事件论元在句子和文档之间会保持一定的一致性,比如不同句子和相关文档中的词义一致性,以及相同或相关事件的不同提及之间的论元和角色的一致性。为了利用这些观察结果,他们建议为主题相关的文档簇建立两条全局推理规则,即每组一个触发意义和每组一个论元角色,以帮助提高句子级分类器的抽取置信度。Liao和Grishman后来扩展了这种全局信息推理的应用,并进一步提出了应用文档级跨事件信息。Liu等人探索了事件-事件关联和主题-事件关联两种全局信息,建立了概率软逻辑(PSL)模型,进一步处理来自局部分类器的初始判断,生成最终的抽取结果。
也可以利用全局信息和句子级特征作为全局特征来训练局部事件抽取分类器。Hong等人提出了一种跨实体推理模型,提取实体类型一致性作为关系特征。他们认为,一致类型的实体通常以相同的角色参与类似的事件。为此,他们定义了9个新的全局特征,包括实体子类型、领域中实体-子类型共现、论元实体-子类型等,训练一组句子级SVM分类器。在另外两篇文献中也采用了类似的办法。Liao和Grishman提出首先通过潜在的Dirichlet分配(LDA)模型计算每个文档的主题分布,并将这些主题特征编码到局部抽取分类器中。在另一篇论文中定义了三种全局特征,包括词汇桥特征、语篇桥特征和a角色填充分布特征,它们与局部特征一起用于训练抽取分类器。
C. 联合分类模型
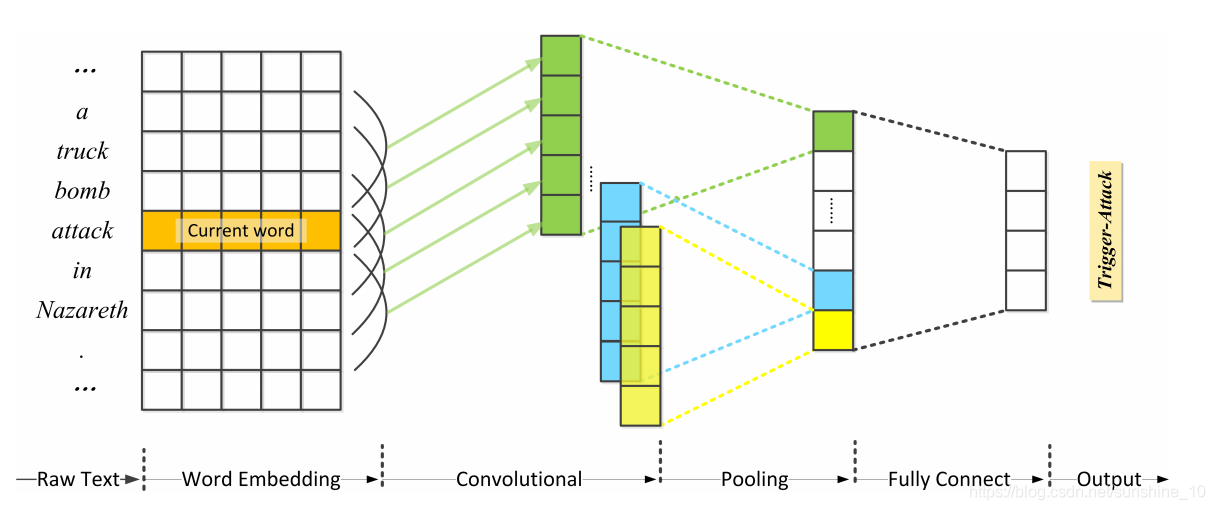
典型的CNN结构通常使用一个max-pooling层对整个句子的表示进行max运算,然而,一个句子可能包含多个事件,这些事件共享论元,但角色不同。Chen等人提出了一种动态多池化卷积神经网络(DMCNN),通过提取词汇级和句子级特征的动态多池化层来评估句子的每个部分。在DMCNN中,根据预测的触发器将每个特征分为三个部分,并保留每个部分的最大值,以保留更多有价值的信息,而不是使用单一的max-pooling值。此外,他们的CNN模型还使用了一个skip-gram模型来捕捉单词的有意义的语义规则。
在上述方法中,卷积运算将k-gram的向量线性映射到特征空间中,在特征空间中,这些k-gram向量被获得为k个连续词得表示的级联。为了利用长范围和非连续依赖关系,Nguyen和Grishman[151]建议对句子中所有可能的非连续k-gram执行卷积操作,其中最大汇集函数用于计算卷积分数,以区分最重要的非连续k-gram进行事件检测。
一些学者对典型的CNN模型提出了一些改进。例如,Burel等人设计了一种语义增强的深度学习模型,称为Dual-CNN,它在典型的CNN中增加了一个语义层,以捕获上下文信息。Li等人提出了一种并行多池卷积神经网络(PMCNN),该网络可以捕获句子的成分语义特征,用于生物医学事件的提取。PMCNN还利用基于依存关系的嵌入来表示词的语义和句法,并使用矫正后的线性单元作为非线性函数。Kodelja等人采用bootstrapping方法构建了全局上下文的表示,并将其集成到CNN模型中进行事件提取。
B. 递归神经网络(RNN)
上述基于机器学习和深度学习技术的算法都是一种有监督的学习方法,需要有标注的语料库进行模型训练。由于深度学习方法通常涉及神经网络中的大量论元,通常标注的语料库越大,模型的训练效果就越好。然而,由于标注过程费时费力,因此获取标注语料库是一项相当昂贵的任务,在大多数情况下还需要领域专业知识和专业知识。正因为如此,许多标注语料库规模较小,覆盖率较低。例如,在ACE 2005语料库中,只定义了33种感兴趣的事件类型,对不同应用的覆盖率非常低;而且,在标记的事件中,大约60%的事件类型的实例少于100个,3个事件类型的实例甚至少于10个。
如何提高一小组标记黄金数据的提取精度已成为一个关键的挑战。一种简单的解决方案是首先自动生成更多的训练数据,然后使用包含原始黄金数据和新生成的数据的混合数据进行模型训练。在本节中,我们回顾了文献中的此类解决方案,尽管它们可能使用了不同的名称,如半监督、弱监督、远程监督等。我们注意到,尽管使用混合数据会影响模型的训练过程,但这些学习分类算法的基础与前两节中回顾的算法相似。在这一部分,我们主要关注他们如何将少量的标签数据扩展到更大的语料库,以及如何从混合数据中训练提取模型。
A. 联合数据扩展与模型训练
带标签的黄金数据集可能很小,然而,它们可以迭代地用于模型训练。这种通过数据替换的迭代模型训练是一种称为Bootstrapping的公知技术的变体。其基本思想是首先用一小部分有标签的数据训练分类器,对新的无标签数据进行分类。除了分类标签,分类器还输出新数据的分类置信度。然后,将置信度较高的数据加入到训练数据中,用于下一轮模型训练。
利用分类结果进行数据扩展的关键挑战在于如何评估新数据的分类可信度。由于事件具有复杂的结构,比如不同的事件类型包含不同的论元和不同的角色,因此计算事件提取置信度通常准确性较低。Liao和Grishman提出只使用新样本提取结果的一部分来进行数据扩展,特别是信心分数高的触发器及其论元。基于它们的提取模型,根据来自他们的触发器分类器和论元分类器的概率之间的乘积选择信心分数最高的。此外,他们使用了一种名为INDRI的信息检索系统来收集相关文档的群集,并应用了之前文献中提出的跨文档推理算法,以包含高置信度的训练数据。
Wang等人提出使用基于触发器的潜在实例来发现未标注的数据进行扩展。如果一个单词在黄金数据集中用作触发器,则在未标记的数据集中提及该单词的所有实例也可能表示相同的潜在实例。基于这样的假设,他们提出了一个对抗性的训练过程,以过滤掉噪声的实例,同时提取信息实例来包含新的数据。虽然包含来自分类器输出的新数据具有成本效益,但实际上不能保证新包含的数据具有完全正确的标注。在这方面,人工检查是非常必要的。Liao和Grishman提出了一种称为伪协同测试的主动学习策略,只使用最少的人工来标注那些高置信度的新数据。
上述算法侧重于训练数据的扩展,但事件类型与标记为黄金的算法相同。最近,一些研究人员提出了一种迁移学习算法,用与黄金数据集中的参考数据不同的事件类型来扩展训练数据。例如,Nguyen 等人提出了一种两阶段算法来训练CNN模型,该模型能够有效地将知识从旧事件类型转移到目标类型(新类型)。具体地说,第一阶段是基于旧事件类型的标记数据,用随机初始化权重矩阵训练CNN模型。第二阶段是利用第一阶段初始化的权重矩阵,基于一小部分目标类型的标记数据训练CNN模型。最后,将两阶段训练的CNN模型用于目标类型事件检测和旧型事件检测。
除了利用一小部分带有新类型的标签数据外,Huang等人还提出了一种zero-short迁移学习方法,用于提取具有新的不可见类型的事件,它只需要手动构造新的事件类型(例如,事件模式中的事件类型名称和论元角色名称)。特别是,他们首先通过训练基于黄金数据的CNN模型,构建了事件提及结构(来自事件实例的触发器、论元及其关系结构)和事件类型结构(来自事件模式的类型、角色及其关系结构)的向量表示。接下来,他们使用优化的CNN模型来表示新数据的事件提及结构和事件类型结构,并为每个新事件提及找到最接近的事件类型。
B. 知识库中的数据扩展
许多现有的知识库存储了大量的结构化信息,如FrameNet、Freebase、Wikipedia、WordNet,这些信息可以被利用来生成新的标注数据作为事件抽取的训练数据。
FrameNet定义了许多完整的语义框架,每个框架由一个词汇单元和一组名称元素组成。这样的框架与事件具有高度相似的结构。由于FrameNet中的许多帧实际上表示某些事件,一些研究人员已经探索了将帧映射到事件以进行数据扩展。例如,Liu等人通过使用从FrameNet中的给定例句中检测到的事件来扩展ACE训练数据。具体地说,他们首先学习了基于ACE标记数据的事件检测模型,然后使用该模型来产生对例句的初步判断。然后,基于“相同的词汇单位、相同的框架和相关的框架倾向于表达相同的事件”这一假设,将一组软约束应用于全局推理,并将初始判断和软约束形式化为一阶公式,并用概率软逻辑(PSL)对其建模以进行全局推理。最后,它们从给定的例句中检测事件以进行数据扩展。
类似地,Freebase(语义知识库)中的复合值类型(CVT)可视为事件模板,CVT实例可视为事件实例。CVT的类型、取值和论元分别被认为是事件类型、事件中的论元和事件中起作用的论元。Zeng等人利用Freebase中CVT的结构信息自动标注事件提及,以进行数据扩展。他们首先确定了CVT的关键论元,CVT在一个事件中发挥着重要作用。如果一个句子包含了CVT的所有关键论元,那么它很可能表达了CVT所呈现的事件。结果,他们记录了这句话中的单词或短语,以匹配CVT属性作为涉及的论元和它们的角色进行标注。
此外,Chen等人建议通过利用FrameNet和Freebase来扩展培训数据。Araki和Mitamura利用WordNet和Wikipedia生成新的训练数据。除了使用通用知识库外,一些研究还侧重于使用相关知识库进行特定领域的事件抽取。例如,Rao等人使用包含蛋白质之间关系的生物路径交换(BioPax)知识库来扩展来自PubMed12Central文章的训练数据。在金融领域,Yang等人利用金融事件知识库进行数据扩展,其中包含9种常见的金融事件类型。
C. 从多语言数据扩展数据
与监督和半监督学习不同,无监督学习不训练基于标记语料库的事件抽取模型。相反,无监督学习方法主要集中在开放领域的事件抽取任务上,如基于词分布表示的触发器和论元检测,以及根据事件实例和提及的相似性对它们进行聚类。
A. 事件提及检测和跟踪
事件提及是可以用一个或多个句子描述事件的关键字的集合。这些任务包括检测一篇文章中的事件提及,以及跟踪不同文章中类似的事件提及。请注意,不需要对触发器类型和(/或)论元角色进行分类,因为在此类任务中通常不预定义类型和角色。
TDT评测将主题定义为一组与一些有重大影响的现实事件密切相关的新闻和(/或)故事。然后,TDT任务定义为判断给定的文章是否与同一主题的事件群集相关,并为每篇文章提供具有{Y es,No,Brief}等简单标签的TDT语料库,以表明其与主题的相关性,其中Brief表示部分相关。
在许多TDT评测中,首先将句子转换为向量表示,然后计算向量距离来衡量事件检测中与某个主题的相似度。例如,Yang等人和Nallapati等人用他们的TF-IDF向量表示文档,这是使用术语袋(bag-of-terms)表示的传统向量空间模型。具体地说,文档中使用术语(单词或短语)频率(TF)和逆文档频率(IDF)进行统计加权。它们将k个排名靠前的术语保存在术语袋中,作为文档的表示向量。
Stokes和Carthy提出用词汇链来表示文档,通过探索文本的内聚结构来创建一个语义相关的词序列。例如,关于airplane的文档的词汇链可能由以下单词组成:plane、airplane、pilot、cockpit、airhostess、wing、engine。他们使用WordNet识别文档中的词汇链,WordNet用单个唯一标识符表示同义词。
根据TDT评测的任务定义,在没有使用TDT语料库的情况下,已经进行了一些其他研究,以检测各种网站上的新文章是否与已经识别的事件相关。例如,Naughton等人提出了利用聚合层次聚类算法对新闻文章和聚类句子进行词袋编码的句子向量化方法。
除了使用单词和句子嵌入之外,一些人还建议利用新闻文章的几个额外信息,如时间和地点,来增强事件提及检测。Ribeiro等人提出将时间、地点和内容维度综合到文本表示中,并采用全对相似度搜索算法和马尔可夫聚类算法对描述同一事件的新闻文章进行聚类。同样,Yu和Wu提出了一种Time2V EC表示技术,该技术通过上下文向量和时间向量构造文章表示,并采用双层聚类算法进行事件检测。最近,提出了一些新的事件检测和跟踪方法,包括负样本-剪枝支持向量机、基于卷积神经网络的多实例学习模型和基于加权无向二部图的排序框架。
B. 事件抽取和聚类
事件提及检测的任务主要是检测事件关键词,以便对表达同一事件的句子或文章进行聚类。一些研究提出进一步区分事件触发词和论元,以便对相似事件进行聚类,并构建相似事件的事件模式。
一种简单的方法是将句子中的动词视为事件触发器。例如,Rusu等人使用句子中的动词作为事件触发器,并利用触发器与命名实体、时间表达式、句子主语和句子宾语之间的依存路径来识别事件论元。此外,一些知识库还可以用于增强触发器和论元判别。Chambers和Jurafsky认为WordNet中的动词及其同义词集是触发器,而句法对象的实体是论元。Huang等人将OntoNotes中的所有名词和动词概念以及FrameNet中的动词和词汇单位视为候选事件触发器。此外,他们将所有与候选触发语有语义关系的概念都视为候选论元。然后,他们计算每对候选触发器和论元之间的相似度,以识别最终触发器和论元。
基于提取的触发器和论元,事件实例可以被聚集到不同的事件组中,每个事件组具有潜在的但不同的主题。例如,Chambers和Jurafsky提出使用概率潜在Dirichlet分配主题模型来计算事件相似度进行聚类。Romadhony等人提出利用结构化知识库对触发器和论元进行聚类。Jans等人基于skip-gram统计识别并聚集事件链,该事件链可以被视为由动词及其从属行为者组成的部分事件结构。
此外,对于每个事件组,还可以使用槽-值(slot-value)结构来建立事件模式,其中槽可以表示事件实例的某个论元角色和值(对应于事件实例的论元)。Yuan等人首先引入了一个新的事件分析问题,以填充开放领域新闻文档中的槽值事件结构。他们还提出了一种模式归纳框架,通过利用实体共现信息来提取槽模式。 Glavasˆ s 和ˆSnajder认为事件往往包含一些常见的论元角色,如施事、目标、时间和地点,并提出构建一个事件图结构来识别不同文献中提到的相同事件。
C. 从社交媒体抽取事件



 举报
举报



