视频应用对密度和高品质处理的需求与日俱增,将广播和通信网络推向了极限。增加更多的设备来处理这些视频流,从经济角度来讲是不可行的。而且,运营商、服务提供商和内容提供商注意到了在云端使用标准服务器的优势,想要摆脱 特殊设备或专用硬件。但目前标准服务器尚未针对云端视频转码进行优化。
因此,最佳解决方案是加速视频云:标准服务器中的 PCI Express 视频加速卡。 加速视频云不但提供大量基于标准服务器的资源,还具备更高性能和更高密度视频处理的额外优势,以满足当今用户的需求。
目前云端处理视频流量的能力
消费者是改变广播网络格局的主要驱动力。用户习惯正在从传统的广播转变为电视视频消费(请参阅以下图表顶部的“线性”部分),再到动态、按需提供、移动的视频观看(请参阅以下图表底部的“多屏幕”部分)。
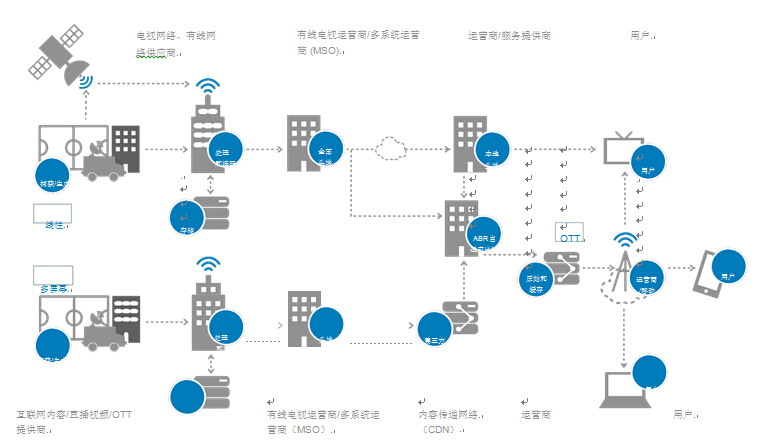
这给网络带来重负,因此,网络正在快速扩展自身能力,以便同时处理传统电缆/线性/广播视频分布和更动态的多屏幕视频。相较于运营商喜好,多屏幕视频更多地受到消费者喜好的推动。视频的带宽消耗不容忽视,按其网络份额大小进行判断时尤其如此。
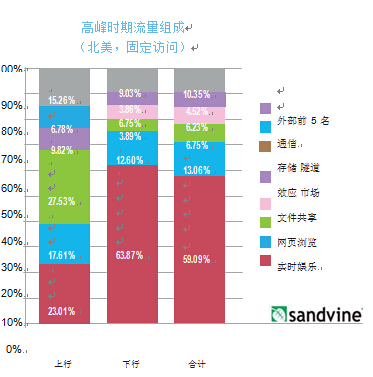
例如,Sandvine 的《全球互联网现象报告》(2014 年 6 月)表明,在高峰时期,实时娱乐占到下行字节的 63% 以上。
随着多服务运营商(MSO)和电信服务提供商使用云技术来为 媒体市场提供足够处理资源、流资源和存储资源的比例不断增 大,运营商的业务格局也转向视频。但是,目前的云端视频性能水平离最理想水平还相差甚远。
本文将使用 Intel?(英特尔)、戴尔和雅特生科技的最新技术, 通过虚拟转码解决方案来探索在云端承载视频的更好方法,最终实现更高密度、更高部署灵活性。
解决方案 —— 加速视频云
典型的云实施基于多个完全相同的服务器,这些服务器可根据需要 用于不同的任务,满足应用指定的不同规模和空间占用要求。处理器是大量云计算资源中的 NFV(网络功能虚拟化基础架构)节点。
但是对于视频,用于视频流的服务器比用于网页浏览的服务器支持的用户容量少得多。因此,需要向云服务器增加视频处理和转码资 源。
运营商在云端使用标准服务器的比例不断增大,而且无需特殊设备, 加上视频应用对密度和高品质处理的需求与日俱增,因此最佳的解 决方案是加速视频云。加速视频云不但提供大量基于标准服务器的资源,还具备更高性能和更高密度视频处理的额外优势,以满足当 今用户的需求。
使用标准服务器的期望
在过去 10 年,就资本和运营支出两方面而言,云数据中心解决方案的开发已创造出极具成本效益的业务模式。通过使用现成的商用 (COTS) 硬件并开发可使用智能协调器进行控制的高度可靠和可扩 展软件,传统的数据中心已成为企业和过顶 (OTT) 互联网解决方案 提供商的标准。由于长期要求可靠性、可管理性和可用性(优先级别更高),此模式的优势在电信网络中尚未实现。
在 ETSI 网络功能虚拟化工作组(后文详述)的帮助下,运营商和 服务提供商开始尝试在电信网络中采用成熟的云技术,并尝试解决此网络的特殊要求。
现在,解决方案提供商也正在开发 NFV 解决方案,为运营商提供云网络解决方案。
除了降低通向新市场的成本外,此方案还有很多优势。利用 COTS 硬件和软件规模的优势,网络设计、部署、管理和支持需要的资源 将减少。使用行之有效的解决方案进行维护将会更轻松。另外,可在整个网络中更快地测试、试验和推出虚拟平台中运行的新服务, 为运营商提供了一种回报更快的路径,并能更迅速取悦使用新技术 的消费者。虚拟网络还具有更大的可扩展性。可推动改进整个数据中心的功耗、管理和支持,例如,戴尔平台和服务已经能够为运营 商提供理想的性能、密度、运营成本和支持之间的平衡。
这些网络数据中心的核心运行组件是标准服务器。就资本和运营支 出两方面而言,标准服务器的设计目的是提供引人注目的财务状 况。它们经常被优化以实现高可靠性、高性能和高密度,并可在数据中心或电信中心办公室环境下运行。例如,由两个 Intel? Xeon? E5 处理器驱动的戴尔 PowerEdge? R720 2U COTS 服务器,提 供有交流或直流电源输入、标准配置或符合 NEBS 级别 3 和 ETSI 标准的可选配置选配件,以满足电信基础架构部署位置的各种要求。为了达成本白皮书的目的和解决方案,戴尔与雅特生密切合 作,推荐使用符合 NEBS L-3 标准的 PowerEdge? R720 运营商级版本,它能满足运营商网络的严苛要求;同时,戴尔还提供可在 现代高架地板数据中心使用的标准版本。通过结合本白皮书中提出 的加速视频云方法论与戴尔 PowerEdge? R720,即可实现使用标 准服务器和大幅增加网络视频处理性能这两个优势。
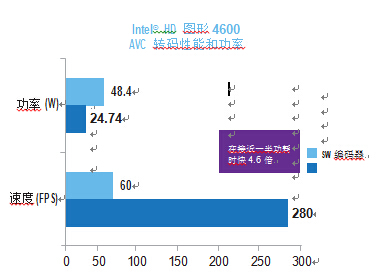
2013 年,使用英特尔第四代酷睿生产线,Intel? 推出 Iris Pro 处理 器图形,它增加了 MPEG2 编码器功能,通过增加更多的动态预测 引擎提高视频质量,内置 128MB DRAM,为 GPU 提供了高带宽的内存容量(70GB/s,而双通道 DDR3 存储接口为 25GB/s)。
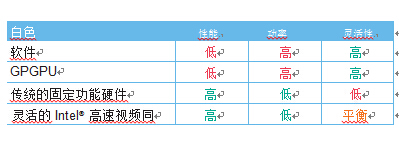
在转码方面,高速视频同步技术比其它架构拥有更多优势。传统的硬件固定功能提供低功率和高性能的解决方案,但如果需要更新编 码,则无法快速变化。而软件编解码器以功率和性能为代价,提供 充分的灵活性。
通过利用硬件实现不变编解码器的功能,利用 GPU 中的计算单元 上运行的软件实现可变编解码器的功能,高速视频同步技术能够实 现平衡的解决方案,功率低且性能高,同时保持日后改进编解码器所需的灵活性。
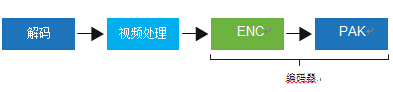
高速视频同步解决方案由两个主要元素构成。“ENC” 由提供有效 动作搜索的硬件加速(也称作媒体采样器)和在可编程的执行单元 阵列上运行的软件构成。“PAK” 重新使用来自多格式编解码器引擎 的逻辑,提供完整的硬件单元进行像素重建、量化、熵编码等。
混合 2 级视频编码器

这种硬件和软件组合允许高速视频同步技术大大降低英特尔架构上转码的功率要求,同时提高了性能。
这些数据块通过多格式编解码器引擎和视频后期处理(例如,Deinterlacing、DeNoise 和一些其它过滤器)与硬件解码加速相结 合,提供四级转码管道,且所有级能够同时运行,以实现高密度的直播/线性同时转码,速度比实时或离线转码要快数倍。
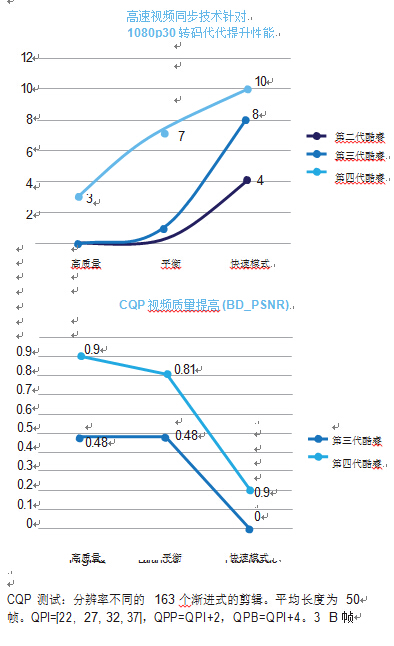
借助灵活的编码器管道,Intel? 定位用于提高每一代的性能和视频 质量。在 Intel? 第二代酷睿和 Intel? 第四代酷睿之间,“平衡”(视频质量和性能)模式的性能大大提升,同时此模式的视频质量也得到提高。总的来说,Intel? 第四代酷睿中的 QSV 提高了各级 视频质量,超过了前代产品。
资源层,提供一套标准资源元素(包含计算、存储和网络)。 对于需要消耗资源的应用程序以及管理/协调应用程序而言,这些资源是可见的,是硬件层物理实现的抽象概念
共享服务——硬件和上述资源接口之间的粘连层。这是虚拟 化存在的地方——虚拟机管理程序,可访问虚拟机 (VM) 和客 体操作系统,是所管理的所有计算单元之间的一个共享服务
OpenStack 面板 —— 管理层,允许云服务提供商将资源分配 到用户应用程序(并提供收费等辅助功能)
共享服务和(最重要的)资源元素驻留在“标准硬件”上
OpenStack 的目标是提供一套管理集资源,完全独立于基础硬件。此方案有众多优势——服务可随着网络条件和服务需求变化而转换到其它服务器。
对于多数应用程序,这一抽象效果很好。但是,有些应用程序对计算或存储或网络资源有特殊要求,必须连接到更具体的硬件实例。 其中一个示例就是视频转码。
有关“标准”硬件的注释——“标准”并不意味着全能。各物理资源必 须提供认可级别的性能(可以是 CPU、网络带宽、存储能力或“特 殊”硬件要求)。 这些资源出现在管理面板中,可根据需要分配到用户应用程序。应 用程序必须提供运行所需的资源“配置文件”;面板允许服务提供商 将匹配的资源分配到应用程序。
对于视频转码,通过面板可提供大量视频经过优化的资源。为每个 用户/应用程序建立策略以管理对转码功能的使用,这由面板强制 执行。策略派生自服务级别,它极其灵活,能力具有弹性,例如:
临时允许超额容量 以溢价成本提供超额容量
对于想要实施网络功能虚拟化(NFV,此术语表示将网络应用与它们的基础硬件分离)的运营商/服务提供商,OpenStack 受到他们 的极大关注。换句话说,OpenStack 就是“适用于电信应用的云基 础架构”。
SDN/NFV 标准化
ETSI 建立了行业标准化工作组 (ISG) 来研究是否需要 NFV 标准。 虽然 OpenStack 来自企业界,但集中协调虚拟化的资源这种概念 将是形成 NFV 标准的关键组成部分。OpenStack 或其运营商级 版本可能会作为关键技术出现。
从基础架构上至管理和协调,ETSI NFV ISG 已经在 NFV 的结构 上建立了信息化工作。就其本身而论,这是对推荐做法的描述, 而不是如何实施 NFV 的任何标准,或来自多个供应商的、很多用 户使用的和许多服务提供商运行的设备和软件实际上将如何交互 操作的任何标准。但几乎可以肯定的是,NFV ISG 将继续工作两 年,目标是建立 NFV 的规范标准。
ISG 本身是由全球著名的服务提供商、设备制造商和独立软件供 应商组成。可以公平地说,NFV 拥有广泛且坚定的行业支持,将 会成功推荐出标准方案来实施包括视频在内的众多应用。
多视频处理资源的 SDN/NFV 控制
协调很多用户可用的多个异构视频资源不是一项简单的任务。事 实证明,OpenStack 在企业云环境下可扩展性极大,期望形成的任何 NFV 标准都将拥有相同的可扩展性。
但是,作为应用程序的视频与企业云应用程序差异很大,应该认 真考虑。视频传输是资源消耗的“完美风暴”:
需要使用大容量存储才能维持视频内容的数据库视频流从源格式到最终传输格式的转码(比特率、视频格式、
屏幕尺寸等)需要消耗大量计算资源到最终用户的流量传递几乎是实时的;可用带宽必须匹配转码器生成的流量
因此,协调器必须知道可用于视频转码的资源,以及通过网络获得视频数据包所需的带宽。这是一个网络边缘问题(最终传递到 消费者设备)。这对于中间处理也是一个问题,中间处理是将原 始的、集中化的内容(通常来自制作者或播送者)转码,并推送到位于网络边缘(尽可能靠近最终消费者)的多个实例。
另外一个考虑是假设 OpenStack 控制(“协调”)虚拟资源——本 质上,虚拟机 (VM) ——通过其管理程序层加以实现,该层从底层硬件抽象出应用程序执行环境。服务器可支持多个 VM,资源被 认为在规模上有弹性。
视频再次遇到了问题。如果转码从主机 CPU 转到一个加速器上,那 么 OpenStack 协调器需要知道加速器可用(且支持视频功能)。更糟 糕的是,加速器架构通常不使用 VM 技术,而是在 CPU 主操作系统上直接运行(常用术语“裸机”描述非 VM 模式)。
OpenStack 如何协调直接映射到硬件的“执行”资源?幸运地是,这个 问题有解决方案:OpenStack 有一个插件(称为 “Ironic”)用于协调 裸机资源。其 Northbound API 与管理 VM 的接口完全相同,但 Southbound 接口知道它管理单一的硬件资源。
将来,ETSI NFV 工作组将标准化这样做所需的接口和基础架构。同 时,OpenStack 和 SDN 的互补技术将弥补此间隙。OpenStack 允许 协调资源时,SDN 利用 OpenFlow 协议配置网络交换机,以提供与 要传输的视频流量一致的互连能力。OpenDaylight 等 SDN 控制器可协助协调流量。

另一种方法是,简单地提供将视频处理为“永远在线”所需的“最坏情 况”计算和网络资源。因为所提供的资源大部分时间不使用,这将导 致网络的能力过剩(以及由此产生的成本)。
在 Hulu 模式中,视频每天以批量“离线”的方式被处理和传输。“大众 消费事件”的情况甚至更加极端,例如大型体育赛事,其现场直播必 须缓存和实时处理。
通过组合使用 NFV (OpenStack) 和 SDN,资源仅在使用时被消费和 付费。资源可用性的弹性意味着,可以满足意想不到级别的需求,而且无需事先过度配置。
这里所使用的 OpenStack、OpenFlow、OpenDaylight 等现有技术, 均为开源项目,开发人员可免费使用以实施这些服务。
转码越来越多地被使用,其中一种情况是电视回看或追赶,内容提供商接收来自多个制作者的内容,并将其处理为可供订阅者在次日观看。此类提供商每天可接收数百小时的内容,这些内容需要转码为多种不同的格式,以便传递到许多设备。结果是需要转码数千小时的视频。
例如,提供商正在从多个制作者那里接收 200 小时的内容。根据所支持的设备不同,提供商可能会将此内容制作成多达 100 种不同的转 码输出,以解决其允许的任何消费者设备对编解码器、分辨率、比特率等的不同需求。
为了使这个例子更简单,我们假设,现在提供商将执行 10 种不同的 1080p30 H.264 输出。运行在标准的 1RU 双 Intel? Xeon? E5-2650V2 处理器服务器上,服务器中每个 CPU 能够处理大约 60 帧/秒的 X.264 转码(在 3.2GHz Intel? Core? i7-4770R 上以默认 CRF 快速模式 下的33fps 数据推断得出);没有虚拟化运行时,则每个服务器达到 120 帧/秒。但在云环境下,转码器将在虚拟机中运行,因此,我们 需要将此数字降低约10%,即每服务器总计约 108 帧/秒。
如果以 30 帧/秒转码 200 小时的内容,系统需要转码 2.16 亿帧才能实现 10 种输出。速率为 108 帧/秒时,双 Intel? Xeon? E5-2650v2 服务器将需要 556 小时来执行此任务。而这对电视回看功能不是真正地有效。使用戴尔 R720T 等双 E5-2650V2 2RU 服务器时,上述工 作量需要 24 个服务器(》1 机架)以 100% 最快速全天候不间断运行,才能确保内容能够在 24 小时内传递给消费者。以最快速全天候 不间断运行肯定会导致数据中心故障,因此需要更多的服务器来分摊负荷,以确保可靠性。含有 2x Intel? Xeon? E5-2650V2 处理器的戴 尔 R720T 在有/无 4x Artesyn SharpStreamer? 卡时的比较:
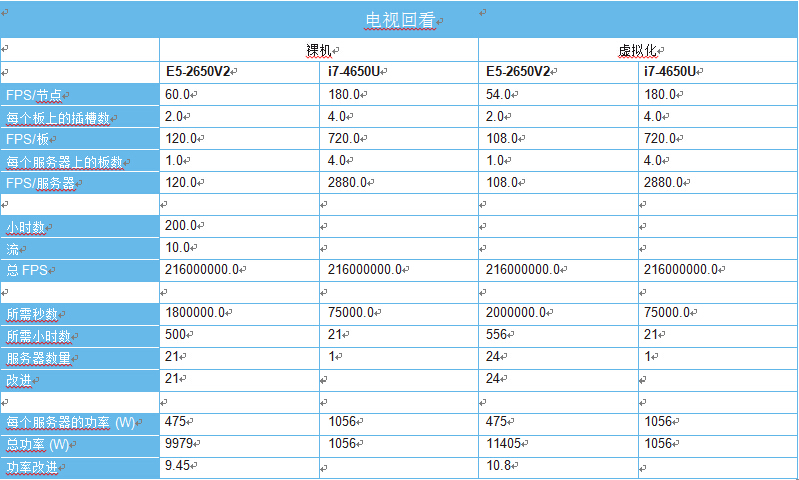
另一种方法是在此类系统中使用 Artesyn SharpStreamer? 卡。 在带有 4 个 Intel? Core? i7-4650U CPU 且每个 CPU 节点分 别能够传递 120-240 帧/秒的 1080p 转码的条件下,提供商就可以进一步提高每个服务器的效率。在这种配置下,配合 CPU 内核上的软件,一台含有双 Intel? Xeon? E5-2650V2 和四个 Sharp Streamer 卡的服务器可有效地达到约 4000 帧/秒。为了与 Intel? Xeon? E5-2650V2 软件解决方案做比较,我们将专注于在 平衡质量模式(Intel MediaSDK 目标使用 = 4)下每节点 180 帧/ 秒的中间值,因此四张 PCIe 卡以 2880 帧/秒进行处理。这个解 决方案能够通过单个服务器在 21 小时内将 200 小时的内容处理 为 10 种单独的输出,服务器数量仅需另一方案的 1/24,功率降 低至 1/11,成本更是减少至 1/5 以下。
而 10x 1080p30 转码可能不是此种部署的真正代表,可以想象得 出,提供商将需要提供更多计算,例如,一个 1080p30 大致相 当于单个 720p60。还应注意,200 小时仅代表许多内容提供商接收的总小时数的一部分。
实时/线性 ABR 广播转码器需求
对于消费者而言,一天内的直播电视观看习惯随时改变。如今,IPTV 提供商必须做到不仅能传递至他们机顶盒中的已知实体,而且需要适应消费者观看他们内容所使用的大量设备,例如平板电脑、手机、第三方电视(如 Roku?、Apple TV 和亚马逊的 Fire TV)。广播电视提供商提供在线电视门户网站时也面临类似 的挑战。结果就是 IPTV 提供商现在需要能够以最小延迟实时生成大量不同的转码格式。
为了适应网络拥塞,大多数提供商已转向自适应比特率技术,例 如苹果的 HLS、Silverlight、PlayReady 等,其允许消费者设备决 定是否需要切换到不同的配置文件,以确保内容能够连续播放。在多数情况下,消费者愿意容忍视频质量的瞬间降低,但重新缓 冲通常会导致消费者改变频道或改变提供商。自适应流试图通过 将视频切割为某一时间段(例如,2-4 秒)的多个区块,并使客 户端能够在伪播放列表(称作清单)中使用这些区块,来帮助消 费者设备适应网速和带宽的变化。
此清单为客户端提供相关数据,展示什么配置文件适用于特定时间索引以及要请求的必要文件是什么。消费者设备请求其所需的 配置文件,并监控下载时间,如果时间不能满足维持播放率所需 的时间,设备将请求较低级的配置文件并监控,最终可能需要重新缓冲,但是,已经配置好的设备将能够在需要重新缓冲前及时 为播放器获得下载的配置文件,除非网络出现严重问题。
自适应流的缺点是需要创建不同的配置文件。在多数情况下,提供商不仅需要为其目标设备处理多种自适应流技术,还需要适应各种 设备所支持的不同分辨率、编解码器配置文件、比特率等。这将导 致单个信道需要很多转码。最糟糕的情况是,允许访问内容的每个设备类型在线且访问每个信道的内容。信道越多,发生这种情况的 可能性就越小,但提供商需要在规划网络时知道峰值数。
通常情况下,全天将有一套通用转码集,大部分不是所有设备都需要,它们可以根据需要打包到各种所需的自适应流配置文件中。另 一套转码集用于传递特定设备所需的特殊呈现形式,但此转码集更 加动态,具体取决于观看习惯。例如,许多人在醒来时使用带有机顶盒的电视机或其它设备,然后转到更加便携的设备,例如便携式 计算机、手机等。
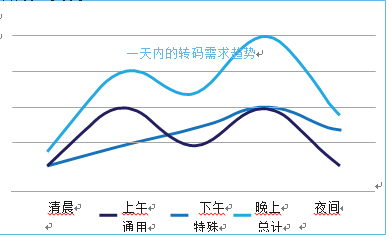
关于众多信道间的趋势:将在一组信道上有波峰,而其它信道上有波谷。使用基于 Intel? XeonTM 的服务器上的虚拟化时,系统能够根 据需要带来更多的在线转码器,并配置它们以制作各种目标设备所需的呈现形式,方法是实施多比特率转码器,该转码器为传入视频 解码、调整到所需分辨率并在发送到分割器以将流分割为分断文件 之前编码为特定格式,然后发送到包装程序,按照消费者设备所要求的自适应比特率标准打包到所需包装。
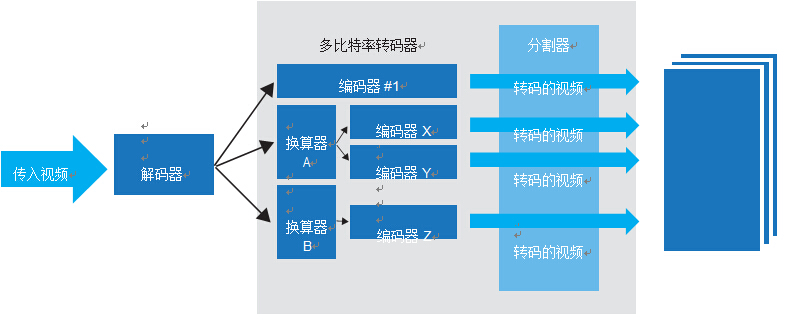
对于高效的多比特率转码器,视频解码应出现一次,并用作所有编码输出的单个参考;而编码器稍加优化即可降低各种输出分辨 率的缩放费用以及这些分辨率上的动作搜索。
来自编码器的每个输出都是图片组 (GOP) 和排列的顺序(编码与 显示),这一点很重要。因此,在提交到包装程序之前,来自分割器的结果片段都是正确排列。
此类运行软件转码器的多比特率转码器服务器所面临的挑战,是 确保所需的所有不同的呈现形式都在单个服务器上生成。如果所 需呈现形式超出服务器能力,系统将需要为传入视频复制解码器,以便原始基带视频无需通过系统之间(否则会进一步增加延 迟),这要求每个流上有相当大的网络带宽(对于 1080p30 8bit YUV 内容,约为 500Mbps)。另外,这两个系统将需要保持同 步,以确保输出呈现形式为 GOP 和排列的顺序,这是成功分割 的关键。
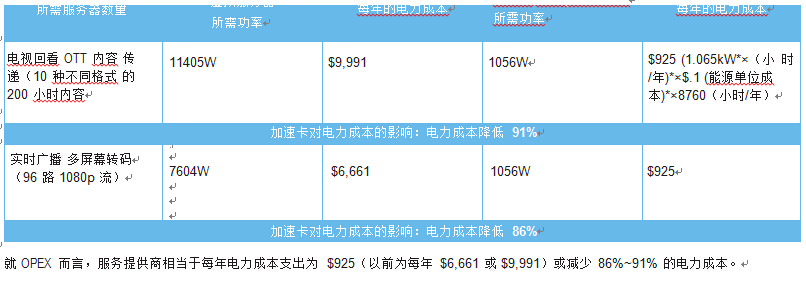
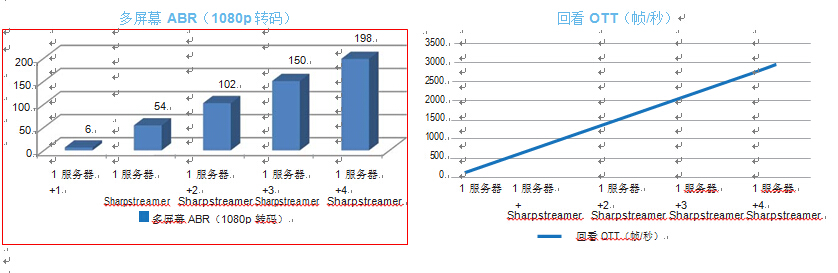
使用已启用 Artesyn SharpStreamer 卡的系统时,所提供的密度允许 实现更多呈现形式,而且允许单个服务器上能适应更多信道。戴尔 RT720p Dual Intel? Xeon? E5-2650V2 处理器系统有可能输出六个单 独的 1080p30 流,配备四个 SharpStreamer 卡的相同系统能适应多 达 96 个单独的 1080p30 流,每个服务器的转码能力提高 16 倍。
在 SharpStreamer 加速的平台上,功率要求也缩小七倍:以前需要16 个服务器共 7604W,现在只需 1056W 即可处理 96 个流。
启用 SharpStreamer 卡的系统允许提供商快速使网络适应消费者设备的按需需求。
总结:此方案的优势
使用上述两种方案时,通过虚拟网络中的视频加速可实现众多优势。
优势一:降低资本设备支出
加速方案的优势主要来自服务器在数据中心所占用空间的减少和管理这些资源的简化。网络功能虚拟化使提供商能够动态地改变所需资源 类型和级别,并且这适用于上述使用情况下作为 VNF 的视频转码。

优势二:省电并降低间接费用
优势三:可扩展性
当网络要求增加或减少视频转码时,也能以较低成本扩大或缩小资源,这是因为可通过附加卡达到视频转码数量,从而减少服务器数量。如上所述,网络中服务器的数量减少,有利于大幅降低运营成本。因此,如同服务提供商通过增加服务来提供优质的 OTT 视频服务,附 加卡能逐渐提高所需的密度级别,但资本设备支出没有目前的传统方法那么高昂。
优势四:使用简单,通过云端通用 X86 处理即可实现
基于 x86 的方法用来解决云端视频处理问题,对设备供应商而言具有重要优势,原因在于英特尔技术提供熟悉且简单易用的 API 来加速 开发和上市时间。Intel? Media SDK 可实现从纯软件模式到媒体加速模式的转变,同时具备运行 Windows、Linux、QuickSync video 和 API 库的能力,甚至能以更高密度的容量为视频应用传递最大的每机架单位流数。
视频应用对密度和高品质处理的需求与日俱增,将广播和通信网络推向了极限。增加更多的设备来处理这些视频流,从经济角度来讲是不可行的。而且,运营商、服务提供商和内容提供商注意到了在云端使用标准服务器的优势,想要摆脱 特殊设备或专用硬件。但目前标准服务器尚未针对云端视频转码进行优化。
因此,最佳解决方案是加速视频云:标准服务器中的 PCI Express 视频加速卡。 加速视频云不但提供大量基于标准服务器的资源,还具备更高性能和更高密度视频处理的额外优势,以满足当今用户的需求。
目前云端处理视频流量的能力
消费者是改变广播网络格局的主要驱动力。用户习惯正在从传统的广播转变为电视视频消费(请参阅以下图表顶部的“线性”部分),再到动态、按需提供、移动的视频观看(请参阅以下图表底部的“多屏幕”部分)。
这给网络带来重负,因此,网络正在快速扩展自身能力,以便同时处理传统电缆/线性/广播视频分布和更动态的多屏幕视频。相较于运营商喜好,多屏幕视频更多地受到消费者喜好的推动。视频的带宽消耗不容忽视,按其网络份额大小进行判断时尤其如此。
例如,Sandvine 的《全球互联网现象报告》(2014 年 6 月)表明,在高峰时期,实时娱乐占到下行字节的 63% 以上。
随着多服务运营商(MSO)和电信服务提供商使用云技术来为 媒体市场提供足够处理资源、流资源和存储资源的比例不断增 大,运营商的业务格局也转向视频。但是,目前的云端视频性能水平离最理想水平还相差甚远。
本文将使用 Intel?(英特尔)、戴尔和雅特生科技的最新技术, 通过虚拟转码解决方案来探索在云端承载视频的更好方法,最终实现更高密度、更高部署灵活性。
解决方案 —— 加速视频云
典型的云实施基于多个完全相同的服务器,这些服务器可根据需要 用于不同的任务,满足应用指定的不同规模和空间占用要求。处理器是大量云计算资源中的 NFV(网络功能虚拟化基础架构)节点。
但是对于视频,用于视频流的服务器比用于网页浏览的服务器支持的用户容量少得多。因此,需要向云服务器增加视频处理和转码资 源。
运营商在云端使用标准服务器的比例不断增大,而且无需特殊设备, 加上视频应用对密度和高品质处理的需求与日俱增,因此最佳的解 决方案是加速视频云。加速视频云不但提供大量基于标准服务器的资源,还具备更高性能和更高密度视频处理的额外优势,以满足当 今用户的需求。
使用标准服务器的期望
在过去 10 年,就资本和运营支出两方面而言,云数据中心解决方案的开发已创造出极具成本效益的业务模式。通过使用现成的商用 (COTS) 硬件并开发可使用智能协调器进行控制的高度可靠和可扩 展软件,传统的数据中心已成为企业和过顶 (OTT) 互联网解决方案 提供商的标准。由于长期要求可靠性、可管理性和可用性(优先级别更高),此模式的优势在电信网络中尚未实现。
在 ETSI 网络功能虚拟化工作组(后文详述)的帮助下,运营商和 服务提供商开始尝试在电信网络中采用成熟的云技术,并尝试解决此网络的特殊要求。
现在,解决方案提供商也正在开发 NFV 解决方案,为运营商提供云网络解决方案。
除了降低通向新市场的成本外,此方案还有很多优势。利用 COTS 硬件和软件规模的优势,网络设计、部署、管理和支持需要的资源 将减少。使用行之有效的解决方案进行维护将会更轻松。另外,可在整个网络中更快地测试、试验和推出虚拟平台中运行的新服务, 为运营商提供了一种回报更快的路径,并能更迅速取悦使用新技术 的消费者。虚拟网络还具有更大的可扩展性。可推动改进整个数据中心的功耗、管理和支持,例如,戴尔平台和服务已经能够为运营 商提供理想的性能、密度、运营成本和支持之间的平衡。
这些网络数据中心的核心运行组件是标准服务器。就资本和运营支 出两方面而言,标准服务器的设计目的是提供引人注目的财务状 况。它们经常被优化以实现高可靠性、高性能和高密度,并可在数据中心或电信中心办公室环境下运行。例如,由两个 Intel? Xeon? E5 处理器驱动的戴尔 PowerEdge? R720 2U COTS 服务器,提 供有交流或直流电源输入、标准配置或符合 NEBS 级别 3 和 ETSI 标准的可选配置选配件,以满足电信基础架构部署位置的各种要求。为了达成本白皮书的目的和解决方案,戴尔与雅特生密切合 作,推荐使用符合 NEBS L-3 标准的 PowerEdge? R720 运营商级版本,它能满足运营商网络的严苛要求;同时,戴尔还提供可在 现代高架地板数据中心使用的标准版本。通过结合本白皮书中提出 的加速视频云方法论与戴尔 PowerEdge? R720,即可实现使用标 准服务器和大幅增加网络视频处理性能这两个优势。
2013 年,使用英特尔第四代酷睿生产线,Intel? 推出 Iris Pro 处理 器图形,它增加了 MPEG2 编码器功能,通过增加更多的动态预测 引擎提高视频质量,内置 128MB DRAM,为 GPU 提供了高带宽的内存容量(70GB/s,而双通道 DDR3 存储接口为 25GB/s)。
在转码方面,高速视频同步技术比其它架构拥有更多优势。传统的硬件固定功能提供低功率和高性能的解决方案,但如果需要更新编 码,则无法快速变化。而软件编解码器以功率和性能为代价,提供 充分的灵活性。
通过利用硬件实现不变编解码器的功能,利用 GPU 中的计算单元 上运行的软件实现可变编解码器的功能,高速视频同步技术能够实 现平衡的解决方案,功率低且性能高,同时保持日后改进编解码器所需的灵活性。
高速视频同步解决方案由两个主要元素构成。“ENC” 由提供有效 动作搜索的硬件加速(也称作媒体采样器)和在可编程的执行单元 阵列上运行的软件构成。“PAK” 重新使用来自多格式编解码器引擎 的逻辑,提供完整的硬件单元进行像素重建、量化、熵编码等。
混合 2 级视频编码器
这种硬件和软件组合允许高速视频同步技术大大降低英特尔架构上转码的功率要求,同时提高了性能。
这些数据块通过多格式编解码器引擎和视频后期处理(例如,Deinterlacing、DeNoise 和一些其它过滤器)与硬件解码加速相结 合,提供四级转码管道,且所有级能够同时运行,以实现高密度的直播/线性同时转码,速度比实时或离线转码要快数倍。
借助灵活的编码器管道,Intel? 定位用于提高每一代的性能和视频 质量。在 Intel? 第二代酷睿和 Intel? 第四代酷睿之间,“平衡”(视频质量和性能)模式的性能大大提升,同时此模式的视频质量也得到提高。总的来说,Intel? 第四代酷睿中的 QSV 提高了各级 视频质量,超过了前代产品。
资源层,提供一套标准资源元素(包含计算、存储和网络)。 对于需要消耗资源的应用程序以及管理/协调应用程序而言,这些资源是可见的,是硬件层物理实现的抽象概念
共享服务——硬件和上述资源接口之间的粘连层。这是虚拟 化存在的地方——虚拟机管理程序,可访问虚拟机 (VM) 和客 体操作系统,是所管理的所有计算单元之间的一个共享服务
OpenStack 面板 —— 管理层,允许云服务提供商将资源分配 到用户应用程序(并提供收费等辅助功能)
共享服务和(最重要的)资源元素驻留在“标准硬件”上
OpenStack 的目标是提供一套管理集资源,完全独立于基础硬件。此方案有众多优势——服务可随着网络条件和服务需求变化而转换到其它服务器。
对于多数应用程序,这一抽象效果很好。但是,有些应用程序对计算或存储或网络资源有特殊要求,必须连接到更具体的硬件实例。 其中一个示例就是视频转码。
有关“标准”硬件的注释——“标准”并不意味着全能。各物理资源必 须提供认可级别的性能(可以是 CPU、网络带宽、存储能力或“特 殊”硬件要求)。 这些资源出现在管理面板中,可根据需要分配到用户应用程序。应 用程序必须提供运行所需的资源“配置文件”;面板允许服务提供商 将匹配的资源分配到应用程序。
对于视频转码,通过面板可提供大量视频经过优化的资源。为每个 用户/应用程序建立策略以管理对转码功能的使用,这由面板强制 执行。策略派生自服务级别,它极其灵活,能力具有弹性,例如:
临时允许超额容量 以溢价成本提供超额容量
对于想要实施网络功能虚拟化(NFV,此术语表示将网络应用与它们的基础硬件分离)的运营商/服务提供商,OpenStack 受到他们 的极大关注。换句话说,OpenStack 就是“适用于电信应用的云基 础架构”。
SDN/NFV 标准化
ETSI 建立了行业标准化工作组 (ISG) 来研究是否需要 NFV 标准。 虽然 OpenStack 来自企业界,但集中协调虚拟化的资源这种概念 将是形成 NFV 标准的关键组成部分。OpenStack 或其运营商级 版本可能会作为关键技术出现。
从基础架构上至管理和协调,ETSI NFV ISG 已经在 NFV 的结构 上建立了信息化工作。就其本身而论,这是对推荐做法的描述, 而不是如何实施 NFV 的任何标准,或来自多个供应商的、很多用 户使用的和许多服务提供商运行的设备和软件实际上将如何交互 操作的任何标准。但几乎可以肯定的是,NFV ISG 将继续工作两 年,目标是建立 NFV 的规范标准。
ISG 本身是由全球著名的服务提供商、设备制造商和独立软件供 应商组成。可以公平地说,NFV 拥有广泛且坚定的行业支持,将 会成功推荐出标准方案来实施包括视频在内的众多应用。
多视频处理资源的 SDN/NFV 控制
协调很多用户可用的多个异构视频资源不是一项简单的任务。事 实证明,OpenStack 在企业云环境下可扩展性极大,期望形成的任何 NFV 标准都将拥有相同的可扩展性。
但是,作为应用程序的视频与企业云应用程序差异很大,应该认 真考虑。视频传输是资源消耗的“完美风暴”:
需要使用大容量存储才能维持视频内容的数据库视频流从源格式到最终传输格式的转码(比特率、视频格式、
屏幕尺寸等)需要消耗大量计算资源到最终用户的流量传递几乎是实时的;可用带宽必须匹配转码器生成的流量
因此,协调器必须知道可用于视频转码的资源,以及通过网络获得视频数据包所需的带宽。这是一个网络边缘问题(最终传递到 消费者设备)。这对于中间处理也是一个问题,中间处理是将原 始的、集中化的内容(通常来自制作者或播送者)转码,并推送到位于网络边缘(尽可能靠近最终消费者)的多个实例。
另外一个考虑是假设 OpenStack 控制(“协调”)虚拟资源——本 质上,虚拟机 (VM) ——通过其管理程序层加以实现,该层从底层硬件抽象出应用程序执行环境。服务器可支持多个 VM,资源被 认为在规模上有弹性。
视频再次遇到了问题。如果转码从主机 CPU 转到一个加速器上,那 么 OpenStack 协调器需要知道加速器可用(且支持视频功能)。更糟 糕的是,加速器架构通常不使用 VM 技术,而是在 CPU 主操作系统上直接运行(常用术语“裸机”描述非 VM 模式)。
OpenStack 如何协调直接映射到硬件的“执行”资源?幸运地是,这个 问题有解决方案:OpenStack 有一个插件(称为 “Ironic”)用于协调 裸机资源。其 Northbound API 与管理 VM 的接口完全相同,但 Southbound 接口知道它管理单一的硬件资源。
将来,ETSI NFV 工作组将标准化这样做所需的接口和基础架构。同 时,OpenStack 和 SDN 的互补技术将弥补此间隙。OpenStack 允许 协调资源时,SDN 利用 OpenFlow 协议配置网络交换机,以提供与 要传输的视频流量一致的互连能力。OpenDaylight 等 SDN 控制器可协助协调流量。
另一种方法是,简单地提供将视频处理为“永远在线”所需的“最坏情 况”计算和网络资源。因为所提供的资源大部分时间不使用,这将导 致网络的能力过剩(以及由此产生的成本)。
在 Hulu 模式中,视频每天以批量“离线”的方式被处理和传输。“大众 消费事件”的情况甚至更加极端,例如大型体育赛事,其现场直播必 须缓存和实时处理。
通过组合使用 NFV (OpenStack) 和 SDN,资源仅在使用时被消费和 付费。资源可用性的弹性意味着,可以满足意想不到级别的需求,而且无需事先过度配置。
这里所使用的 OpenStack、OpenFlow、OpenDaylight 等现有技术, 均为开源项目,开发人员可免费使用以实施这些服务。
转码越来越多地被使用,其中一种情况是电视回看或追赶,内容提供商接收来自多个制作者的内容,并将其处理为可供订阅者在次日观看。此类提供商每天可接收数百小时的内容,这些内容需要转码为多种不同的格式,以便传递到许多设备。结果是需要转码数千小时的视频。
例如,提供商正在从多个制作者那里接收 200 小时的内容。根据所支持的设备不同,提供商可能会将此内容制作成多达 100 种不同的转 码输出,以解决其允许的任何消费者设备对编解码器、分辨率、比特率等的不同需求。
为了使这个例子更简单,我们假设,现在提供商将执行 10 种不同的 1080p30 H.264 输出。运行在标准的 1RU 双 Intel? Xeon? E5-2650V2 处理器服务器上,服务器中每个 CPU 能够处理大约 60 帧/秒的 X.264 转码(在 3.2GHz Intel? Core? i7-4770R 上以默认 CRF 快速模式 下的33fps 数据推断得出);没有虚拟化运行时,则每个服务器达到 120 帧/秒。但在云环境下,转码器将在虚拟机中运行,因此,我们 需要将此数字降低约10%,即每服务器总计约 108 帧/秒。
如果以 30 帧/秒转码 200 小时的内容,系统需要转码 2.16 亿帧才能实现 10 种输出。速率为 108 帧/秒时,双 Intel? Xeon? E5-2650v2 服务器将需要 556 小时来执行此任务。而这对电视回看功能不是真正地有效。使用戴尔 R720T 等双 E5-2650V2 2RU 服务器时,上述工 作量需要 24 个服务器(》1 机架)以 100% 最快速全天候不间断运行,才能确保内容能够在 24 小时内传递给消费者。以最快速全天候 不间断运行肯定会导致数据中心故障,因此需要更多的服务器来分摊负荷,以确保可靠性。含有 2x Intel? Xeon? E5-2650V2 处理器的戴 尔 R720T 在有/无 4x Artesyn SharpStreamer? 卡时的比较:
另一种方法是在此类系统中使用 Artesyn SharpStreamer? 卡。 在带有 4 个 Intel? Core? i7-4650U CPU 且每个 CPU 节点分 别能够传递 120-240 帧/秒的 1080p 转码的条件下,提供商就可以进一步提高每个服务器的效率。在这种配置下,配合 CPU 内核上的软件,一台含有双 Intel? Xeon? E5-2650V2 和四个 Sharp Streamer 卡的服务器可有效地达到约 4000 帧/秒。为了与 Intel? Xeon? E5-2650V2 软件解决方案做比较,我们将专注于在 平衡质量模式(Intel MediaSDK 目标使用 = 4)下每节点 180 帧/ 秒的中间值,因此四张 PCIe 卡以 2880 帧/秒进行处理。这个解 决方案能够通过单个服务器在 21 小时内将 200 小时的内容处理 为 10 种单独的输出,服务器数量仅需另一方案的 1/24,功率降 低至 1/11,成本更是减少至 1/5 以下。
而 10x 1080p30 转码可能不是此种部署的真正代表,可以想象得 出,提供商将需要提供更多计算,例如,一个 1080p30 大致相 当于单个 720p60。还应注意,200 小时仅代表许多内容提供商接收的总小时数的一部分。
实时/线性 ABR 广播转码器需求
对于消费者而言,一天内的直播电视观看习惯随时改变。如今,IPTV 提供商必须做到不仅能传递至他们机顶盒中的已知实体,而且需要适应消费者观看他们内容所使用的大量设备,例如平板电脑、手机、第三方电视(如 Roku?、Apple TV 和亚马逊的 Fire TV)。广播电视提供商提供在线电视门户网站时也面临类似 的挑战。结果就是 IPTV 提供商现在需要能够以最小延迟实时生成大量不同的转码格式。
为了适应网络拥塞,大多数提供商已转向自适应比特率技术,例 如苹果的 HLS、Silverlight、PlayReady 等,其允许消费者设备决 定是否需要切换到不同的配置文件,以确保内容能够连续播放。在多数情况下,消费者愿意容忍视频质量的瞬间降低,但重新缓 冲通常会导致消费者改变频道或改变提供商。自适应流试图通过 将视频切割为某一时间段(例如,2-4 秒)的多个区块,并使客 户端能够在伪播放列表(称作清单)中使用这些区块,来帮助消 费者设备适应网速和带宽的变化。
此清单为客户端提供相关数据,展示什么配置文件适用于特定时间索引以及要请求的必要文件是什么。消费者设备请求其所需的 配置文件,并监控下载时间,如果时间不能满足维持播放率所需 的时间,设备将请求较低级的配置文件并监控,最终可能需要重新缓冲,但是,已经配置好的设备将能够在需要重新缓冲前及时 为播放器获得下载的配置文件,除非网络出现严重问题。
自适应流的缺点是需要创建不同的配置文件。在多数情况下,提供商不仅需要为其目标设备处理多种自适应流技术,还需要适应各种 设备所支持的不同分辨率、编解码器配置文件、比特率等。这将导 致单个信道需要很多转码。最糟糕的情况是,允许访问内容的每个设备类型在线且访问每个信道的内容。信道越多,发生这种情况的 可能性就越小,但提供商需要在规划网络时知道峰值数。
通常情况下,全天将有一套通用转码集,大部分不是所有设备都需要,它们可以根据需要打包到各种所需的自适应流配置文件中。另 一套转码集用于传递特定设备所需的特殊呈现形式,但此转码集更 加动态,具体取决于观看习惯。例如,许多人在醒来时使用带有机顶盒的电视机或其它设备,然后转到更加便携的设备,例如便携式 计算机、手机等。
关于众多信道间的趋势:将在一组信道上有波峰,而其它信道上有波谷。使用基于 Intel? XeonTM 的服务器上的虚拟化时,系统能够根 据需要带来更多的在线转码器,并配置它们以制作各种目标设备所需的呈现形式,方法是实施多比特率转码器,该转码器为传入视频 解码、调整到所需分辨率并在发送到分割器以将流分割为分断文件 之前编码为特定格式,然后发送到包装程序,按照消费者设备所要求的自适应比特率标准打包到所需包装。
对于高效的多比特率转码器,视频解码应出现一次,并用作所有编码输出的单个参考;而编码器稍加优化即可降低各种输出分辨 率的缩放费用以及这些分辨率上的动作搜索。
来自编码器的每个输出都是图片组 (GOP) 和排列的顺序(编码与 显示),这一点很重要。因此,在提交到包装程序之前,来自分割器的结果片段都是正确排列。
此类运行软件转码器的多比特率转码器服务器所面临的挑战,是 确保所需的所有不同的呈现形式都在单个服务器上生成。如果所 需呈现形式超出服务器能力,系统将需要为传入视频复制解码器,以便原始基带视频无需通过系统之间(否则会进一步增加延 迟),这要求每个流上有相当大的网络带宽(对于 1080p30 8bit YUV 内容,约为 500Mbps)。另外,这两个系统将需要保持同 步,以确保输出呈现形式为 GOP 和排列的顺序,这是成功分割 的关键。
使用已启用 Artesyn SharpStreamer 卡的系统时,所提供的密度允许 实现更多呈现形式,而且允许单个服务器上能适应更多信道。戴尔 RT720p Dual Intel? Xeon? E5-2650V2 处理器系统有可能输出六个单 独的 1080p30 流,配备四个 SharpStreamer 卡的相同系统能适应多 达 96 个单独的 1080p30 流,每个服务器的转码能力提高 16 倍。
在 SharpStreamer 加速的平台上,功率要求也缩小七倍:以前需要16 个服务器共 7604W,现在只需 1056W 即可处理 96 个流。
启用 SharpStreamer 卡的系统允许提供商快速使网络适应消费者设备的按需需求。
总结:此方案的优势
使用上述两种方案时,通过虚拟网络中的视频加速可实现众多优势。
优势一:降低资本设备支出
加速方案的优势主要来自服务器在数据中心所占用空间的减少和管理这些资源的简化。网络功能虚拟化使提供商能够动态地改变所需资源 类型和级别,并且这适用于上述使用情况下作为 VNF 的视频转码。
优势二:省电并降低间接费用
优势三:可扩展性
当网络要求增加或减少视频转码时,也能以较低成本扩大或缩小资源,这是因为可通过附加卡达到视频转码数量,从而减少服务器数量。如上所述,网络中服务器的数量减少,有利于大幅降低运营成本。因此,如同服务提供商通过增加服务来提供优质的 OTT 视频服务,附 加卡能逐渐提高所需的密度级别,但资本设备支出没有目前的传统方法那么高昂。
优势四:使用简单,通过云端通用 X86 处理即可实现
基于 x86 的方法用来解决云端视频处理问题,对设备供应商而言具有重要优势,原因在于英特尔技术提供熟悉且简单易用的 API 来加速 开发和上市时间。Intel? Media SDK 可实现从纯软件模式到媒体加速模式的转变,同时具备运行 Windows、Linux、QuickSync video 和 API 库的能力,甚至能以更高密度的容量为视频应用传递最大的每机架单位流数。

 举报
举报




