目标跟踪作为计算机视觉的一个极具挑战性的研究任务,已被广泛的应用在人机交互、智能监控、医学图像处理等领域中。目标跟踪的本质是在图像序列中识别出目标的同时对其进行精确定位。为了克服噪声、遮挡、背景的改变等对目标识别带来的困难,出现了很多的跟踪算法。
因为目标跟踪算法需要处理的数据量大、运算复杂,需要性能强大的处理器才能实时处理。我们选用TI推出的最新产品TMS320DM6446实现算法。TMS320DM6446是一款高度集成的片上系统,集成了可以运行频率高达594MHz的C64x+ DSP核和297MHz的ARM926处理器核。另外它还集成了数字视频所需的许多外部组件,如视频加速器,网络外设及高速外部存储接口。本设计充分利用DM6446的强大运算能力,在DSP内核上实时运行目标跟踪算法。 设计还在ARM处理器上执行多线程应用程序,负责视频采集,显示,网络通信,外围器件控制等工作。
算法介绍
本系统实现的视频跟踪算法可参考文献-,整个算法分为基本算法和改进算法两部分。本算法是一种基于模板匹配技术的跟踪算法,即在手工选定或自动选定了待跟踪目标后,提取目标的外观信息作为模板,在后续的视频序列中,将候选图像区域与目标模板进行匹配,将最相似的图像区域作为运动目标当前的位置。在本文中,采用结构相似度,即“归一化互相关系数”作为候选区域与目标模板相似程度的度量标准,其计算公式如下所示:
上式中,f(m,n)和g(m,n)分别为目标模板和候选区域的灰度值矩阵,尺寸为MxN。uf和ug分别为目标模板和候选区域的灰度平均值,然后再求出f(m,n)和g(m,n)的协方差、f(m,n)的方差、g(m,n)的方差后,求出归一化互相关系数。式(1)通过从灰度值矩阵中减去灰度均值,有效地消除了光照给跟踪结果带来的影响。而对于匹配图像区域的搜索,为了达到减少匹配次数从而降低计算量的目的,我们借鉴了视频压缩领域中的三步搜索法(Three Step Search, TSS) 作为最匹配点的搜索算法。
为了增加模板匹配视频目标跟踪算法的鲁棒性,我们在基本算法的基础上实现了改进算法的部分。改进算法具有自适应遮挡处理与模板漂移抑制的能力,能够很好地解决前面提到模板匹配的视频目标跟踪算法需要解决的难题。具体来说,主要有如下四点改进:(1) 抑制漂移的带掩蔽卡尔曼外观滤波算法(Drift-Inhibitive Masked Kalman Appearance Filter, DIMKAF ) ;(2) 内容自适应渐进式遮挡分析算法(Content-Adaptive Progressive Occlusion Analysis, CAPOA);(3) 可变掩蔽模板匹配算法(Variant-Mask Template Matching, VMTM);(4) 局部最优匹配鉴定算法(Local Best Match Authentication, LBMA)。 改进后整个算法的流程图如下所示:
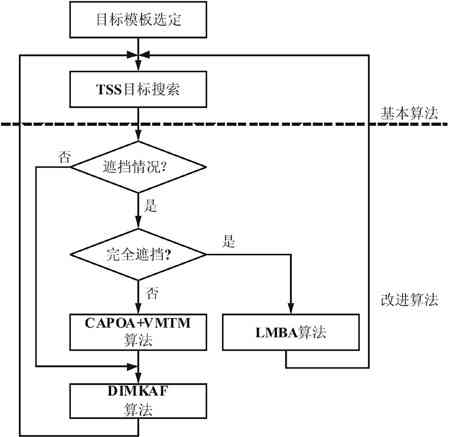
图 1 跟踪算法主流程图
算法在DavinciSOC上的实现
DSP平台的选择
DM6446采用ARM与DSP 双核结构,其中ARM子系统搭载297 MHz主频的ARM926 核,DSP部分则采用594 MHz的C64x+DSP核,外围存储均支持256 MB DDR2 RAM和各类存储卡,另外使用了VPSS 子系统丰富的视频前后处理功能,且都配备了完善的外设接口。目标跟踪算法需要做大量运算,DM6446 DSP核强大的运算处理能力保证了算法的实时处理。同时DM6446的ARM核可以进行系统管理,数据读写,网络传输等处理。
我们使用Spectrum Digital公司的DVEVM平台进行算法仿真、原型制作和软件优化。DVEVM?还可实现视频输入/输出连接、网络接口、存储器接口以及标准的子卡连接等。
系统软件框架
整个系统的软件框架如图2如示。DM6446的ARM核运行基于Linux操作系统的应用程序,所用的外围设备都由ARM负责控制。ARM端的HTTP服务器通过Linux网络协议栈来处理HTTP请求,并发送压缩视频数据。视频跟踪的应用程序由五个POSIX线程组成,分别是视频捕捉线程,视频跟踪线程,视频压缩线程,显示线程,系统控制线程。视频捕捉线程通过V4L2接口设备驱动从摄像头读取原始视频数据。视频跟踪线程把视频数据送到ARM和DSP的共享缓冲内存,并通知DSP执行跟踪算法。压缩线程负责控制DSP侧的压缩算法并从共享内存中读取压缩数据。视频显示线程从视频缓存中读取视频数据帧,并叠加目标跟踪框,最后通过Frame Buffer设备驱动输出显示。系统控制线程负责响应遥控器和鼠标并执行相应操作。
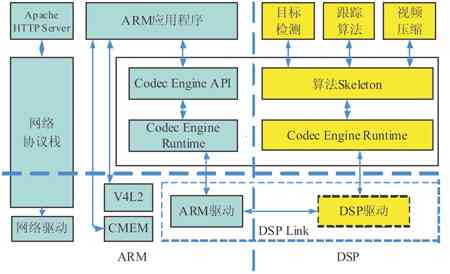
图 2 软件结构图
DM6446的DSP核上运行DSP/BIOS实时操作系统和目标检测,跟踪算法,视频压缩算法。所有的算法的接口都符合TI xDAIS标准,由Codec Engine调用。除了算法,DSP核上还集成了管理内存和DMA的Framework Component。
ARM核和DSP核的通信由TI提供的Codec Engine软件框架负责。Codec Engine是介于应用程序和具体算法之间的软件模块,其中的VISA API通过stub和skeleton访问Engine SPI最终调用算法。ARM和DSP的所用共享缓冲内存都是通过CMEM模块在DDR中分配的,缓冲内存地址连续且与DSP核Cache对齐。
跟踪算法在DSP上的优化
为了充分发挥出Davinci SOC强大的视频处理能力,满足实时跟踪的需要,我们通过算法优化和编程优化相结合的方法对Codec程序进行了大量的优化。
算法优化
算法优化是指在不降低算法性能的情况下,采用等效算法来降低计算量,我们的工作主要集中在“归一化互相关系数”的计算例程的简化上。根据均值和方差的性质,我们可以将(1)式化简为:
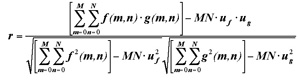
上式与式(1)比较,减少了大量的加减法计算,而且将方差和协方差的计算转化为大量的乘加运算,这为我们后面的编程优化也提供了极大的便利。例如M=64, ,加法次数从36864减少到12288。
编程优化
编程优化是在计算量不变的情况下,根据Davinci处理器DSP核心的特点,通过优化存储器的存取效率和提高程序的并行化程度来缩短程序运行所需要的指令周期数,以使程序运行得更快。我们的编程优化工作主要包含使用dsplib、使用线性汇编、使用内联函数以及循环展开等五个方面,下面将一一加以介绍。
dsplib的使用
在优化过程中,我们还采用了CCS中提供的库函数来对代码进行优化。CCS中针对c64x+ DSP提供了高度优化的dsplib库函数供用户使用,这些库函数提供了数字信号处理中常见的处理例程,而且由汇编语言写成,具有极高效的代码效率。特别是用于计算向量内积的DSP_dotprod和DSP_vecsumsq函数正好满足了我们的计算需求。在计算尺寸为32x32的“归一化互相关系数”时,优化后计算
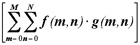
部分只需要271个DSP时钟周期,而计算
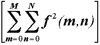
和部分只需要267个DSP时钟周期,这大大提高了程序运行的速度。
线性汇编
对于uf和ug的计算,如果使用for循环实现,将会大大拖累整个“归一化互相关系数”计算例程的执行效率。我们用手工编写线性汇编代码的方式实现了dspsum函数,利用C64x + DSP中的8个并行计算单元,在每个DSP
时钟周期内同时进行4个16位加16位的加法操作,对于尺寸为32x32的求和计算而言,该函数只需要258个DSP时钟周期。
内联函数的使用
C64x+编译器提供的内联函数可快速优化C代码。内联函数是直接映射为内联的C64x+指令的特殊函数,内联函数用前下滑线(_)来表示,使用时同调用普通函数一样使用它。我们在优化过程中,使用了许多内联函数,如_round()等,大大提高了代码的执行效率。
循环展开
由于for技术循环需要打断C64x+ DSP内部的软件流水线,而频繁的for循环会大大降低DSP的处理效率,所以我们在优化过程中,将部分for循环进行了展开,以代码增加为代价提高了代码的执行效率。通过上述方法,可将代码的处理效率提高3-5倍。
测试结果
为了获得视频跟踪算法Codec运行所需要的DSP时钟周期数,进而估计出优化后的算法代码是否已经满足实时跟踪的需要,我们使用CCStudio v3.3对同一测试序列,同一起始目标位置,不同大小模板的情况进行了离线仿真。
表 1 视频跟踪算法优化结果
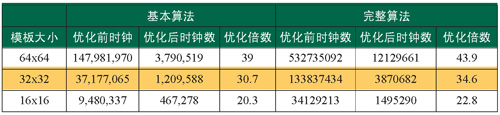
表 2 DSP负载测试

结论
我们在基于双核DM6446的系统平台上,利用改进后的跟踪算法实现了智能目标跟踪系统。DM6446 ARM核上的Linux操作系统上的多线程程序负责视频采集、视频显示、算法控制、外围设备处理等任务。通过在TI Codec Engine软件架构下扩展目标跟踪算法的接口,我们成功在DM6446的DSP核上运行了跟踪算法。经过算法优化和编程优化,系统可以对采集输入的25fps,720×480分辨率视频中的128×128大小的目标进行实时跟踪。实验结果表明,该算法可以成功跟踪目标,并具有较强的鲁棒性。该技术将会在智能视频监控、智能用户接口、基于对象的视频压缩、巡航导弹末端制导和辅助驾驶等领域有广泛应用前景。
目标跟踪作为计算机视觉的一个极具挑战性的研究任务,已被广泛的应用在人机交互、智能监控、医学图像处理等领域中。目标跟踪的本质是在图像序列中识别出目标的同时对其进行精确定位。为了克服噪声、遮挡、背景的改变等对目标识别带来的困难,出现了很多的跟踪算法。
因为目标跟踪算法需要处理的数据量大、运算复杂,需要性能强大的处理器才能实时处理。我们选用TI推出的最新产品TMS320DM6446实现算法。TMS320DM6446是一款高度集成的片上系统,集成了可以运行频率高达594MHz的C64x+ DSP核和297MHz的ARM926处理器核。另外它还集成了数字视频所需的许多外部组件,如视频加速器,网络外设及高速外部存储接口。本设计充分利用DM6446的强大运算能力,在DSP内核上实时运行目标跟踪算法。 设计还在ARM处理器上执行多线程应用程序,负责视频采集,显示,网络通信,外围器件控制等工作。
算法介绍
本系统实现的视频跟踪算法可参考文献-,整个算法分为基本算法和改进算法两部分。本算法是一种基于模板匹配技术的跟踪算法,即在手工选定或自动选定了待跟踪目标后,提取目标的外观信息作为模板,在后续的视频序列中,将候选图像区域与目标模板进行匹配,将最相似的图像区域作为运动目标当前的位置。在本文中,采用结构相似度,即“归一化互相关系数”作为候选区域与目标模板相似程度的度量标准,其计算公式如下所示:
上式中,f(m,n)和g(m,n)分别为目标模板和候选区域的灰度值矩阵,尺寸为MxN。uf和ug分别为目标模板和候选区域的灰度平均值,然后再求出f(m,n)和g(m,n)的协方差、f(m,n)的方差、g(m,n)的方差后,求出归一化互相关系数。式(1)通过从灰度值矩阵中减去灰度均值,有效地消除了光照给跟踪结果带来的影响。而对于匹配图像区域的搜索,为了达到减少匹配次数从而降低计算量的目的,我们借鉴了视频压缩领域中的三步搜索法(Three Step Search, TSS) 作为最匹配点的搜索算法。
为了增加模板匹配视频目标跟踪算法的鲁棒性,我们在基本算法的基础上实现了改进算法的部分。改进算法具有自适应遮挡处理与模板漂移抑制的能力,能够很好地解决前面提到模板匹配的视频目标跟踪算法需要解决的难题。具体来说,主要有如下四点改进:(1) 抑制漂移的带掩蔽卡尔曼外观滤波算法(Drift-Inhibitive Masked Kalman Appearance Filter, DIMKAF ) ;(2) 内容自适应渐进式遮挡分析算法(Content-Adaptive Progressive Occlusion Analysis, CAPOA);(3) 可变掩蔽模板匹配算法(Variant-Mask Template Matching, VMTM);(4) 局部最优匹配鉴定算法(Local Best Match Authentication, LBMA)。 改进后整个算法的流程图如下所示:
图 1 跟踪算法主流程图
算法在DavinciSOC上的实现
DSP平台的选择
DM6446采用ARM与DSP 双核结构,其中ARM子系统搭载297 MHz主频的ARM926 核,DSP部分则采用594 MHz的C64x+DSP核,外围存储均支持256 MB DDR2 RAM和各类存储卡,另外使用了VPSS 子系统丰富的视频前后处理功能,且都配备了完善的外设接口。目标跟踪算法需要做大量运算,DM6446 DSP核强大的运算处理能力保证了算法的实时处理。同时DM6446的ARM核可以进行系统管理,数据读写,网络传输等处理。
我们使用Spectrum Digital公司的DVEVM平台进行算法仿真、原型制作和软件优化。DVEVM?还可实现视频输入/输出连接、网络接口、存储器接口以及标准的子卡连接等。
系统软件框架
整个系统的软件框架如图2如示。DM6446的ARM核运行基于Linux操作系统的应用程序,所用的外围设备都由ARM负责控制。ARM端的HTTP服务器通过Linux网络协议栈来处理HTTP请求,并发送压缩视频数据。视频跟踪的应用程序由五个POSIX线程组成,分别是视频捕捉线程,视频跟踪线程,视频压缩线程,显示线程,系统控制线程。视频捕捉线程通过V4L2接口设备驱动从摄像头读取原始视频数据。视频跟踪线程把视频数据送到ARM和DSP的共享缓冲内存,并通知DSP执行跟踪算法。压缩线程负责控制DSP侧的压缩算法并从共享内存中读取压缩数据。视频显示线程从视频缓存中读取视频数据帧,并叠加目标跟踪框,最后通过Frame Buffer设备驱动输出显示。系统控制线程负责响应遥控器和鼠标并执行相应操作。
图 2 软件结构图
DM6446的DSP核上运行DSP/BIOS实时操作系统和目标检测,跟踪算法,视频压缩算法。所有的算法的接口都符合TI xDAIS标准,由Codec Engine调用。除了算法,DSP核上还集成了管理内存和DMA的Framework Component。
ARM核和DSP核的通信由TI提供的Codec Engine软件框架负责。Codec Engine是介于应用程序和具体算法之间的软件模块,其中的VISA API通过stub和skeleton访问Engine SPI最终调用算法。ARM和DSP的所用共享缓冲内存都是通过CMEM模块在DDR中分配的,缓冲内存地址连续且与DSP核Cache对齐。
跟踪算法在DSP上的优化
为了充分发挥出Davinci SOC强大的视频处理能力,满足实时跟踪的需要,我们通过算法优化和编程优化相结合的方法对Codec程序进行了大量的优化。
算法优化
算法优化是指在不降低算法性能的情况下,采用等效算法来降低计算量,我们的工作主要集中在“归一化互相关系数”的计算例程的简化上。根据均值和方差的性质,我们可以将(1)式化简为:
上式与式(1)比较,减少了大量的加减法计算,而且将方差和协方差的计算转化为大量的乘加运算,这为我们后面的编程优化也提供了极大的便利。例如M=64, ,加法次数从36864减少到12288。
编程优化
编程优化是在计算量不变的情况下,根据Davinci处理器DSP核心的特点,通过优化存储器的存取效率和提高程序的并行化程度来缩短程序运行所需要的指令周期数,以使程序运行得更快。我们的编程优化工作主要包含使用dsplib、使用线性汇编、使用内联函数以及循环展开等五个方面,下面将一一加以介绍。
dsplib的使用
在优化过程中,我们还采用了CCS中提供的库函数来对代码进行优化。CCS中针对c64x+ DSP提供了高度优化的dsplib库函数供用户使用,这些库函数提供了数字信号处理中常见的处理例程,而且由汇编语言写成,具有极高效的代码效率。特别是用于计算向量内积的DSP_dotprod和DSP_vecsumsq函数正好满足了我们的计算需求。在计算尺寸为32x32的“归一化互相关系数”时,优化后计算
部分只需要271个DSP时钟周期,而计算
和部分只需要267个DSP时钟周期,这大大提高了程序运行的速度。
线性汇编
对于uf和ug的计算,如果使用for循环实现,将会大大拖累整个“归一化互相关系数”计算例程的执行效率。我们用手工编写线性汇编代码的方式实现了dspsum函数,利用C64x + DSP中的8个并行计算单元,在每个DSP
时钟周期内同时进行4个16位加16位的加法操作,对于尺寸为32x32的求和计算而言,该函数只需要258个DSP时钟周期。
内联函数的使用
C64x+编译器提供的内联函数可快速优化C代码。内联函数是直接映射为内联的C64x+指令的特殊函数,内联函数用前下滑线(_)来表示,使用时同调用普通函数一样使用它。我们在优化过程中,使用了许多内联函数,如_round()等,大大提高了代码的执行效率。
循环展开
由于for技术循环需要打断C64x+ DSP内部的软件流水线,而频繁的for循环会大大降低DSP的处理效率,所以我们在优化过程中,将部分for循环进行了展开,以代码增加为代价提高了代码的执行效率。通过上述方法,可将代码的处理效率提高3-5倍。
测试结果
为了获得视频跟踪算法Codec运行所需要的DSP时钟周期数,进而估计出优化后的算法代码是否已经满足实时跟踪的需要,我们使用CCStudio v3.3对同一测试序列,同一起始目标位置,不同大小模板的情况进行了离线仿真。
表 1 视频跟踪算法优化结果
表 2 DSP负载测试
结论
我们在基于双核DM6446的系统平台上,利用改进后的跟踪算法实现了智能目标跟踪系统。DM6446 ARM核上的Linux操作系统上的多线程程序负责视频采集、视频显示、算法控制、外围设备处理等任务。通过在TI Codec Engine软件架构下扩展目标跟踪算法的接口,我们成功在DM6446的DSP核上运行了跟踪算法。经过算法优化和编程优化,系统可以对采集输入的25fps,720×480分辨率视频中的128×128大小的目标进行实时跟踪。实验结果表明,该算法可以成功跟踪目标,并具有较强的鲁棒性。该技术将会在智能视频监控、智能用户接口、基于对象的视频压缩、巡航导弹末端制导和辅助驾驶等领域有广泛应用前景。

 举报
举报




