由于逻辑内建自测试(LogicBIST)向量的随机本质,使得采用LBIST的设计具有非随机模式,从而导致较低的故障覆盖范围。为了解决这一问题,本文在测试点插入非随机故障分析(RRFA)法。藉由故障模拟,完成LBIST设计的故障检测能力运算,有助于估计“测试质量”(quality of test)。本文将就此进行更详细的讨论,同时介绍可为LBIST设计提高故障检测能力的技术。
以LogicBIST定位故障
相较于更具确定性的生产扫描测试,采用LBIST的测试是一种伪随机测试。在LBIST测试中的扫描向量是由伪随机图形产生器(PRPG)所产生的,PRPG主要用于产生伪随机序列。而在生产扫描测试中,扫描向量由自动测试设备(ATE)确定性地馈送至扫描输入。
由于LBIST测试的随机特性,在设计中并没有任何直接控制的扫描输入被传递,所以并不一定都能测试出特定故障。当将LBIST建置于缓存器之间的 高密度组合或大型组合路径设计时,就会出现问题。这些设计可能成为非随机图形测试,在假定的随机和机率相同的输入被馈送到这一类设计时,意味着控制某些节 点的机率任意为0或1,或在一个扫描缓存器观察到某些节点的机率会降低。
以图1中的AND闸为例,计算控制该闸输出为“1”的机率。下图显示每一个节点得到“1”或“0”值的机率。公式为:P(1)/P(0)。
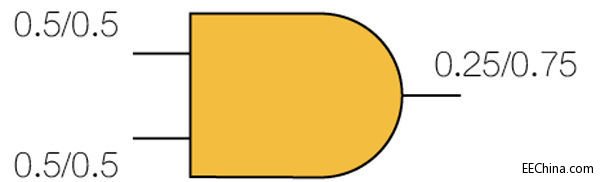
图1:2个输入和闸的可控制性
图2表示当组合深度+1时,在不同节点得到“0”或“1”值的机率。在此组合区块中的输出得到“1”的机率为1/8。然而,这仍然是一个非常简单的组合区块,在实际设计中所看到的区块更复杂。因此,随着组合深度的增加,控制节点于特定值的能力随之减弱。
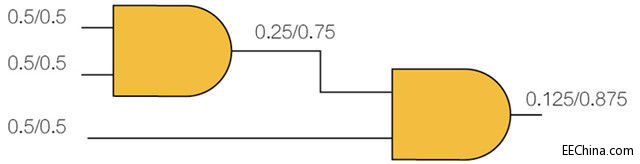
图2:2级深度组合逻辑的可控制性
当采用LBIST测试时,这样的设计表现出非随机图形模式,并可能导致低故障覆盖率。为了解决这些问题,经常使用测试点插入以提升设计的可测性。测试点可分为两类:控制点和观察点。
控制点增加某一特定节点被控制为“0”或“1”值的机率。图3和图4显示了这两种控制点:其中AND类型的控制点增加了将节点控制为“0”值的机率;而OR类型的控制点则提高了将节点控制为“1”值的机率。
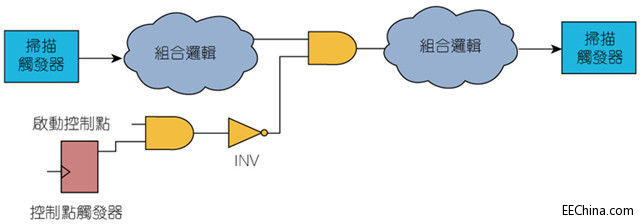
图3:AND类型的控制点提高「0」值的可控性
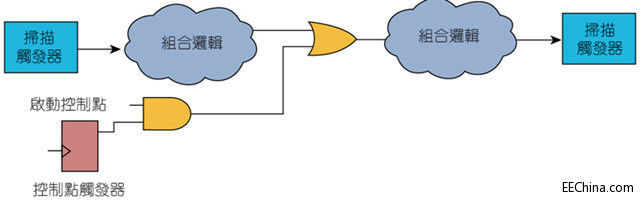
图4:OR类型的控制点提高「1」值的可控性
观察点让设计中难以观察的节点易于被某些扫描触发器观察到。当要观察设计中的多个节点时,将这些节点进行互斥或(XOR)处理,并馈送到扫描触发器。图5是处理这种观察点的建置。
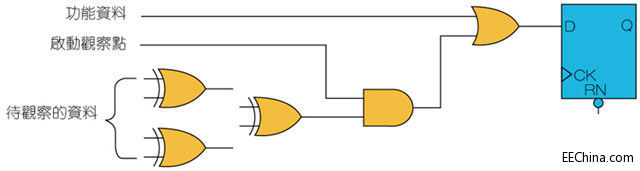
图5:观察点
采用非随机故障分析(RRFA)方法可确认测试点。在为少量随机测试图形进行故障仿真期间,可透过收集统计数据完成测试点确认任务。电路中每个讯号 的可控制性和可观测性测量作业,可以采用机率模型藉由测量增加覆盖增益来计算并给出权重。根据故障仿真RRFA列出的资料分析,确认可能的插入测试点并将 其分为控制0/1两类或作为观察点。
LogicBIST故障模拟
从故障检测的角度来看,故障仿真是一种分析电路的重要工具/方法。故障模拟过程可模拟设计中的节点故障,以确定一组指定的测试向量可检测出哪些故障。如前所述,藉由在随机激励或测试向量情况下分析节点的可控制性和可观测性,RRFA可以使用故障模拟确定合适的插入测试点。
类似地,当设计插入LBIST时,为设计的移位和撷取步骤进行故障模指,可确定LBIST向量所涵盖的故障类型。在此过程中的输出就是故障覆盖率报告和最终LBIST签核(MISR),用以作为设计的预期响应。该故障仿真流程可加以修改,以取得不同的故障覆盖率和签核。
图6显示故障仿真流程,指定了系统的输入及其输出。改变输入的影响以及如何使用输出如上所述。
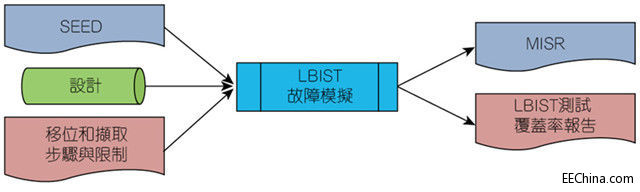
图6:故障仿真流程:输入和输出
从输入开始到故障仿真系统,我们将讨论这些输入如何对系统输出产生影响。
首先,设计应符合LBIST规则,这意味着它应该是扫描密合(scan stitched)的,并对设计中的所有X源进行标记。X源是状态不定且故障仿真系统未知的逻辑。X源包括LBIST化逻辑的非驱动输入、模拟模块输出、 三态总线与时序异常等类型。应该采用合适的X闭锁机制封禁(blocked)这些X源。
系统的第二个输入是PRPG SEED(种子)值。种子值决定将以怎样的序列将移位数据馈送至设计。为了找到能实现最大覆盖率的最佳种子值,可能要经过多次故障模拟,或者由故障仿真引擎本身计算最佳种子。
系统的第三个输入是限制因素和移位撷取序列。MISR和故障检测还取决于LBIST图形数、设计的移位元长度、静态限制以及所施加的撷取脉冲顺序等。
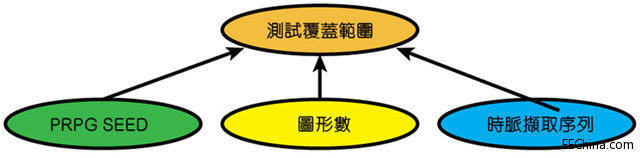
图7:影响故障覆盖率的因素
在LBIST测试期间所执行的图形越多,检测到的故障也较多。通常,图形的数量取决于应用案例。例如,在生产测试时,我们可能不会硬性限制图形数量;但在现场自行检测时,就必须要求组件得在一定时间内作出响应,使其得以在最短时间内同时实现图形数优化与最大覆盖率。
为了执行LBIST模式,故障仿真引擎必须在限制的环境下对设计进行设置。这些限制被馈送到故障仿真引擎作为某一特定的测试设置,这些设置既可是静态的也可因图型而异。这些特定测试设置以及移位-撷取频率序列,有助于故障仿真引擎仿真设计周期并计算最终MISR。
频率的移位和撷取序列频率既可采用硬线连接,也可以是LBIST控制器的可编程特性。这决定了不同频率域的脉控方式。该序列对于故障检测有重要影 响,因此,为其进行优化也至关重要。对于最大的频率域,则应尝试施加最多数量的图形。增加撷取深度的序列深度,也将提高覆盖率,同时也有助于减少图形数。
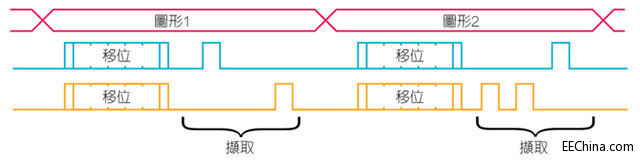
图8:频率移位与撷取序列
结论
对于军事和汽车等关键应用所使用的组件,现场的LBIST测试至关重要。为了在最短的时间内达到最大的故障覆盖率,测试目标应该严格选取。如前所 述,LBIST控制器的故障检测能力决定了测试质量和所需的时间,而且还取决于频率序列、为PRPG智慧选择种子、所添加的控制和观测点数量等参数。为了 实现最大覆盖率、合适的分析与设计优化,以及采用本文中所讨论的技术,必须有效管理你的LBIST测试。
由于逻辑内建自测试(LogicBIST)向量的随机本质,使得采用LBIST的设计具有非随机模式,从而导致较低的故障覆盖范围。为了解决这一问题,本文在测试点插入非随机故障分析(RRFA)法。藉由故障模拟,完成LBIST设计的故障检测能力运算,有助于估计“测试质量”(quality of test)。本文将就此进行更详细的讨论,同时介绍可为LBIST设计提高故障检测能力的技术。
以LogicBIST定位故障
相较于更具确定性的生产扫描测试,采用LBIST的测试是一种伪随机测试。在LBIST测试中的扫描向量是由伪随机图形产生器(PRPG)所产生的,PRPG主要用于产生伪随机序列。而在生产扫描测试中,扫描向量由自动测试设备(ATE)确定性地馈送至扫描输入。
由于LBIST测试的随机特性,在设计中并没有任何直接控制的扫描输入被传递,所以并不一定都能测试出特定故障。当将LBIST建置于缓存器之间的 高密度组合或大型组合路径设计时,就会出现问题。这些设计可能成为非随机图形测试,在假定的随机和机率相同的输入被馈送到这一类设计时,意味着控制某些节 点的机率任意为0或1,或在一个扫描缓存器观察到某些节点的机率会降低。
以图1中的AND闸为例,计算控制该闸输出为“1”的机率。下图显示每一个节点得到“1”或“0”值的机率。公式为:P(1)/P(0)。
图1:2个输入和闸的可控制性
图2表示当组合深度+1时,在不同节点得到“0”或“1”值的机率。在此组合区块中的输出得到“1”的机率为1/8。然而,这仍然是一个非常简单的组合区块,在实际设计中所看到的区块更复杂。因此,随着组合深度的增加,控制节点于特定值的能力随之减弱。
图2:2级深度组合逻辑的可控制性
当采用LBIST测试时,这样的设计表现出非随机图形模式,并可能导致低故障覆盖率。为了解决这些问题,经常使用测试点插入以提升设计的可测性。测试点可分为两类:控制点和观察点。
控制点增加某一特定节点被控制为“0”或“1”值的机率。图3和图4显示了这两种控制点:其中AND类型的控制点增加了将节点控制为“0”值的机率;而OR类型的控制点则提高了将节点控制为“1”值的机率。
图3:AND类型的控制点提高「0」值的可控性
图4:OR类型的控制点提高「1」值的可控性
观察点让设计中难以观察的节点易于被某些扫描触发器观察到。当要观察设计中的多个节点时,将这些节点进行互斥或(XOR)处理,并馈送到扫描触发器。图5是处理这种观察点的建置。
图5:观察点
采用非随机故障分析(RRFA)方法可确认测试点。在为少量随机测试图形进行故障仿真期间,可透过收集统计数据完成测试点确认任务。电路中每个讯号 的可控制性和可观测性测量作业,可以采用机率模型藉由测量增加覆盖增益来计算并给出权重。根据故障仿真RRFA列出的资料分析,确认可能的插入测试点并将 其分为控制0/1两类或作为观察点。
LogicBIST故障模拟
从故障检测的角度来看,故障仿真是一种分析电路的重要工具/方法。故障模拟过程可模拟设计中的节点故障,以确定一组指定的测试向量可检测出哪些故障。如前所述,藉由在随机激励或测试向量情况下分析节点的可控制性和可观测性,RRFA可以使用故障模拟确定合适的插入测试点。
类似地,当设计插入LBIST时,为设计的移位和撷取步骤进行故障模指,可确定LBIST向量所涵盖的故障类型。在此过程中的输出就是故障覆盖率报告和最终LBIST签核(MISR),用以作为设计的预期响应。该故障仿真流程可加以修改,以取得不同的故障覆盖率和签核。
图6显示故障仿真流程,指定了系统的输入及其输出。改变输入的影响以及如何使用输出如上所述。
图6:故障仿真流程:输入和输出
从输入开始到故障仿真系统,我们将讨论这些输入如何对系统输出产生影响。
首先,设计应符合LBIST规则,这意味着它应该是扫描密合(scan stitched)的,并对设计中的所有X源进行标记。X源是状态不定且故障仿真系统未知的逻辑。X源包括LBIST化逻辑的非驱动输入、模拟模块输出、 三态总线与时序异常等类型。应该采用合适的X闭锁机制封禁(blocked)这些X源。
系统的第二个输入是PRPG SEED(种子)值。种子值决定将以怎样的序列将移位数据馈送至设计。为了找到能实现最大覆盖率的最佳种子值,可能要经过多次故障模拟,或者由故障仿真引擎本身计算最佳种子。
系统的第三个输入是限制因素和移位撷取序列。MISR和故障检测还取决于LBIST图形数、设计的移位元长度、静态限制以及所施加的撷取脉冲顺序等。
图7:影响故障覆盖率的因素
在LBIST测试期间所执行的图形越多,检测到的故障也较多。通常,图形的数量取决于应用案例。例如,在生产测试时,我们可能不会硬性限制图形数量;但在现场自行检测时,就必须要求组件得在一定时间内作出响应,使其得以在最短时间内同时实现图形数优化与最大覆盖率。
为了执行LBIST模式,故障仿真引擎必须在限制的环境下对设计进行设置。这些限制被馈送到故障仿真引擎作为某一特定的测试设置,这些设置既可是静态的也可因图型而异。这些特定测试设置以及移位-撷取频率序列,有助于故障仿真引擎仿真设计周期并计算最终MISR。
频率的移位和撷取序列频率既可采用硬线连接,也可以是LBIST控制器的可编程特性。这决定了不同频率域的脉控方式。该序列对于故障检测有重要影 响,因此,为其进行优化也至关重要。对于最大的频率域,则应尝试施加最多数量的图形。增加撷取深度的序列深度,也将提高覆盖率,同时也有助于减少图形数。
图8:频率移位与撷取序列
结论
对于军事和汽车等关键应用所使用的组件,现场的LBIST测试至关重要。为了在最短的时间内达到最大的故障覆盖率,测试目标应该严格选取。如前所 述,LBIST控制器的故障检测能力决定了测试质量和所需的时间,而且还取决于频率序列、为PRPG智慧选择种子、所添加的控制和观测点数量等参数。为了 实现最大覆盖率、合适的分析与设计优化,以及采用本文中所讨论的技术,必须有效管理你的LBIST测试。

 举报
举报




