PLC
登录
直播中
陈霞
8年用户
1015经验值
私信
关注
ROC曲线与AUC值有何关系
开启该帖子的消息推送
曲线
AUC
分类器
什么是ROC曲线?ROC曲线有何功能?ROC曲线与AUC值有何关系?
回帖
(1)
刘丰标
2021-8-23 11:28:34
数据挖掘实战–桑坦德银行客户交易预测项目
一、项目介绍:
二、简单介绍ROC曲线
ROC曲线和AUC值一起,他们具有评价学习器性能,检验分类器对客户进行正确排序的能力。
分类器产生的结果通常是一个概率值而不是直接的0/1变量,通常数值越大,代表正例的可能性越大。即ROC曲线越包在外面效果就越好。
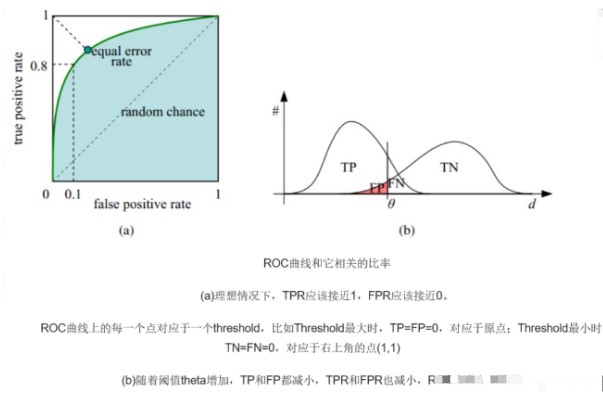
图(a)绿色的线就是ROC曲线,随着截断点的变小,TPR随着FPR的变化。注意观察横纵坐标,分别为FPR、TPR。
纵轴:TPR = 正例分对的概率 = TP/(TP+FN),也就是查全率、召回率、反馈率(Recall),也称灵敏度(Sensitivity)。
横轴:FPR = 负例分错的概率 = FP/(FP+TN),也叫做假警报率。
曲线下方的绿色阴影面积就是AUC值。
AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
ROC 曲线下面积代表分类器随机预测真正类(Ture Positives)要比假正类(False Positives)概率大的确信度。
截断点:很多学习器是为测试样本而产生一个实值或概率去进行预测,然后将这个预测值与一个分类阈值进行比较,若大于阈值分为正类,否则为反类,因此分类过程可以看作选取一个截断点。(通常截取点为0.5,大于0.5为正例,小于0.5为负例)
选择不同的截断点对结果的影响很大,截断点的取值区间是【0,1】,如果截断点靠近1,则被判断为正例的数量会变少;如果截断点靠近0,则被判断为正例的数量会变多。横轴的取值范围为【0,1】,x点代表FPR的概率;纵轴的取值范围为【0,1】,y点代表TPR的概率
不同任务中,可以选择不同的截断点,若更注重”查准率”,应选择排序中靠前的位置进行截断,反之若注重”查全率”,则选择靠后位置截断。因此排序本身质量的好坏,可以直接导致学习器不同泛化性能的好坏,这就是ROC曲线的大概思想。
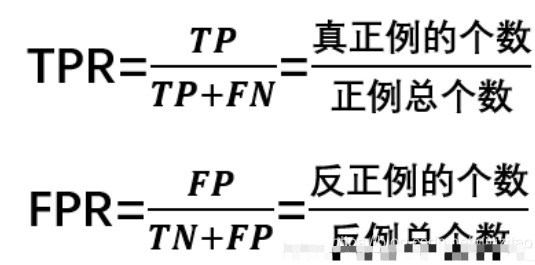
在一个二分类模型中,对于所得到的连续结果,假设已确定一个阀值,比如说 0.6,大于这个值的实例划归为正类,小于这个值则划到负类中。如果减小阀值,减到0.5,固然能识别出更多的正类,也就是提高了识别出的正例占所有正例 的比类,即TPR,但同时也将更多的负实例当作了正实例,即提高了FPR。为了形象化这一变化,在此引入ROC曲线。
小结:ROC曲线越包在外面越好,AUC值越大越好。
三、数据探索、清洗
① 导包、库
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns plt.rcParams[‘font.sans-serif’]=[‘SimHei’] plt.rcParams[‘axes.unicode_minus’]=False plt.style.use(“ggplot”) #使用 ggplot 的绘图风格 from sklearn.model_selection import train_test_split from sklearn.feature_selection import SelectFromModel from sklearn import model_selection ② 导入训练集并查看数据
data_train = pd.read_csv(‘train.csv’) data_train.info() data_train[‘target’].unique() data_train.head()
ID_code:用户名
target:用户行为结果。0代表没有交易行为,1代表有交易行为
Var_(0 - 199):涉及到的用户特征变量
共计20万用户信息,涉及特征变量200个。
③ 导入测试集并查看数据
data_test = pd.read_csv(‘test.csv’) data_test.info() data_test.head()
ID_code:用户名
Var_(0 - 199):涉及到的用户特征变量
共计20万用户信息,涉及特征变量200个。
④ 缺失值查询和补充
由于数据量较大,因此首先要进行缺失值的查询,在此处定义缺失值查询函数:
def missing_data(data): total = data.isnull().sum() percent = (data.isnull().sum()/data.isnull().count()*100) tt = pd.concat([total, percent], axis=1, keys=[‘Total’, ‘Percent’]) types = [] for col in data.columns: dtype = str(data[col].dtype) types.append(dtype) tt[‘Types’] = types return(np.transpose(tt)) missing_data(data_train) #missing_data(data_test) 缺失值查询函数的作用在于输出每列元素中缺失的总数以及缺失值相应的百分比,一般来说缺失值相较于数据集比例极小时,可采用均值填充或删除等手法。若缺失值在总元素中占据比例较大,则应当选用其他填补法进行填充(较为典型的有拉格朗日插值法)。
通过缺失值查询函数,我们了解到,容量为20万用户的数据集中并未包含缺失值,这对于我们后续的操作提供了较大的便利性。
四、特征工程,数据可视化
① 数据的描述性统计
data_train.describe()
通过描述性统计分析,我们发现各特征单位之间差距较小,单位较为接近。所以无需进行无量纲化处理。
对于不同特征之间数据差异较大的情况,需要进行无量纲化处理(归一化、标准化)
对于不同的特征向量,比如年龄、购买量、购买额,在数值的量纲上相差十倍或者百千倍。如果不归一化处理,就不容易进行比较、求距离,模型参数和正确率精确度就会受影响,甚至得不出正确的结果。
稀疏类型的数据集(稀疏数据是指:数据集中绝大多数数值缺失或者为零的数据)会需要通过计算稀疏相似度或通过数据变化进行处理,而稠密型数据则可以免去大量的数据处理工作,故数据预处理阶段大多需要将稀疏数据转化为稠密数据。
② 查看训练集中分类为0与分类为1的用户分布情况
count_classes = pd.value_counts(data_train[‘target’], sort=True).sort_index() count_classes.plot(kind=‘bar’) plt.title(“target 类别统计”) plt.xlabel(“target”) plt.ylabel(“个数”) print(count_classes) x = 0,1 plt.xticks(x, x, rotation=0)#调节x坐标的倾斜度,rotation是度数,默认为90 for x, count_classes in zip(x, count_classes): plt.text(x, count_classes , ‘%.2f’ % count_classes, ha=‘center’, va=‘bottom’)
我们看到训练集train中,0型用户与1型用户数量分布是不平衡的,即出现了数据偏斜情况,这也要求我们在训练模型时对数据均衡性问题进行处理。
③ 数据标准化处理(我们这里也可以不用标准化,原因在上面①)
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。
进行数据的标准化处理主要有两个好处:
(1)提升模型的收敛速度:若数据样本含有量纲差距极大的两项指标,当对其进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢。
(2)提升模型的精度:在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
这里我选用Sklearn中自带的标准化处理工具包对数据集进行标准化:
from sklearn import preprocessing from sklearn.preprocessing import StandardScaler ss = StandardScaler() data_1 = data_train.drop(columns=[‘ID_code’,‘target’]) data_scaled = ss.fit_transform(data_1) df = pd.DataFrame(data_scaled) df.columns = data_1.columns df_1 = pd.concat([data_train[‘ID_code’],data_train[‘target’],df],axis = 1,join = ‘inner’) data_t1 = data_test.drop(columns=[‘ID_code’]) data_scaled_t = ss.fit_transform(data_t1) df_t2 = pd.DataFrame(data_scaled_t) df_t2.columns = data_1.columns # df_t2.head() df_2 = pd.concat([data_test[‘ID_code’],df_t2],axis = 1,join = ‘inner’) 切分数据集:
df_data = df_1.drop(columns=[‘ID_code’,‘target’]) df_target = df_1.target dt_data = df_2.drop(columns=[‘ID_code’]) X_train, X_test, y_train, y_test = train_test_split(df_data, df_target, test_size=0.3, random_state=0) 五、初步模型构建
在模型构建之前,我们还需要考虑两件事:
(1)将用于训练以及初步验证的数据集df_1分割为训练集和测试集两部分:
训练集的作用是训练模型,让模型具有初步的分类或预测功能。
测试集的作用是通过预留出一部分含有标签的数据,去验证我们之前构建的模型实际应用效果如何。
打个比方,这就像一本带有参考答案的习题集,我们对着答案边看边学前半本,此时从一个小白,变得有了一定的解题能力和经验积累。之后我们独立完成剩余的半本习题集,再拿出答案去对自己独立完成的习题进行打分,这个分数就可以在一定程度上展示我们目前解决问题的能力。
(2)模型分类能力的评估指标:
如上面所说,在最基本的精准率,即Accuracy,在数据集失衡的情况下并不具有说服力。
此处引入以下几个概念:
Precision、Re-Call、F1-Score
在解释这几项指标的定义之前,我们先对模型的分类情况做一个小概括,对于二分类模型,对于数据的分类情况可划分为以下四种:
True Positive(TP):预测为正,实际为正(分类成功)
False Positive(FP)::预测为正,实际为负(分类失败,即取伪)
False Negative(FN):预测为负,实际为正(分类失败,即弃真)
Ture Negative(TN):预测为负,实际为负(分类成功)
常用的模型性能评估指标Accuracy,其定义为:正确分类样本/总样本数 。
Precision指标定义为:
,其含义为:实际正样本与预测正样本的比例,即模型判断为正例的样本中,真正的正例有多少。
Re-Call指标定义为:
,其含义为:预测成功的样本中,正样本所占比例,即模型覆盖正例的能力。
而F1-Score指标兼顾了之前二者,进行了综合考量,其形式为:
,F1值是精确率和召回率的调和均值,相当于精确率和召回率的综合评价指标。
通俗来说:
Precision 倾向于对于正样本判别的准确率,当对于将负例误判为正例需要付出较高代价的情况时,我们倾向于提高Precision,例如对于犯罪嫌疑人的判别,我们抱着不错判一个好人的原则,在此基础上宁可错放一些坏人。
Re-call倾向于对于使模型覆盖尽可能多的正样本,即尽可能不放过任何一个正样本。当弃真,即将正样本误判为负样本的代价较高时,我们倾向于尽可能提高Recall,例如对于灾难的预测,漏判会造成极为严重的后果。
通过前面较为冗长的步骤清洗数据、及初步的探索观察。下面我们终于可以开始进行模型的构建了。
通过前文中的观察及初步了解,本问题中的数据为稠密型数据的分类预测,因此在选用算法时应当考虑以分类算法为主。这里我选取了较为简单实用(即超参数少,训练速度快,对于机器和调参要求较低)的朴素贝叶斯、逻辑回归算法作为初步尝试。
① 逻辑回归模型调用及建模:
逻辑回归虽然从广义上来说属于回归分析模型,但实际应用领域却是二分类问题较多。
此处从Sklearn中调用逻辑回归模型,参数设定C=0.01,由于数据集较大,设定solver = ‘sag’。(具体原理本文暂不详述)
#建立逻辑回归模型 from sklearn.linear_model import LogisticRegression from sklearn.metrics import roc_curve, auc,roc_auc_score from sklearn.metrics import classification_report lg = LogisticRegression(C=0.01,solver = ‘sag’) lg.fit(X_train,y_train) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(lg.score(X_test, y_test))) print (“nn ---逻辑回归---”) rf_roc_auc = roc_auc_score(y_test, lg.predict(X_test)) print (“逻辑回归 AUC = %2.2f” % rf_roc_auc) print(classification_report(y_test, lg.predict(X_test))) #绘制Roc曲线观察模型的性能 fprl_gnb, tprl_gnb, thresholdsl_gnb = roc_curve(y_test, lg.predict_proba(X_test)[:,1]) plt.figure() plt.plot(fprl_gnb, tprl_gnb, color = ‘yellow’,label=‘Lg Model (area = %0.2f)’ % rf_roc_auc) plt.plot([0, 1], [0, 1],‘r--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘Lg_ROC’) plt.show()
② 使用朴素贝叶斯模型进行建模:
from sklearn.naive_bayes import GaussianNB from sklearn.metrics import accuracy_score gnb = GaussianNB() gnb.fit(X_train,y_train) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(gnb.score(X_test, y_test))) print (“nn ---朴素贝叶斯---”) gnb_roc_auc = roc_auc_score(y_test, gnb.predict(X_test)) print (“朴素贝叶斯 AUC = %2.2f” % gnb_roc_auc) print(classification_report(y_test, gnb.predict(X_test))) accuracy_gnb = accuracy_score(y_test,gnb.predict(X_test)) fpr1_gnb, tpr1_gnb, thresholds1_gnb = roc_curve(y_test, gnb.predict_proba(X_test)[:,1]) ### Plot the ROC curves plt.figure() plt.plot(fpr1_gnb, tpr1_gnb, color = ‘blue’,label=‘GNB Model (area = %0.2f)’ % gnb_roc_auc) plt.plot([0, 1], [0, 1],‘r--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘GNB_ROC’) plt.show()
③ 使用XGboost模型进行建模:
import os os.environ[‘CUDA_VISIBLE_DEVICES’] = ‘0’ from xgboost.sklearn import XGBClassifier xgb = XGBClassifier(max_depth=3, n_estimators=200, learn_rate=0.01) xgb.fit(X_train,y_train) print(xgb.score(X_test,y_test)) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(xgb.score(X_test, y_test))) print (“nn ---XGBoost---”) xgb_roc_auc = roc_auc_score(y_test, xgb.predict(X_test)) print (“XGBoost AUC = %2.2f” % rf_roc_auc) print(classification_report(y_test, xgb.predict(X_test))) accuracy_xgb = accuracy_score(y_test,xgb.predict(X_test)) fpr2_xgb, tpr2_xgb, thresholds2_xgb = roc_curve(y_test, xgb.predict_proba(X_test)[:,1]) ### Plot the ROC curves plt.figure() plt.plot(fpr2_xgb, tpr2_xgb, color = ‘green’,label=‘XGB Model (area = %0.2f)’ % xgb_roc_auc) plt.plot([0, 1], [0, 1],‘r--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘XGB_ROC’) plt.show()
AUC值(Area under the Curve of ROC)为ROC曲线所覆盖的区域面积,AUC越大,分类器分类效果越好。(具体原理另述,在本文中仅作简介)
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 《 AUC 《 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC 《 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
由三大模型的初步分析可看出,三大算法在不平衡的数据集X_test, y_test上由较好的表现情况,但是由于数据集本身的不平衡性,因此应当更多的参考AUC得分及其他三项指标。
在初步建立的三大模型中,可以看出三项评估指标对于正、负样本的得分有较大差异,主要表现对于负例的得分较高,而正例的得分较低。即模型对于负样本的覆盖率及分类精准度较高,而对于正样本的分类能力较弱。
总结,我们所建立的初步模型,虽然对于测试集中的样本分类表现良好,但从分类的覆盖率来说,倾向于覆盖更多的负样本,而未能覆盖正样本。
六、模型优化及改进
从上面得出的结论,目前构建的三大基础模型存在以下问题:
1、由于原始数据分布不平衡,因此造成三大初级模型对正负样本具有不同的偏好性,即对于正样本分类能力较差。
2、经过上面得出的准确率比较后,三大模型中表现最好的为朴素贝叶斯模型,为尝试更高的精确度,我们可以考虑采用集成学习(Stacking Classifier)进一步提高分类能力。
针对目前存在的第一类问题,在此引入SMOTE过采样方法,其定义如下:
SMOTE全称是Synthetic Minority Oversampling Technique,即合成少数类过采样技术,它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General),SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。
用Smote过采样解决样本分布不平衡的问题,这里以逻辑回归模型为例:
from imblearn.over_sampling import SMOTE os = SMOTE(random_state=0) X_train, X_test, y_train, y_test = train_test_split(df_data, df_target, test_size=0.3, random_state=0) columns = X_train.columns os_data_X,os_data_y=os.fit_sample(X_train, y_train) os_data_X = pd.DataFrame(data=os_data_X,columns=columns ) os_data_y= pd.DataFrame(data=os_data_y,columns=[‘y’]) print(“过采样以后的数据量: ”,len(os_data_X)) print(“未开户的用户数量: ”,len(os_data_y[os_data_y[‘y’]==0])) print(“开户的用户数量: ”,len(os_data_y[os_data_y[‘y’]==1])) print(“未开户的用户数量的百分比: ”,len(os_data_y[os_data_y[‘y’]==0])/len(os_data_X)) print(“开户的用户数量的百分比: ”,len(os_data_y[os_data_y[‘y’]==1])/len(os_data_X)) #上述步骤完成过采样,现在开始使用过采样后的样本训练逻辑回归模型 logreg_smote = LogisticRegression( C=0.01,solver = ‘sag’) logreg_smote.fit(os_data_X,os_data_y.values.reshape(-1)) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(logreg_smote.score(X_test, y_test))) print (“nn ---逻辑回归---”) log_roc_auc = roc_auc_score(y_test, logreg_smote.predict(X_test)) print (“逻辑回归 AUC = %2.2f” % log_roc_auc) print(classification_report(y_test, logreg_smote.predict(X_test))) fprl_gnb, tprl_gnb, thresholdsl_gnb = roc_curve(y_test, logreg_smote.predict_proba(X_test)[:,1]) plt.figure() plt.plot(fprl_gnb, tprl_gnb, color = ‘yellow’,label=‘Log Model (area = %0.2f)’ % log_roc_auc) plt.plot([0, 1], [0, 1],‘r--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘Log_ROC’) plt.show()
从上面结果看来,通过SMOTE采样,使得逻辑回归模型的AUC得分从0.63变化为0.77,可认为在较大程度上提高了模型的分类能力。
下面用朴素贝叶斯模型训练采样处理后的数据。
#上述步骤完成过采样,现在开始使用过采样后的样本训练朴素贝叶斯模型 gnb_smote = GaussianNB() gnb_smote.fit(os_data_X,os_data_y.values.reshape(-1)) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(gnb_smote.score(X_test, y_test))) print (“nn ---朴素贝叶斯---”) gnb_roc_auc = roc_auc_score(y_test, gnb_smote.predict(X_test)) print (“朴素贝叶斯 AUC = %2.2f” % gnb_roc_auc) print(classification_report(y_test, gnb_smote.predict(X_test))) fprl_gnb, tprl_gnb, thresholdsl_gnb = roc_curve(y_test, gnb_smote.predict_proba(X_test)[:,1]) ### Plot the ROC curves plt.figure() plt.plot(fpr1_gnb, tpr1_gnb, color = ‘blue’,label=‘GNB Model (area = %0.2f)’ % gnb_roc_auc) plt.plot([0, 1], [0, 1],‘r--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘GNB_ROC’) plt.show()
可以看到用朴素贝叶斯训练采样处理过的数据效果没有逻辑斯特好。
针对第二类问题,我们尝试使用集成模型来提高预测的性能,将上面所说的三大模型用作基础模型进行集成,所用工具为sklearn中的StackingClassifier:
在此简单介绍StackingClassifier思想:
Stacking 是一种集合学习技术,通过元分类器组合多个分类模型。基于完整训练集训练各个分类模型; 然后,基于整体中的各个分类模型的输出 - 元特征来拟合元分类器。元分类器可以根据预测类标签或来自集合的概率进行训练。
代码实现如下:
from mlxtend.classifier import StackingClassifier stregr1 = StackingClassifier(classifiers=[gnb, xgb], meta_classifier=lg,use_probas=True) ##选用gnb xgb用作第一层模型,log作为第二层模型 stregr1.fit(X_train, y_train) stregr1.score(X_test,y_test) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(stregr1.score(X_test, y_test))) print (“nn ---Ensemble_1---”) Ensemble_2_roc_auc = roc_auc_score(y_test, stregr1.predict(X_test)) print (“Ensemble_1_AUC = %2.2f” % Ensemble_2_roc_auc) print(classification_report(y_test, stregr1.predict(X_test))) accuracy_Ensemble_2 = accuracy_score(y_test,stregr.predict(X_test)) fpr_e2, tpr_e2, thresholds_e2 = roc_curve(y_test, stregr1.predict_proba(X_test)[:,1]) ### Plot the ROC curves plt.figure() plt.plot(fpr_e2, tpr_e2, label=‘ Ensemble Model (area = %0.2f)’ % Ensemble_2_roc_auc) plt.plot([0, 1], [0, 1],‘--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘Ensemble_2_ROC’) plt.show()
上面是用原始数据训练的集成模型,下面我们用采样处理后的数据训练看看效果。
stregr1.fit(os_data_X,os_data_y.values.reshape(-1)) stregr1.score(X_test,y_test) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(stregr1.score(X_test, y_test))) print (“nn ---Ensemble_1_smote---”) Ensemble_2_roc_auc = roc_auc_score(y_test, stregr1.predict(X_test)) print (“Ensemble_1_smote_AUC = %2.2f” % Ensemble_2_roc_auc) print(classification_report(y_test, stregr1.predict(X_test))) accuracy_Ensemble_2 = accuracy_score(y_test,stregr1.predict(X_test)) fpr_e2, tpr_e2, thresholds_e2 = roc_curve(y_test, stregr1.predict_proba(X_test)[:,1]) ### Plot the ROC curves plt.figure() plt.plot(fpr_e2, tpr_e2, label=‘ Ensemble Model (area = %0.2f)’ % Ensemble_2_roc_auc) plt.plot([0, 1], [0, 1],‘--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘Ensemble_2_ROC’) plt.show()
效果不如用原始数据训练的。
七、提交结果
# coding=UTF-8 # 利用现有模型训练 data_X_test = dt_data # data_X_test.head() test_preds = logreg_smote.predict(data_X_test) np.savetxt(‘logreg_smote_result.csv’,np.c_[df_2[“ID_code”].values,test_preds],delimiter=‘,’,header=‘ID_code,target’,comments=‘’,fmt=‘%s’) test_preds = gnb_smote.predict(data_X_test) np.savetxt(‘gnb_smote_result.csv’,np.c_[df_2[“ID_code”].values,test_preds],delimiter=‘,’,header=‘ID_code,target’,comments=‘’,fmt=‘%s’) test_preds = stregr1.predict(data_X_test) np.savetxt(‘stregr1result.csv’,np.c_[df_2[“ID_code”].values,test_preds],delimiter=‘,’,header=‘ID_code,target’,comments=‘’,fmt=‘%s’) 这里提交了 采样数据训练的逻辑斯特模型,采样数据训练的朴素贝叶斯模型,原始数据训练的集成模型。
可以看到用采样处理后的数据训练的逻辑斯特模型效果较好。但准确率还不够,后面还得进一步提升,第一名的score都到0.92727,继续学习,提升准确率。
数据挖掘实战–桑坦德银行客户交易预测项目
一、项目介绍:
二、简单介绍ROC曲线
ROC曲线和AUC值一起,他们具有评价学习器性能,检验分类器对客户进行正确排序的能力。
分类器产生的结果通常是一个概率值而不是直接的0/1变量,通常数值越大,代表正例的可能性越大。即ROC曲线越包在外面效果就越好。
图(a)绿色的线就是ROC曲线,随着截断点的变小,TPR随着FPR的变化。注意观察横纵坐标,分别为FPR、TPR。
纵轴:TPR = 正例分对的概率 = TP/(TP+FN),也就是查全率、召回率、反馈率(Recall),也称灵敏度(Sensitivity)。
横轴:FPR = 负例分错的概率 = FP/(FP+TN),也叫做假警报率。
曲线下方的绿色阴影面积就是AUC值。
AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
ROC 曲线下面积代表分类器随机预测真正类(Ture Positives)要比假正类(False Positives)概率大的确信度。
截断点:很多学习器是为测试样本而产生一个实值或概率去进行预测,然后将这个预测值与一个分类阈值进行比较,若大于阈值分为正类,否则为反类,因此分类过程可以看作选取一个截断点。(通常截取点为0.5,大于0.5为正例,小于0.5为负例)
选择不同的截断点对结果的影响很大,截断点的取值区间是【0,1】,如果截断点靠近1,则被判断为正例的数量会变少;如果截断点靠近0,则被判断为正例的数量会变多。横轴的取值范围为【0,1】,x点代表FPR的概率;纵轴的取值范围为【0,1】,y点代表TPR的概率
不同任务中,可以选择不同的截断点,若更注重”查准率”,应选择排序中靠前的位置进行截断,反之若注重”查全率”,则选择靠后位置截断。因此排序本身质量的好坏,可以直接导致学习器不同泛化性能的好坏,这就是ROC曲线的大概思想。
在一个二分类模型中,对于所得到的连续结果,假设已确定一个阀值,比如说 0.6,大于这个值的实例划归为正类,小于这个值则划到负类中。如果减小阀值,减到0.5,固然能识别出更多的正类,也就是提高了识别出的正例占所有正例 的比类,即TPR,但同时也将更多的负实例当作了正实例,即提高了FPR。为了形象化这一变化,在此引入ROC曲线。
小结:ROC曲线越包在外面越好,AUC值越大越好。
三、数据探索、清洗
① 导包、库
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns plt.rcParams[‘font.sans-serif’]=[‘SimHei’] plt.rcParams[‘axes.unicode_minus’]=False plt.style.use(“ggplot”) #使用 ggplot 的绘图风格 from sklearn.model_selection import train_test_split from sklearn.feature_selection import SelectFromModel from sklearn import model_selection ② 导入训练集并查看数据
data_train = pd.read_csv(‘train.csv’) data_train.info() data_train[‘target’].unique() data_train.head()
ID_code:用户名
target:用户行为结果。0代表没有交易行为,1代表有交易行为
Var_(0 - 199):涉及到的用户特征变量
共计20万用户信息,涉及特征变量200个。
③ 导入测试集并查看数据
data_test = pd.read_csv(‘test.csv’) data_test.info() data_test.head()
ID_code:用户名
Var_(0 - 199):涉及到的用户特征变量
共计20万用户信息,涉及特征变量200个。
④ 缺失值查询和补充
由于数据量较大,因此首先要进行缺失值的查询,在此处定义缺失值查询函数:
def missing_data(data): total = data.isnull().sum() percent = (data.isnull().sum()/data.isnull().count()*100) tt = pd.concat([total, percent], axis=1, keys=[‘Total’, ‘Percent’]) types = [] for col in data.columns: dtype = str(data[col].dtype) types.append(dtype) tt[‘Types’] = types return(np.transpose(tt)) missing_data(data_train) #missing_data(data_test) 缺失值查询函数的作用在于输出每列元素中缺失的总数以及缺失值相应的百分比,一般来说缺失值相较于数据集比例极小时,可采用均值填充或删除等手法。若缺失值在总元素中占据比例较大,则应当选用其他填补法进行填充(较为典型的有拉格朗日插值法)。
通过缺失值查询函数,我们了解到,容量为20万用户的数据集中并未包含缺失值,这对于我们后续的操作提供了较大的便利性。
四、特征工程,数据可视化
① 数据的描述性统计
data_train.describe()
通过描述性统计分析,我们发现各特征单位之间差距较小,单位较为接近。所以无需进行无量纲化处理。
对于不同特征之间数据差异较大的情况,需要进行无量纲化处理(归一化、标准化)
对于不同的特征向量,比如年龄、购买量、购买额,在数值的量纲上相差十倍或者百千倍。如果不归一化处理,就不容易进行比较、求距离,模型参数和正确率精确度就会受影响,甚至得不出正确的结果。
稀疏类型的数据集(稀疏数据是指:数据集中绝大多数数值缺失或者为零的数据)会需要通过计算稀疏相似度或通过数据变化进行处理,而稠密型数据则可以免去大量的数据处理工作,故数据预处理阶段大多需要将稀疏数据转化为稠密数据。
② 查看训练集中分类为0与分类为1的用户分布情况
count_classes = pd.value_counts(data_train[‘target’], sort=True).sort_index() count_classes.plot(kind=‘bar’) plt.title(“target 类别统计”) plt.xlabel(“target”) plt.ylabel(“个数”) print(count_classes) x = 0,1 plt.xticks(x, x, rotation=0)#调节x坐标的倾斜度,rotation是度数,默认为90 for x, count_classes in zip(x, count_classes): plt.text(x, count_classes , ‘%.2f’ % count_classes, ha=‘center’, va=‘bottom’)
我们看到训练集train中,0型用户与1型用户数量分布是不平衡的,即出现了数据偏斜情况,这也要求我们在训练模型时对数据均衡性问题进行处理。
③ 数据标准化处理(我们这里也可以不用标准化,原因在上面①)
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。
进行数据的标准化处理主要有两个好处:
(1)提升模型的收敛速度:若数据样本含有量纲差距极大的两项指标,当对其进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢。
(2)提升模型的精度:在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
这里我选用Sklearn中自带的标准化处理工具包对数据集进行标准化:
from sklearn import preprocessing from sklearn.preprocessing import StandardScaler ss = StandardScaler() data_1 = data_train.drop(columns=[‘ID_code’,‘target’]) data_scaled = ss.fit_transform(data_1) df = pd.DataFrame(data_scaled) df.columns = data_1.columns df_1 = pd.concat([data_train[‘ID_code’],data_train[‘target’],df],axis = 1,join = ‘inner’) data_t1 = data_test.drop(columns=[‘ID_code’]) data_scaled_t = ss.fit_transform(data_t1) df_t2 = pd.DataFrame(data_scaled_t) df_t2.columns = data_1.columns # df_t2.head() df_2 = pd.concat([data_test[‘ID_code’],df_t2],axis = 1,join = ‘inner’) 切分数据集:
df_data = df_1.drop(columns=[‘ID_code’,‘target’]) df_target = df_1.target dt_data = df_2.drop(columns=[‘ID_code’]) X_train, X_test, y_train, y_test = train_test_split(df_data, df_target, test_size=0.3, random_state=0) 五、初步模型构建
在模型构建之前,我们还需要考虑两件事:
(1)将用于训练以及初步验证的数据集df_1分割为训练集和测试集两部分:
训练集的作用是训练模型,让模型具有初步的分类或预测功能。
测试集的作用是通过预留出一部分含有标签的数据,去验证我们之前构建的模型实际应用效果如何。
打个比方,这就像一本带有参考答案的习题集,我们对着答案边看边学前半本,此时从一个小白,变得有了一定的解题能力和经验积累。之后我们独立完成剩余的半本习题集,再拿出答案去对自己独立完成的习题进行打分,这个分数就可以在一定程度上展示我们目前解决问题的能力。
(2)模型分类能力的评估指标:
如上面所说,在最基本的精准率,即Accuracy,在数据集失衡的情况下并不具有说服力。
此处引入以下几个概念:
Precision、Re-Call、F1-Score
在解释这几项指标的定义之前,我们先对模型的分类情况做一个小概括,对于二分类模型,对于数据的分类情况可划分为以下四种:
True Positive(TP):预测为正,实际为正(分类成功)
False Positive(FP)::预测为正,实际为负(分类失败,即取伪)
False Negative(FN):预测为负,实际为正(分类失败,即弃真)
Ture Negative(TN):预测为负,实际为负(分类成功)
常用的模型性能评估指标Accuracy,其定义为:正确分类样本/总样本数 。
Precision指标定义为:
,其含义为:实际正样本与预测正样本的比例,即模型判断为正例的样本中,真正的正例有多少。
Re-Call指标定义为:
,其含义为:预测成功的样本中,正样本所占比例,即模型覆盖正例的能力。
而F1-Score指标兼顾了之前二者,进行了综合考量,其形式为:
,F1值是精确率和召回率的调和均值,相当于精确率和召回率的综合评价指标。
通俗来说:
Precision 倾向于对于正样本判别的准确率,当对于将负例误判为正例需要付出较高代价的情况时,我们倾向于提高Precision,例如对于犯罪嫌疑人的判别,我们抱着不错判一个好人的原则,在此基础上宁可错放一些坏人。
Re-call倾向于对于使模型覆盖尽可能多的正样本,即尽可能不放过任何一个正样本。当弃真,即将正样本误判为负样本的代价较高时,我们倾向于尽可能提高Recall,例如对于灾难的预测,漏判会造成极为严重的后果。
通过前面较为冗长的步骤清洗数据、及初步的探索观察。下面我们终于可以开始进行模型的构建了。
通过前文中的观察及初步了解,本问题中的数据为稠密型数据的分类预测,因此在选用算法时应当考虑以分类算法为主。这里我选取了较为简单实用(即超参数少,训练速度快,对于机器和调参要求较低)的朴素贝叶斯、逻辑回归算法作为初步尝试。
① 逻辑回归模型调用及建模:
逻辑回归虽然从广义上来说属于回归分析模型,但实际应用领域却是二分类问题较多。
此处从Sklearn中调用逻辑回归模型,参数设定C=0.01,由于数据集较大,设定solver = ‘sag’。(具体原理本文暂不详述)
#建立逻辑回归模型 from sklearn.linear_model import LogisticRegression from sklearn.metrics import roc_curve, auc,roc_auc_score from sklearn.metrics import classification_report lg = LogisticRegression(C=0.01,solver = ‘sag’) lg.fit(X_train,y_train) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(lg.score(X_test, y_test))) print (“nn ---逻辑回归---”) rf_roc_auc = roc_auc_score(y_test, lg.predict(X_test)) print (“逻辑回归 AUC = %2.2f” % rf_roc_auc) print(classification_report(y_test, lg.predict(X_test))) #绘制Roc曲线观察模型的性能 fprl_gnb, tprl_gnb, thresholdsl_gnb = roc_curve(y_test, lg.predict_proba(X_test)[:,1]) plt.figure() plt.plot(fprl_gnb, tprl_gnb, color = ‘yellow’,label=‘Lg Model (area = %0.2f)’ % rf_roc_auc) plt.plot([0, 1], [0, 1],‘r--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘Lg_ROC’) plt.show()
② 使用朴素贝叶斯模型进行建模:
from sklearn.naive_bayes import GaussianNB from sklearn.metrics import accuracy_score gnb = GaussianNB() gnb.fit(X_train,y_train) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(gnb.score(X_test, y_test))) print (“nn ---朴素贝叶斯---”) gnb_roc_auc = roc_auc_score(y_test, gnb.predict(X_test)) print (“朴素贝叶斯 AUC = %2.2f” % gnb_roc_auc) print(classification_report(y_test, gnb.predict(X_test))) accuracy_gnb = accuracy_score(y_test,gnb.predict(X_test)) fpr1_gnb, tpr1_gnb, thresholds1_gnb = roc_curve(y_test, gnb.predict_proba(X_test)[:,1]) ### Plot the ROC curves plt.figure() plt.plot(fpr1_gnb, tpr1_gnb, color = ‘blue’,label=‘GNB Model (area = %0.2f)’ % gnb_roc_auc) plt.plot([0, 1], [0, 1],‘r--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘GNB_ROC’) plt.show()
③ 使用XGboost模型进行建模:
import os os.environ[‘CUDA_VISIBLE_DEVICES’] = ‘0’ from xgboost.sklearn import XGBClassifier xgb = XGBClassifier(max_depth=3, n_estimators=200, learn_rate=0.01) xgb.fit(X_train,y_train) print(xgb.score(X_test,y_test)) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(xgb.score(X_test, y_test))) print (“nn ---XGBoost---”) xgb_roc_auc = roc_auc_score(y_test, xgb.predict(X_test)) print (“XGBoost AUC = %2.2f” % rf_roc_auc) print(classification_report(y_test, xgb.predict(X_test))) accuracy_xgb = accuracy_score(y_test,xgb.predict(X_test)) fpr2_xgb, tpr2_xgb, thresholds2_xgb = roc_curve(y_test, xgb.predict_proba(X_test)[:,1]) ### Plot the ROC curves plt.figure() plt.plot(fpr2_xgb, tpr2_xgb, color = ‘green’,label=‘XGB Model (area = %0.2f)’ % xgb_roc_auc) plt.plot([0, 1], [0, 1],‘r--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘XGB_ROC’) plt.show()
AUC值(Area under the Curve of ROC)为ROC曲线所覆盖的区域面积,AUC越大,分类器分类效果越好。(具体原理另述,在本文中仅作简介)
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 《 AUC 《 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC 《 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
由三大模型的初步分析可看出,三大算法在不平衡的数据集X_test, y_test上由较好的表现情况,但是由于数据集本身的不平衡性,因此应当更多的参考AUC得分及其他三项指标。
在初步建立的三大模型中,可以看出三项评估指标对于正、负样本的得分有较大差异,主要表现对于负例的得分较高,而正例的得分较低。即模型对于负样本的覆盖率及分类精准度较高,而对于正样本的分类能力较弱。
总结,我们所建立的初步模型,虽然对于测试集中的样本分类表现良好,但从分类的覆盖率来说,倾向于覆盖更多的负样本,而未能覆盖正样本。
六、模型优化及改进
从上面得出的结论,目前构建的三大基础模型存在以下问题:
1、由于原始数据分布不平衡,因此造成三大初级模型对正负样本具有不同的偏好性,即对于正样本分类能力较差。
2、经过上面得出的准确率比较后,三大模型中表现最好的为朴素贝叶斯模型,为尝试更高的精确度,我们可以考虑采用集成学习(Stacking Classifier)进一步提高分类能力。
针对目前存在的第一类问题,在此引入SMOTE过采样方法,其定义如下:
SMOTE全称是Synthetic Minority Oversampling Technique,即合成少数类过采样技术,它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General),SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。
用Smote过采样解决样本分布不平衡的问题,这里以逻辑回归模型为例:
from imblearn.over_sampling import SMOTE os = SMOTE(random_state=0) X_train, X_test, y_train, y_test = train_test_split(df_data, df_target, test_size=0.3, random_state=0) columns = X_train.columns os_data_X,os_data_y=os.fit_sample(X_train, y_train) os_data_X = pd.DataFrame(data=os_data_X,columns=columns ) os_data_y= pd.DataFrame(data=os_data_y,columns=[‘y’]) print(“过采样以后的数据量: ”,len(os_data_X)) print(“未开户的用户数量: ”,len(os_data_y[os_data_y[‘y’]==0])) print(“开户的用户数量: ”,len(os_data_y[os_data_y[‘y’]==1])) print(“未开户的用户数量的百分比: ”,len(os_data_y[os_data_y[‘y’]==0])/len(os_data_X)) print(“开户的用户数量的百分比: ”,len(os_data_y[os_data_y[‘y’]==1])/len(os_data_X)) #上述步骤完成过采样,现在开始使用过采样后的样本训练逻辑回归模型 logreg_smote = LogisticRegression( C=0.01,solver = ‘sag’) logreg_smote.fit(os_data_X,os_data_y.values.reshape(-1)) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(logreg_smote.score(X_test, y_test))) print (“nn ---逻辑回归---”) log_roc_auc = roc_auc_score(y_test, logreg_smote.predict(X_test)) print (“逻辑回归 AUC = %2.2f” % log_roc_auc) print(classification_report(y_test, logreg_smote.predict(X_test))) fprl_gnb, tprl_gnb, thresholdsl_gnb = roc_curve(y_test, logreg_smote.predict_proba(X_test)[:,1]) plt.figure() plt.plot(fprl_gnb, tprl_gnb, color = ‘yellow’,label=‘Log Model (area = %0.2f)’ % log_roc_auc) plt.plot([0, 1], [0, 1],‘r--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘Log_ROC’) plt.show()
从上面结果看来,通过SMOTE采样,使得逻辑回归模型的AUC得分从0.63变化为0.77,可认为在较大程度上提高了模型的分类能力。
下面用朴素贝叶斯模型训练采样处理后的数据。
#上述步骤完成过采样,现在开始使用过采样后的样本训练朴素贝叶斯模型 gnb_smote = GaussianNB() gnb_smote.fit(os_data_X,os_data_y.values.reshape(-1)) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(gnb_smote.score(X_test, y_test))) print (“nn ---朴素贝叶斯---”) gnb_roc_auc = roc_auc_score(y_test, gnb_smote.predict(X_test)) print (“朴素贝叶斯 AUC = %2.2f” % gnb_roc_auc) print(classification_report(y_test, gnb_smote.predict(X_test))) fprl_gnb, tprl_gnb, thresholdsl_gnb = roc_curve(y_test, gnb_smote.predict_proba(X_test)[:,1]) ### Plot the ROC curves plt.figure() plt.plot(fpr1_gnb, tpr1_gnb, color = ‘blue’,label=‘GNB Model (area = %0.2f)’ % gnb_roc_auc) plt.plot([0, 1], [0, 1],‘r--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘GNB_ROC’) plt.show()
可以看到用朴素贝叶斯训练采样处理过的数据效果没有逻辑斯特好。
针对第二类问题,我们尝试使用集成模型来提高预测的性能,将上面所说的三大模型用作基础模型进行集成,所用工具为sklearn中的StackingClassifier:
在此简单介绍StackingClassifier思想:
Stacking 是一种集合学习技术,通过元分类器组合多个分类模型。基于完整训练集训练各个分类模型; 然后,基于整体中的各个分类模型的输出 - 元特征来拟合元分类器。元分类器可以根据预测类标签或来自集合的概率进行训练。
代码实现如下:
from mlxtend.classifier import StackingClassifier stregr1 = StackingClassifier(classifiers=[gnb, xgb], meta_classifier=lg,use_probas=True) ##选用gnb xgb用作第一层模型,log作为第二层模型 stregr1.fit(X_train, y_train) stregr1.score(X_test,y_test) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(stregr1.score(X_test, y_test))) print (“nn ---Ensemble_1---”) Ensemble_2_roc_auc = roc_auc_score(y_test, stregr1.predict(X_test)) print (“Ensemble_1_AUC = %2.2f” % Ensemble_2_roc_auc) print(classification_report(y_test, stregr1.predict(X_test))) accuracy_Ensemble_2 = accuracy_score(y_test,stregr.predict(X_test)) fpr_e2, tpr_e2, thresholds_e2 = roc_curve(y_test, stregr1.predict_proba(X_test)[:,1]) ### Plot the ROC curves plt.figure() plt.plot(fpr_e2, tpr_e2, label=‘ Ensemble Model (area = %0.2f)’ % Ensemble_2_roc_auc) plt.plot([0, 1], [0, 1],‘--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘Ensemble_2_ROC’) plt.show()
上面是用原始数据训练的集成模型,下面我们用采样处理后的数据训练看看效果。
stregr1.fit(os_data_X,os_data_y.values.reshape(-1)) stregr1.score(X_test,y_test) print(‘在测试数据集上面的预测准确率: {:.2f}’.format(stregr1.score(X_test, y_test))) print (“nn ---Ensemble_1_smote---”) Ensemble_2_roc_auc = roc_auc_score(y_test, stregr1.predict(X_test)) print (“Ensemble_1_smote_AUC = %2.2f” % Ensemble_2_roc_auc) print(classification_report(y_test, stregr1.predict(X_test))) accuracy_Ensemble_2 = accuracy_score(y_test,stregr1.predict(X_test)) fpr_e2, tpr_e2, thresholds_e2 = roc_curve(y_test, stregr1.predict_proba(X_test)[:,1]) ### Plot the ROC curves plt.figure() plt.plot(fpr_e2, tpr_e2, label=‘ Ensemble Model (area = %0.2f)’ % Ensemble_2_roc_auc) plt.plot([0, 1], [0, 1],‘--’) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel(‘False Positive Rate’) plt.ylabel(‘True Positive Rate’) plt.title(‘Receiver operating characteristic’) plt.legend(loc=“lower right”) plt.savefig(‘Ensemble_2_ROC’) plt.show()
效果不如用原始数据训练的。
七、提交结果
# coding=UTF-8 # 利用现有模型训练 data_X_test = dt_data # data_X_test.head() test_preds = logreg_smote.predict(data_X_test) np.savetxt(‘logreg_smote_result.csv’,np.c_[df_2[“ID_code”].values,test_preds],delimiter=‘,’,header=‘ID_code,target’,comments=‘’,fmt=‘%s’) test_preds = gnb_smote.predict(data_X_test) np.savetxt(‘gnb_smote_result.csv’,np.c_[df_2[“ID_code”].values,test_preds],delimiter=‘,’,header=‘ID_code,target’,comments=‘’,fmt=‘%s’) test_preds = stregr1.predict(data_X_test) np.savetxt(‘stregr1result.csv’,np.c_[df_2[“ID_code”].values,test_preds],delimiter=‘,’,header=‘ID_code,target’,comments=‘’,fmt=‘%s’) 这里提交了 采样数据训练的逻辑斯特模型,采样数据训练的朴素贝叶斯模型,原始数据训练的集成模型。
可以看到用采样处理后的数据训练的逻辑斯特模型效果较好。但准确率还不够,后面还得进一步提升,第一名的score都到0.92727,继续学习,提升准确率。
举报
更多回帖
rotate(-90deg);
回复
相关问答
曲线
AUC
分类器
PCB板的线宽与电流
有
何
关系
2021-10-08
2851
红外LED的电流与光强之间
有
何
关系
2021-09-29
3012
常用电感封装与电流
有
何
关系
2021-10-09
3237
正弦交流电电压电流峰值与有效
值
有
何
关系
2021-10-14
2883
线电流和相电流之间
有
何
关系
2021-09-22
3016
梯形波电流的峰值与平均值
有
何
关系
2021-09-30
5426
PCB板的走线宽度与电流
有
何
关系
2021-10-09
4257
无刷电机的极对数与转速
有
何
关系
?
2021-07-20
4586
相电流和线电流
有
何
关系
2021-09-28
8566
电阻与电导
有
何
关系
2021-09-27
2657
发帖
登录/注册
20万+
工程师都在用,
免费
PCB检查工具
无需安装、支持浏览器和手机在线查看、实时共享
查看
点击登录
登录更多精彩功能!
首页
论坛版块
小组
免费开发板试用
ebook
直播
搜索
登录
×
20
完善资料,
赚取积分

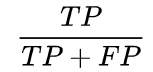
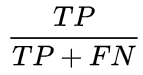
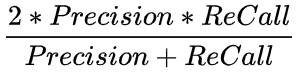

 举报
举报



