随着人们安全意识的提高,视频监视系统日益普及,现已广泛应用于机场、银行、公共交通中心乃至私人住宅中。但传统模拟系统存在诸多问题,这促使人们希望转而采用数字系统。此外,随着计算机网络、半导体及视频压缩技术的日益推广,新一代视频监视系统将无疑采用数字技术,并将实行标准化技术,支持IP 网络。
就因特网协议视频监视系统 ( VSIP) 而言,处理网络流量的硬件是摄像头系统的重要组成部分,因为视频信号要通过摄像头进行数字化、压缩处理,然后才传输到视频服务器,从而解决网络的带宽限制问题。 DSP/ GPP 等异构处理器架构有助于最大化系统性能。视频采集、存储和视频流都是中断密集型 (Interrupt intensive) 任务,我们可将其分配给 GPP 来处理,而高密度 MIPS 视频压缩工作则交给 DSP 去完成。数据传输给视频服务器后,服务器将压缩视频流作为文件存储在硬盘驱动器上,从而避免了像传统模拟存储设备那样出现视频质量下降问题。我们针对数字视频信号的压缩技术开发了多种标准,可分为以下两大类:
* 运动估算 (ME) 法:每 N 帧为一个图像组 ( GOP)。我们对图像组中的第一帧进行独立编码,而对其它 (N-1) 帧来说,我们只将当前帧与其前面已编码的帧(即前向参考帧)的时差加以编码。常用的标准为 MPEG-2、MPEG-4、H.263 及 H.264。
* 静态影像压缩法:每个视频帧作为静态影像独立编码。最常用的标准为 JPEG。MJPEG 标准采用JPEG 算法对每个帧进行编码。
运动估算法与静态影像压缩法的比较
图 1 显示了 H.264 编码器的结构图。与其它 ME 视频编码标准类似,H.264 编码器将输入影像分为多个16 x 16 像素的宏块 (MB) ,然后逐块处理。H.264 编码器包括正向路径和重构路径。正向路径将帧编码为比特位;重构路径从编码位中产生一个参考帧。下图中的 IDCT、IQ、 ME 和 MC分别代表(反向)离散余弦变换、(反向)量化、运动估算及运动补偿。

图 1:H.264 编码器结构图。
在正向路径中(从 DCT至 Q),每个宏块 (MB) 均可以帧内模式或帧间模式编码。在帧间模式下,运动估算 (ME) 模块将参考 MB 位于前面已编码的帧处;而在帧内模式下,参考MB 在当前帧中由采样形成。
重构路径 (从 IQ 至 IDCT)的目的是确保编码器和解码器采用相同的参考帧生成影像。否则就会累积编码器与解码器间的误差。

图 2:JPEG 编码器结构图。
图 2 给出了 JPEG 编码器结构图。该编码器将输入影像分为多个 8x8 像素的模块,然后逐个处理。每个模块首先通过 DCT 模块,随后量化器根据量化矩阵对 DCT 系数进行取整。在此过程中,编码质量与压缩比均可根据量化步骤调节。最后熵编码器对量化器输出进行编码,并生成 JPEG 影像。
由于连续视频帧通常包括大量相关信息,因此 ME 方法可实现更高的压缩比。举例来说,就每秒 30 帧的标准 NTSC 分辨率而言,H.264 编码器能以 2 mbps 的速度进行视频编码,从而实现了平均压缩比高达 60:1 的影像质量。在影像质量相同的情况下,MJPEG 的压缩比则为10:1 至 15:1。
MJPEG 相对于 ME 方法有如下几点优势。首先,JPEG 需要的计算量和功耗相对大幅降低。此外,大多数PC 都配置了 JPEG 影像专用的解码及显示软件。如果记录特定事件只需一幅或几幅影像,比如人通过门口,那么 MJPEG 的效率会更高。如果网络带宽没有保证,那么我们更倾向于采用 MJPEG 标准,因为某帧的丢失或延迟不会影响其它帧。而对于 ME 方法来说,某帧的延迟或丢失会导致整个 GOP 的延迟或丢失,因为只有获得前向参考帧 (previous reference frame) 才能对下一帧进行解码。
许多 VSIP 摄像头都有多个视频编码器,因此用户可根据具体应用要求选择最合适的视频编码器。某些摄像头甚至还能同时执行多种编解码器。MJPEG 对VSIP 摄像头的要求通常是最低的,几乎所有 VSIP 摄像头都可安装 JPEG 编码器。
MJPEG 标准的实施
在典型数字监视系统中,视频通过传感器采集、压缩,再以流媒体方式传输到视频服务器中。新型 DSP 架构上执行的视频编码器任务如果发生中断,就会出现问题,因为每次环境转换 (context switch) 都会导致大量寄存器存储和高速缓存释放。因此我们应采用异构架构,这样就能将 DSP 从视频采集和流媒体任务中解脱出来。以下结构图显示了视频监视应用中的 DSP/GPP 处理器架构实例。
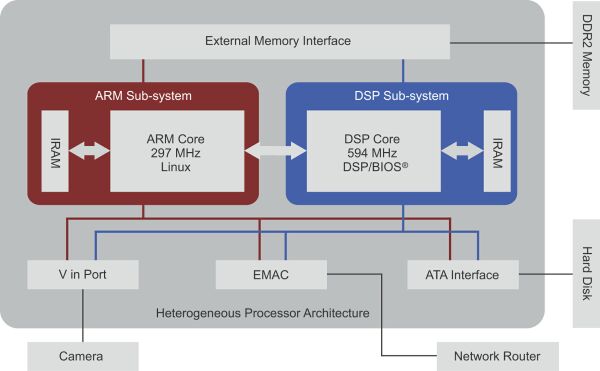
图 3:视频监视应用中的 DSP/GPP 处理器架构实例。
在DSP/GPP SoC系统中采用MJPEG 标准时,开发人员应首先适当拆分功能模块,以提高系统性能。
EMAC 驱动器、TCP/IP 网络栈和 HTTP 服务器协同工作,将压缩影像以流媒体形势输出。视频采集驱动器和 ATA 驱动器均应部署在 ARM 上,这样有助于减轻 DSP 的处理压力。而 JPEG 编码器应在部署在 DSP 的内核上,因为DSP VLIW 架构特别适用于这种计算强度大的工作。
一旦摄像头通过处理器上的视频输入端口采集到视频帧,原始影像就通过 JPEG 编码器压缩,随后将该压缩影像保存到设备硬盘上。

图 4:有关视频监视系统中基于 DaVinci 技术的 TI DM6446 数字视频评估板的 MJPEG 数据流演示。
我们通常用 PC 监控实时视频场景,首先检索出视频服务器中的流媒体,然后进行解码,最后在显示器上显示视频影像。编码的 JPEG 影像文件可由设备通过因特网检索,因此我们不仅可在一台 PC 上同时监控多个视频流,而且通过因特网能够从多个点同时查看这些被检索到的视频流。VSIP 局端通过 TCP/IP 网络能与视频服务器相连,而且可位于网络中任何位置。这与传统模拟系统相比,是一个巨大的进步。就算出了问题,也只影响一个数字摄像头,而不会影响局端。我们也可动态配置 JPEG影像质量,以满足不同视频质量要求。
优化JPEG编码器
JPEG 编码器的三大功能模块中,DCT 与量化器的计算任务较重。我们也可以注意到,就这两种模块而言,高度优化的汇编代码和未优化的 C 代码之间存在很大的性能差异,因此有必要对这两个模块进行优化。
优化 2D 8x8 DCT功能模块有助于减少加、减、乘等运算次数,避免原始方程式的冗余计算。目前已推出了众多快速 DCT 算法,其中陈氏算法 (Chen’s algorithm) 广为业界采用。就 2D 8x8 DCT 而言,陈氏算法需要进行 448 次加减运算以及 224 次乘法运算。
加减法和乘法功能块可进一步拆分为多个功能单元(均部署在 DSP 内核上),以执行并行指令并提高性能。在开销忽略不计的条件下,高度优化的 DSP 汇编代码能在 100 个循环之内顺利完成 2D DCT 计算任务。其它快速 DCT 算法要求的计算量更少,不过往往会要求更多缓冲区来保存中间计算结果。就采用管线 VLIW 架构的新型 DSP 而言,存储器数据存取工作量比乘法运算工作量大,因此开发人员在优化算法时应考虑计算与存储器存取之间的平衡问题。
每个像素的量化过程均需要进行乘法及加法运算。这种计算结果通常只需要 16 位的精确度即可,而 DSP 寄存器则需要 32 位。优化量化器模块的最初想法是在单个寄存器中存储 2 个像素,然后对这两个像素执行加法及乘法运算;第二种方法就是并行使用多个 DSP 功能单元。由于 TMS320DM6446 中的 DSP 内核有 2 个乘法器和 2 个加法器,因此我们可同时量化高达 4 个像素。最后但不是不重要的一种做法就是充分利用管线 DSP 架构。DSP 内核在量化当前 4 个像素时,可从存储器读取下一组“ 4 个像素”,这样每个循环都能向乘法器和加法器提供数据。前两种方法由开发人员亲自编写优化的 C 代码或汇编代码即可实现。管线代码可采用 DSP 编译器。
除了优化每个功能模块之外,我们还可采用乒乓 (PING-PONG) 缓冲技术来优化系统级 JPEG 编码器。DSP 内核存取内部 RAM(IRAM) 中的数据的速度比存取外部 DDR2 存储器中数据的速度快得多。但 IRAM 容量有限,不能满足整个输入帧的要求,因此同一时间在 IRAM 中只能处理一部分模块。处理乒乓集时,DMA 将乒乓集从 DDR2 传递至 IRAM,这样 DSP内核就能在完成当前工作后立即开始处理下面的数据。
显然,视频监视系统的数字化已经全面展开。了解视频压缩、系统分区和编解码器优化等技术,对开发新一代视频监视系统以满足不断增长的需求来说至关重要。
随着人们安全意识的提高,视频监视系统日益普及,现已广泛应用于机场、银行、公共交通中心乃至私人住宅中。但传统模拟系统存在诸多问题,这促使人们希望转而采用数字系统。此外,随着计算机网络、半导体及视频压缩技术的日益推广,新一代视频监视系统将无疑采用数字技术,并将实行标准化技术,支持IP 网络。
就因特网协议视频监视系统 ( VSIP) 而言,处理网络流量的硬件是摄像头系统的重要组成部分,因为视频信号要通过摄像头进行数字化、压缩处理,然后才传输到视频服务器,从而解决网络的带宽限制问题。 DSP/ GPP 等异构处理器架构有助于最大化系统性能。视频采集、存储和视频流都是中断密集型 (Interrupt intensive) 任务,我们可将其分配给 GPP 来处理,而高密度 MIPS 视频压缩工作则交给 DSP 去完成。数据传输给视频服务器后,服务器将压缩视频流作为文件存储在硬盘驱动器上,从而避免了像传统模拟存储设备那样出现视频质量下降问题。我们针对数字视频信号的压缩技术开发了多种标准,可分为以下两大类:
* 运动估算 (ME) 法:每 N 帧为一个图像组 ( GOP)。我们对图像组中的第一帧进行独立编码,而对其它 (N-1) 帧来说,我们只将当前帧与其前面已编码的帧(即前向参考帧)的时差加以编码。常用的标准为 MPEG-2、MPEG-4、H.263 及 H.264。
* 静态影像压缩法:每个视频帧作为静态影像独立编码。最常用的标准为 JPEG。MJPEG 标准采用JPEG 算法对每个帧进行编码。
运动估算法与静态影像压缩法的比较
图 1 显示了 H.264 编码器的结构图。与其它 ME 视频编码标准类似,H.264 编码器将输入影像分为多个16 x 16 像素的宏块 (MB) ,然后逐块处理。H.264 编码器包括正向路径和重构路径。正向路径将帧编码为比特位;重构路径从编码位中产生一个参考帧。下图中的 IDCT、IQ、 ME 和 MC分别代表(反向)离散余弦变换、(反向)量化、运动估算及运动补偿。
图 1:H.264 编码器结构图。
在正向路径中(从 DCT至 Q),每个宏块 (MB) 均可以帧内模式或帧间模式编码。在帧间模式下,运动估算 (ME) 模块将参考 MB 位于前面已编码的帧处;而在帧内模式下,参考MB 在当前帧中由采样形成。
重构路径 (从 IQ 至 IDCT)的目的是确保编码器和解码器采用相同的参考帧生成影像。否则就会累积编码器与解码器间的误差。
图 2:JPEG 编码器结构图。
图 2 给出了 JPEG 编码器结构图。该编码器将输入影像分为多个 8x8 像素的模块,然后逐个处理。每个模块首先通过 DCT 模块,随后量化器根据量化矩阵对 DCT 系数进行取整。在此过程中,编码质量与压缩比均可根据量化步骤调节。最后熵编码器对量化器输出进行编码,并生成 JPEG 影像。
由于连续视频帧通常包括大量相关信息,因此 ME 方法可实现更高的压缩比。举例来说,就每秒 30 帧的标准 NTSC 分辨率而言,H.264 编码器能以 2 mbps 的速度进行视频编码,从而实现了平均压缩比高达 60:1 的影像质量。在影像质量相同的情况下,MJPEG 的压缩比则为10:1 至 15:1。
MJPEG 相对于 ME 方法有如下几点优势。首先,JPEG 需要的计算量和功耗相对大幅降低。此外,大多数PC 都配置了 JPEG 影像专用的解码及显示软件。如果记录特定事件只需一幅或几幅影像,比如人通过门口,那么 MJPEG 的效率会更高。如果网络带宽没有保证,那么我们更倾向于采用 MJPEG 标准,因为某帧的丢失或延迟不会影响其它帧。而对于 ME 方法来说,某帧的延迟或丢失会导致整个 GOP 的延迟或丢失,因为只有获得前向参考帧 (previous reference frame) 才能对下一帧进行解码。
许多 VSIP 摄像头都有多个视频编码器,因此用户可根据具体应用要求选择最合适的视频编码器。某些摄像头甚至还能同时执行多种编解码器。MJPEG 对VSIP 摄像头的要求通常是最低的,几乎所有 VSIP 摄像头都可安装 JPEG 编码器。
MJPEG 标准的实施
在典型数字监视系统中,视频通过传感器采集、压缩,再以流媒体方式传输到视频服务器中。新型 DSP 架构上执行的视频编码器任务如果发生中断,就会出现问题,因为每次环境转换 (context switch) 都会导致大量寄存器存储和高速缓存释放。因此我们应采用异构架构,这样就能将 DSP 从视频采集和流媒体任务中解脱出来。以下结构图显示了视频监视应用中的 DSP/GPP 处理器架构实例。
图 3:视频监视应用中的 DSP/GPP 处理器架构实例。
在DSP/GPP SoC系统中采用MJPEG 标准时,开发人员应首先适当拆分功能模块,以提高系统性能。
EMAC 驱动器、TCP/IP 网络栈和 HTTP 服务器协同工作,将压缩影像以流媒体形势输出。视频采集驱动器和 ATA 驱动器均应部署在 ARM 上,这样有助于减轻 DSP 的处理压力。而 JPEG 编码器应在部署在 DSP 的内核上,因为DSP VLIW 架构特别适用于这种计算强度大的工作。
一旦摄像头通过处理器上的视频输入端口采集到视频帧,原始影像就通过 JPEG 编码器压缩,随后将该压缩影像保存到设备硬盘上。
图 4:有关视频监视系统中基于 DaVinci 技术的 TI DM6446 数字视频评估板的 MJPEG 数据流演示。
我们通常用 PC 监控实时视频场景,首先检索出视频服务器中的流媒体,然后进行解码,最后在显示器上显示视频影像。编码的 JPEG 影像文件可由设备通过因特网检索,因此我们不仅可在一台 PC 上同时监控多个视频流,而且通过因特网能够从多个点同时查看这些被检索到的视频流。VSIP 局端通过 TCP/IP 网络能与视频服务器相连,而且可位于网络中任何位置。这与传统模拟系统相比,是一个巨大的进步。就算出了问题,也只影响一个数字摄像头,而不会影响局端。我们也可动态配置 JPEG影像质量,以满足不同视频质量要求。
优化JPEG编码器
JPEG 编码器的三大功能模块中,DCT 与量化器的计算任务较重。我们也可以注意到,就这两种模块而言,高度优化的汇编代码和未优化的 C 代码之间存在很大的性能差异,因此有必要对这两个模块进行优化。
优化 2D 8x8 DCT功能模块有助于减少加、减、乘等运算次数,避免原始方程式的冗余计算。目前已推出了众多快速 DCT 算法,其中陈氏算法 (Chen’s algorithm) 广为业界采用。就 2D 8x8 DCT 而言,陈氏算法需要进行 448 次加减运算以及 224 次乘法运算。
加减法和乘法功能块可进一步拆分为多个功能单元(均部署在 DSP 内核上),以执行并行指令并提高性能。在开销忽略不计的条件下,高度优化的 DSP 汇编代码能在 100 个循环之内顺利完成 2D DCT 计算任务。其它快速 DCT 算法要求的计算量更少,不过往往会要求更多缓冲区来保存中间计算结果。就采用管线 VLIW 架构的新型 DSP 而言,存储器数据存取工作量比乘法运算工作量大,因此开发人员在优化算法时应考虑计算与存储器存取之间的平衡问题。
每个像素的量化过程均需要进行乘法及加法运算。这种计算结果通常只需要 16 位的精确度即可,而 DSP 寄存器则需要 32 位。优化量化器模块的最初想法是在单个寄存器中存储 2 个像素,然后对这两个像素执行加法及乘法运算;第二种方法就是并行使用多个 DSP 功能单元。由于 TMS320DM6446 中的 DSP 内核有 2 个乘法器和 2 个加法器,因此我们可同时量化高达 4 个像素。最后但不是不重要的一种做法就是充分利用管线 DSP 架构。DSP 内核在量化当前 4 个像素时,可从存储器读取下一组“ 4 个像素”,这样每个循环都能向乘法器和加法器提供数据。前两种方法由开发人员亲自编写优化的 C 代码或汇编代码即可实现。管线代码可采用 DSP 编译器。
除了优化每个功能模块之外,我们还可采用乒乓 (PING-PONG) 缓冲技术来优化系统级 JPEG 编码器。DSP 内核存取内部 RAM(IRAM) 中的数据的速度比存取外部 DDR2 存储器中数据的速度快得多。但 IRAM 容量有限,不能满足整个输入帧的要求,因此同一时间在 IRAM 中只能处理一部分模块。处理乒乓集时,DMA 将乒乓集从 DDR2 传递至 IRAM,这样 DSP内核就能在完成当前工作后立即开始处理下面的数据。
显然,视频监视系统的数字化已经全面展开。了解视频压缩、系统分区和编解码器优化等技术,对开发新一代视频监视系统以满足不断增长的需求来说至关重要。

 举报
举报




