1 H.264/AVC的基本编码结构
与早期的视频编码标准相同,H.264/AVC标准没有明确定义一对完整的编解码器,而是定义了编码码流的语法和对码流进行解码的方法。H.264/AVC采用了与以往标准类似的运动估计/补偿+分块DCT变换的混合编码框架。
H.264/AVC采用“返回基本”的思想去开发高性能的视频编码标准,即采用现有的基本算法和结构,通过精心优化计算流程和方法来取得更好的视频编码性能。与现有的H.261,H.263标准相比,H.264保持了编码器的系统结构不变,主要包括四个步骤:
(1)把一帧图像划分为小块(Macro.Block及Block),每个小块包含很多像素点,把对整幅图像的编码分成对许多小块的处理。
(2)通过对图像块的变换、量化和熵编码(或变长编码),消除图像中的空间冗余。
(3)由于相邻的各帧图像存在很大的相似性(即时间冗余),所以只需要将相邻帧图像间的变化进行编码传送即可,这是通过运动搜索和运动补偿实现的。对每一个编码块,通过搜索上一编码帧(或之前的几帧)的相应位置来找到一个运动向量,这一向量将和帧间差值一起传送,用于这一图像块的编解码。
(4)残余编码:对于原始块和相应的预测块之间的差值进行变换、量化和熵编码,以去除当前帧剩下的空间冗余。
但是与以前的编码算法H.263相比,H.264加入了一些新的特性,以提高编码效率。这些特征如下:
(1)对于进行帧内编码的图像,不是直接对原始图像进行变换、量化和编码,而是首先采用多种不同的预测方法对图像进行预测,然后对差值进行上述处理,以取得更佳的编码效率。
(2)在运动搜索和运动补偿方面,H.264采用了从4x4到16×16共13种搜索块进行运动搜索,以提高匹配程度,采用1/4像素精度进行搜索,以提高搜索精度。另外,根据对编码延时的不同要求,H.264还可以对以前多个已编码帧进行运动搜索,以达到最佳效果。
(3)在变换编码方面,H.264采用了4×4的整数变换(ICT)代替DCT变换,整数变换的效果接近DCT,但运算量要少,而且在反变换过程中不会因计算精度的问题而引入误差。
(4)在熵编码过程中,H.264使用单一的变长编码(UVLC)和基于内容的上下文变长编码(CAVLC)进行编码。
2 编码结构的分层处理
H.264的编码结构在概念上分为两层。视频编码层(VideoCodingLayer,VCL)负责高效率的视频压缩能力;网络适配层(NetworkAdaptionLayer,NAL)负责网络的适配,即对不同网络要有不同的适应能力,例如以恰当方式对数据进行打包和传送。H.264编码器分层结构如图1所示。在VCL和NAL之间定义了一个基于分组方式的接口,打包和相应的信令属于NAL的一部分。这样,高效率编码和网络适应性的任务则分别由VCL,和NAL来完成。
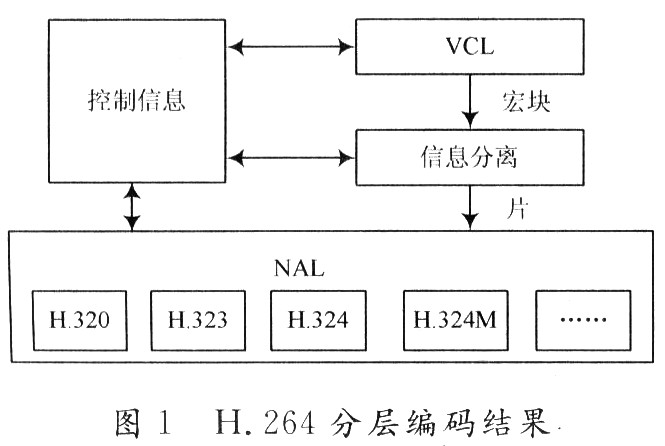
VCL包括基于块的运动补偿混合编码和一些新特性。NAL负责针对下层网络的特性对数据进行封装,包括成帧,发信号给逻辑信道,利用同步信息等。NAL从VCL获得数据,包括头信息、段结构信息和实际净荷信息(如果采用数据分割技术,净荷数据可能由几部分组成)。NAL的任务就是要正确地将它们映射到传输协议上。NAL下面是各种具体的协议,如H.323,H.324等。NAL层的引入大大提高了H.264适应复杂信道的能力。
JVT标准中的NAL定义了视频编解码器本身和外部的接口。它的基本单元是NALUs(NerworkAb-stractionLayerUnits)。这对实现许多现行网络包的传输方式提供了很好的支持。
一个NALU由一个一字节的头和包含特定类型句法元素的可变长度比特串组成。一个NALU可以包含slice的编码信息、随机访问点、参数集信息或补充增强信息等。NALU头结构如下:
NALU类型(T)是一个5比特的子段,指出该NALU单元是32种不同类型中的哪一种。类型1~12已被H.264定义,类型24~31可由H.264以外的其他标准使用。RTP载荷规范将采用其中的某些值来表示包聚合和包分割。其他值被保留待将来使用。
nal_reference_idc(R)用来标记该NALU在重建过程中的重要程度。0表示该NALU不会被用作参考帧,因此允许解码器或网关将之丢弃而不会引起错误传播。该值越高,表示该NALU中数据越重要。这就允许网络节点根据该值有力保护重要数据。
forbidden_zero_bit(F)在编码过程中置为0,当网络节点鉴别出NALU中的比特错误时,可以将该位置1。由于网络环境不同,解码器可能对包含比特错误的NALU采取不同的操作,有的则干脆丢弃。for-biddenzerobit为这种操作提供了便利。
一些使用包传输的网络能够直接使用NALUs,把他们直接作为H.223AL3SDUs或RTP包的载荷即可。然而,在一些面向码流的系统面前,如ITU-T的视频会议建议H.320和数字电视中的MPEG-2传输流等,需要比特或字节流的格式。因此,JVT标准定义了一种从NALUs到码流格式的变换,即把NALUs用起始码字封装起来,非常符合传统的视频编码标准,起始码的字长可以是16b或24b,这依赖于该NALU载荷的重要性。起始码字仅会出现在十字节对准的位置上,因此解码器可以扫描起始码字,用一种简单的u1向字节的内存复制操作把NALUs提取出来。
为了防止字节流格式中的起始码字发生竞争现象,许多视频编码标准都非常谨慎地采用熵编码方式。由于JVT标准包含两种不同的熵编码模式,所以这种起始码字很少发生竞争现象。JVT依靠一种字节填充机制,即通过在NALU中可能产生起始码字竞争的位置上插入非零字节来避免出现竞争现象。为方便网关设计,在一些看起来不必要的环境,尤其是包传输网络中仍然执行字节填充。由于VCL-NAL接口仅仅是概念上的,所以为防止起始码字竞争,操作习惯上将其作为VCL熵编码的一部分执行。
H.264视频流在误码、丢包多发的IP网络上传输,增强了H.264视频流的鲁棒性。为了减少传输差错,H.264视频流中的时间同步可以通过采用帧内图像刷新来完成。空间同步由条结构编码(SliceStruc-turedCoding)来支持,同时为了便于误码以后的再同步,在一帧的视频数据中还提供了一定的重同步点。另外,帧内宏块刷新和多参考帧模式可以使编码器在决定宏块模式时不仅考虑编码效率,还考虑传输信道的特性。H.264中还定义了数据分割模式:图像首先进行分段,段内宏块数据划分为宏块头信息、运动矢量和DCT系数三部分,且三部分之间由标识符分隔。这样,解码器可较方便地检测出受损数据的类型,减少误码对图像质量造成的损伤。这种数据分割的模式也利于信道编码时进行不等保护,即对重要的数据进行等级较高的保护。快速码率控制可通过在宏块层改变量化精度予以实现。
3nH.264的性能分析
通过实验来测试H.264的编码性能,并通过与H.263的比较,观察H.264的编码效率。
3.1nH.264与H.263编码性能比较
本试验对Grenadier Guards序列进行测试,分别对H.264和H.263编码的保真度、PSNR、宏块编码比特数进行比较,结果如下:
(1)保真度测试
通过残差比较可以很清楚地看出,H.264重构帧和参考帧的残差比较平滑,基本没有斑点;而H.263的残差比较明显,尤其是在人物附近,由于运动量大,H.263使用半像素运动矢量估计,而H.264提高到1/4像素,在1/4像素的基础上再内插,得到1/8像素精度的运动矢量,大大提高了图像编码的质量,如图2所示。

(2)PSNR测试(如图2)
相对于H.263视频编码标准,H.264在其增强预测编码内容的方法上做了改进,如场、帧编码的自适应选择;变尺寸方块的运动补偿;高精度的运动补偿;多参考帧运动补偿;加权预测;整数变换;自适应熵编码;环路去块滤波等,这些大大提高了H.264的PSNR。由图2可以看出,无论是亮度信号,还是色差信号,H.264的PSNR都比H.263的高。
(3)宏块编码比特数
下面对H.264和H.263进行更直观的比较,如图3所示,色条从蓝到红变化,表示比特数的逐渐增加。比较结果如图4,图5所示。

对GrerladieGuards序列中第3帧图像的宏块进行4×8编码,每一个宏块所用的比特数都可以清楚地看出。通过比较发现,H.264对宏块编码所用的比特数比H.263平均少50%。尤其在运动物体附近,效果更加明显,H.264使用了很多偏红的色块,而H.264更多的是偏蓝色块。基本静止的背景图案,两者也有很多的差别。由此可见,H.264中很多是深蓝色的宏块,所用的比特数在10比特左右,而H.263则偏向绿色,比特数在20比特左右。通过比较还发现,H.264的编码效率比H.263高很多。
3.2 H.264编码性能
3.2.1 多参考帧预测模式
对于多种类型的视频序列来说,多参考帧预测模式可以有效地提高编码性能,它通过在运动矢量中增加一个时域部分,而允许在宏块级下从若干参考帧中选择其中的一个。由于需要保持一个参考帧缓冲区域,因此增加了在编解码器中对内存的需求量。另外,额外参考帧的引入也使得搜索区域扩大,从而显著提高了编码器端在运动估计过程中计算的复杂度。本实验中Foreman视频序列使用UVLC熵编码,1/4像素运动矢量精度,搜索范围为16像素。
图6为使用不同参考帧数M对亮度分量峰值信噪比的影响。
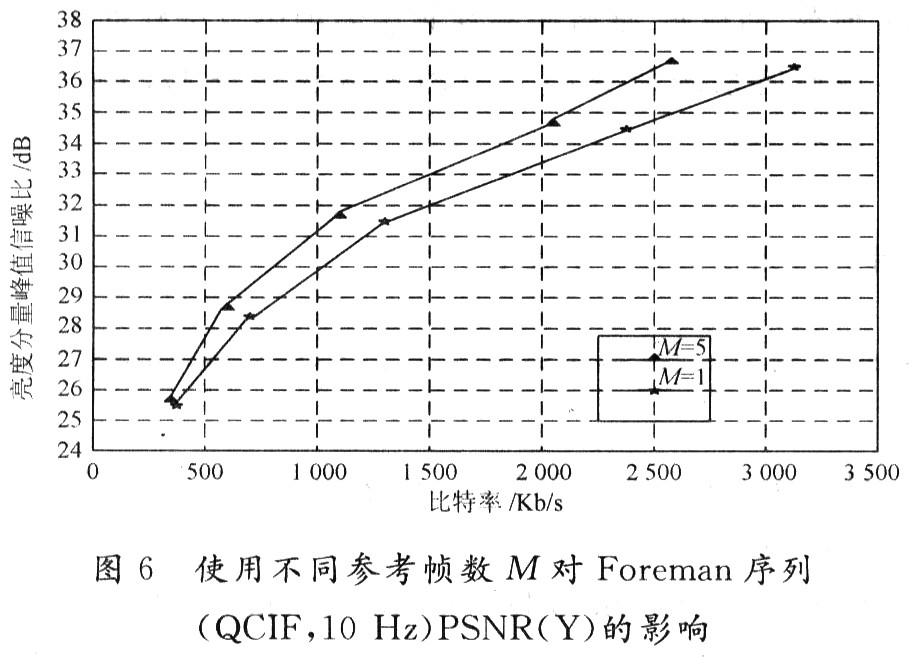
试验表明,多参考帧的使用,能平均节省10%的比特率。同样,多参考帧的使用也与具体的序列内容有关,高比特率的序列将大大提高图像的PSNR。
3.2.2 双向预测模式
H.264以前的视频编码标准一般都采用多假设预测模式,而H.264使用的双向预测模式,它是一对前向/后向预测帧的线性组合。前后向预测又都可以包含多个参考帧,同时,它又分为双向预测信号的独立估计和联合估计。其中,联合估计可以大大改进编码的效率。
本实验中Foreman视频序列使用UVLC熵编码,1/4像素运动矢量精度,搜索范围为16像素。图7为使用独立估计和联合估计对亮度分量峰值信噪比的影响。图7是重构B帧时帧比特率与亮度分量峰值信噪比的关系,选择5个前向预测帧和3个后向预测帧,则由图可以看出,联合估计的性能比独立估计的高。线性双向预测模式不仅利用了抑止噪声的组件,还提供了消除波峰的功能。假设当前帧中有一个物体将在后续帧中出现,而未在前面的帧中出现,那么,增加前向参考帧就不能提高编码效率,而增加后向参考帧就能大大提高编码效率。

3.2.3 熵编码
H.264有两种不同的熵编码模式:通用可变长编码(UVLC)和基于上下文的自适应二进制算术编码(CABAC)。UVLC只使用一个可变长的代码去编码所有二进制的语法元素,而CABAC则采用上下文模式和基于条件概率与符号统计的自适应算法。UVLC算法简单,在付出很低的计算成本时就能取得很好的压缩效率。CABAC计算复杂度高,但它能够大大节省比特率。
本实验中Foreman视频序列使用1/4像素运动矢量精度,搜索范围为16像素。图8为使用UVLC和CABAC对亮度分量峰值信噪比的影响。

试验表明,CABAC能大大降低比特率,在取得相同的亮度分量峰值信噪比时,CABAC比UVCL平均节省15%的比特率。在高比特率的序列中,常使用多参考帧和CABAC联合编码,多参考帧能提高运动估计补偿的效率,CABLC能自适应地根据上下文进行熵编码,从而大大提高编码器的性能。
4 结语
文章对新一代视频编码标准H.264/AVC进行全面的分析和研究,总体上按照H.264/AVC结构化的编码思想,对分视频编码层和网络适配层进行了分析,特别对H.264/AVC的编码中所采用的新技术进行了仿真研究,如编码的效率、多参考帧、通用可变长编码(UVLC)和基于上下文的自适应二进制算术编码(CABAC)、运动补偿等,并给出实验结果,充分说明了新一代视频编码标准H.264/AVc的编码效率比以前的编码标准(如H.263)在编码效率上提高了很多。当然,新一代视频编码标准H.264/AVc虽然优点明显,但许多优点是以牺牲计算复杂度换来的。因此在降低计算复杂度的同时,能达到更高的编码效率将是下一步研究的重点。
1 H.264/AVC的基本编码结构
与早期的视频编码标准相同,H.264/AVC标准没有明确定义一对完整的编解码器,而是定义了编码码流的语法和对码流进行解码的方法。H.264/AVC采用了与以往标准类似的运动估计/补偿+分块DCT变换的混合编码框架。
H.264/AVC采用“返回基本”的思想去开发高性能的视频编码标准,即采用现有的基本算法和结构,通过精心优化计算流程和方法来取得更好的视频编码性能。与现有的H.261,H.263标准相比,H.264保持了编码器的系统结构不变,主要包括四个步骤:
(1)把一帧图像划分为小块(Macro.Block及Block),每个小块包含很多像素点,把对整幅图像的编码分成对许多小块的处理。
(2)通过对图像块的变换、量化和熵编码(或变长编码),消除图像中的空间冗余。
(3)由于相邻的各帧图像存在很大的相似性(即时间冗余),所以只需要将相邻帧图像间的变化进行编码传送即可,这是通过运动搜索和运动补偿实现的。对每一个编码块,通过搜索上一编码帧(或之前的几帧)的相应位置来找到一个运动向量,这一向量将和帧间差值一起传送,用于这一图像块的编解码。
(4)残余编码:对于原始块和相应的预测块之间的差值进行变换、量化和熵编码,以去除当前帧剩下的空间冗余。
但是与以前的编码算法H.263相比,H.264加入了一些新的特性,以提高编码效率。这些特征如下:
(1)对于进行帧内编码的图像,不是直接对原始图像进行变换、量化和编码,而是首先采用多种不同的预测方法对图像进行预测,然后对差值进行上述处理,以取得更佳的编码效率。
(2)在运动搜索和运动补偿方面,H.264采用了从4x4到16×16共13种搜索块进行运动搜索,以提高匹配程度,采用1/4像素精度进行搜索,以提高搜索精度。另外,根据对编码延时的不同要求,H.264还可以对以前多个已编码帧进行运动搜索,以达到最佳效果。
(3)在变换编码方面,H.264采用了4×4的整数变换(ICT)代替DCT变换,整数变换的效果接近DCT,但运算量要少,而且在反变换过程中不会因计算精度的问题而引入误差。
(4)在熵编码过程中,H.264使用单一的变长编码(UVLC)和基于内容的上下文变长编码(CAVLC)进行编码。
2 编码结构的分层处理
H.264的编码结构在概念上分为两层。视频编码层(VideoCodingLayer,VCL)负责高效率的视频压缩能力;网络适配层(NetworkAdaptionLayer,NAL)负责网络的适配,即对不同网络要有不同的适应能力,例如以恰当方式对数据进行打包和传送。H.264编码器分层结构如图1所示。在VCL和NAL之间定义了一个基于分组方式的接口,打包和相应的信令属于NAL的一部分。这样,高效率编码和网络适应性的任务则分别由VCL,和NAL来完成。
VCL包括基于块的运动补偿混合编码和一些新特性。NAL负责针对下层网络的特性对数据进行封装,包括成帧,发信号给逻辑信道,利用同步信息等。NAL从VCL获得数据,包括头信息、段结构信息和实际净荷信息(如果采用数据分割技术,净荷数据可能由几部分组成)。NAL的任务就是要正确地将它们映射到传输协议上。NAL下面是各种具体的协议,如H.323,H.324等。NAL层的引入大大提高了H.264适应复杂信道的能力。
JVT标准中的NAL定义了视频编解码器本身和外部的接口。它的基本单元是NALUs(NerworkAb-stractionLayerUnits)。这对实现许多现行网络包的传输方式提供了很好的支持。
一个NALU由一个一字节的头和包含特定类型句法元素的可变长度比特串组成。一个NALU可以包含slice的编码信息、随机访问点、参数集信息或补充增强信息等。NALU头结构如下:
NALU类型(T)是一个5比特的子段,指出该NALU单元是32种不同类型中的哪一种。类型1~12已被H.264定义,类型24~31可由H.264以外的其他标准使用。RTP载荷规范将采用其中的某些值来表示包聚合和包分割。其他值被保留待将来使用。
nal_reference_idc(R)用来标记该NALU在重建过程中的重要程度。0表示该NALU不会被用作参考帧,因此允许解码器或网关将之丢弃而不会引起错误传播。该值越高,表示该NALU中数据越重要。这就允许网络节点根据该值有力保护重要数据。
forbidden_zero_bit(F)在编码过程中置为0,当网络节点鉴别出NALU中的比特错误时,可以将该位置1。由于网络环境不同,解码器可能对包含比特错误的NALU采取不同的操作,有的则干脆丢弃。for-biddenzerobit为这种操作提供了便利。
一些使用包传输的网络能够直接使用NALUs,把他们直接作为H.223AL3SDUs或RTP包的载荷即可。然而,在一些面向码流的系统面前,如ITU-T的视频会议建议H.320和数字电视中的MPEG-2传输流等,需要比特或字节流的格式。因此,JVT标准定义了一种从NALUs到码流格式的变换,即把NALUs用起始码字封装起来,非常符合传统的视频编码标准,起始码的字长可以是16b或24b,这依赖于该NALU载荷的重要性。起始码字仅会出现在十字节对准的位置上,因此解码器可以扫描起始码字,用一种简单的u1向字节的内存复制操作把NALUs提取出来。
为了防止字节流格式中的起始码字发生竞争现象,许多视频编码标准都非常谨慎地采用熵编码方式。由于JVT标准包含两种不同的熵编码模式,所以这种起始码字很少发生竞争现象。JVT依靠一种字节填充机制,即通过在NALU中可能产生起始码字竞争的位置上插入非零字节来避免出现竞争现象。为方便网关设计,在一些看起来不必要的环境,尤其是包传输网络中仍然执行字节填充。由于VCL-NAL接口仅仅是概念上的,所以为防止起始码字竞争,操作习惯上将其作为VCL熵编码的一部分执行。
H.264视频流在误码、丢包多发的IP网络上传输,增强了H.264视频流的鲁棒性。为了减少传输差错,H.264视频流中的时间同步可以通过采用帧内图像刷新来完成。空间同步由条结构编码(SliceStruc-turedCoding)来支持,同时为了便于误码以后的再同步,在一帧的视频数据中还提供了一定的重同步点。另外,帧内宏块刷新和多参考帧模式可以使编码器在决定宏块模式时不仅考虑编码效率,还考虑传输信道的特性。H.264中还定义了数据分割模式:图像首先进行分段,段内宏块数据划分为宏块头信息、运动矢量和DCT系数三部分,且三部分之间由标识符分隔。这样,解码器可较方便地检测出受损数据的类型,减少误码对图像质量造成的损伤。这种数据分割的模式也利于信道编码时进行不等保护,即对重要的数据进行等级较高的保护。快速码率控制可通过在宏块层改变量化精度予以实现。
3nH.264的性能分析
通过实验来测试H.264的编码性能,并通过与H.263的比较,观察H.264的编码效率。
3.1nH.264与H.263编码性能比较
本试验对Grenadier Guards序列进行测试,分别对H.264和H.263编码的保真度、PSNR、宏块编码比特数进行比较,结果如下:
(1)保真度测试
通过残差比较可以很清楚地看出,H.264重构帧和参考帧的残差比较平滑,基本没有斑点;而H.263的残差比较明显,尤其是在人物附近,由于运动量大,H.263使用半像素运动矢量估计,而H.264提高到1/4像素,在1/4像素的基础上再内插,得到1/8像素精度的运动矢量,大大提高了图像编码的质量,如图2所示。
(2)PSNR测试(如图2)
相对于H.263视频编码标准,H.264在其增强预测编码内容的方法上做了改进,如场、帧编码的自适应选择;变尺寸方块的运动补偿;高精度的运动补偿;多参考帧运动补偿;加权预测;整数变换;自适应熵编码;环路去块滤波等,这些大大提高了H.264的PSNR。由图2可以看出,无论是亮度信号,还是色差信号,H.264的PSNR都比H.263的高。
(3)宏块编码比特数
下面对H.264和H.263进行更直观的比较,如图3所示,色条从蓝到红变化,表示比特数的逐渐增加。比较结果如图4,图5所示。
对GrerladieGuards序列中第3帧图像的宏块进行4×8编码,每一个宏块所用的比特数都可以清楚地看出。通过比较发现,H.264对宏块编码所用的比特数比H.263平均少50%。尤其在运动物体附近,效果更加明显,H.264使用了很多偏红的色块,而H.264更多的是偏蓝色块。基本静止的背景图案,两者也有很多的差别。由此可见,H.264中很多是深蓝色的宏块,所用的比特数在10比特左右,而H.263则偏向绿色,比特数在20比特左右。通过比较还发现,H.264的编码效率比H.263高很多。
3.2 H.264编码性能
3.2.1 多参考帧预测模式
对于多种类型的视频序列来说,多参考帧预测模式可以有效地提高编码性能,它通过在运动矢量中增加一个时域部分,而允许在宏块级下从若干参考帧中选择其中的一个。由于需要保持一个参考帧缓冲区域,因此增加了在编解码器中对内存的需求量。另外,额外参考帧的引入也使得搜索区域扩大,从而显著提高了编码器端在运动估计过程中计算的复杂度。本实验中Foreman视频序列使用UVLC熵编码,1/4像素运动矢量精度,搜索范围为16像素。
图6为使用不同参考帧数M对亮度分量峰值信噪比的影响。
试验表明,多参考帧的使用,能平均节省10%的比特率。同样,多参考帧的使用也与具体的序列内容有关,高比特率的序列将大大提高图像的PSNR。
3.2.2 双向预测模式
H.264以前的视频编码标准一般都采用多假设预测模式,而H.264使用的双向预测模式,它是一对前向/后向预测帧的线性组合。前后向预测又都可以包含多个参考帧,同时,它又分为双向预测信号的独立估计和联合估计。其中,联合估计可以大大改进编码的效率。
本实验中Foreman视频序列使用UVLC熵编码,1/4像素运动矢量精度,搜索范围为16像素。图7为使用独立估计和联合估计对亮度分量峰值信噪比的影响。图7是重构B帧时帧比特率与亮度分量峰值信噪比的关系,选择5个前向预测帧和3个后向预测帧,则由图可以看出,联合估计的性能比独立估计的高。线性双向预测模式不仅利用了抑止噪声的组件,还提供了消除波峰的功能。假设当前帧中有一个物体将在后续帧中出现,而未在前面的帧中出现,那么,增加前向参考帧就不能提高编码效率,而增加后向参考帧就能大大提高编码效率。
3.2.3 熵编码
H.264有两种不同的熵编码模式:通用可变长编码(UVLC)和基于上下文的自适应二进制算术编码(CABAC)。UVLC只使用一个可变长的代码去编码所有二进制的语法元素,而CABAC则采用上下文模式和基于条件概率与符号统计的自适应算法。UVLC算法简单,在付出很低的计算成本时就能取得很好的压缩效率。CABAC计算复杂度高,但它能够大大节省比特率。
本实验中Foreman视频序列使用1/4像素运动矢量精度,搜索范围为16像素。图8为使用UVLC和CABAC对亮度分量峰值信噪比的影响。
试验表明,CABAC能大大降低比特率,在取得相同的亮度分量峰值信噪比时,CABAC比UVCL平均节省15%的比特率。在高比特率的序列中,常使用多参考帧和CABAC联合编码,多参考帧能提高运动估计补偿的效率,CABLC能自适应地根据上下文进行熵编码,从而大大提高编码器的性能。
4 结语
文章对新一代视频编码标准H.264/AVC进行全面的分析和研究,总体上按照H.264/AVC结构化的编码思想,对分视频编码层和网络适配层进行了分析,特别对H.264/AVC的编码中所采用的新技术进行了仿真研究,如编码的效率、多参考帧、通用可变长编码(UVLC)和基于上下文的自适应二进制算术编码(CABAC)、运动补偿等,并给出实验结果,充分说明了新一代视频编码标准H.264/AVc的编码效率比以前的编码标准(如H.263)在编码效率上提高了很多。当然,新一代视频编码标准H.264/AVc虽然优点明显,但许多优点是以牺牲计算复杂度换来的。因此在降低计算复杂度的同时,能达到更高的编码效率将是下一步研究的重点。

 举报
举报




