摘要
TMS320C6678 有8 个C66x核,典型速度是1GHz,每个核有 32KB L1D SRAM,32KB L1P SRAM和512KB LL2 SRAM;所有 DSP核共享4MB SL2 SRAM。一个64-bit 1333MTS DDR3 SDRAM接口可以支持8GB外部扩展存储器。
存储器访问性能对DSP上运行的软件是非常关键的。在C6678 DSP上,所有的主模块,包括多个DSP核和多个DMA都可以访问所有的存储器。
每个DSP核每个时钟周期都可以执行最多128 bits的load或store操作。在1GHz的时钟频率下,DSP核访问L1D SRAM的带宽可以达到16GB/S。
DSP的内部总线交换网络,TeraNet,提供了C66x核(包括其本地存储器),外部存储器,EDMA控制器,和片上外设之间的互连总共有10个EDMA传输控制器可以被配置起来同时执行任意存储器之间的数据传输。
本文为设计人员提供存储器访问性能评估的基本信息;提供各种操作条件下的性能测试数据;还探讨了影响存储器访问性能的一些因素。
1. 存储器系统简介
TMS320C6678有8个C66x核,每个核有:
32KB L1D(Level 1 Data) SRAM,它和DSP核运行在相同的速度上,可以被用作普通的数据存储器或数据cache。
32KB L1P(Level 1 Program) SRAM,它和DSP核运行在相同的速度上,可以被用作普通的程序存储器或程序cache。
512KB LL2(Local Level 2)SRAM,它的运行速度是DSP核的一半,可以被用作普通存储器或cache,既可以存放数据也可以存放程序。
所有DSP核共享4MB SL2(Shared Level 2)SRAM,它的运行速度是DSP核的一半,既可以存放数据也可以存放程序。TMS320C6678集成一个64-bit 1333MTS DDR3 SDRAM接口,可以支持8GB外部扩展存储器,既可以存放数据也可以存放程序。它的总线宽度也可以被配置成32bits或16bits。
存储器访问性能对DSP上软件运行的效率是非常关键的。在C6678 DSP上,所有的主模块,包括多个DSP核和多个DMA都可以访问所有的存储器。
每个DSP核每个时钟周期都可以执行最多128 bits 的load 或store操作。在1GHz的时钟频率下,DSP核访问L1D SRAM 的带宽可以达到16GB/S。当访问二级(L2)存储器或外部存储器时,访问性能主要取决于访问的方式和cache。
每个DSP核有一个内部DMA (IDMA),在1GHz的时钟频率下,它能支持高达8GB/秒的传输。但IDMA只能访问L1和LL2以及配置寄存器,它不能访问外部存储器。
DSP的内部总线交换网络,TeraNet,提供了C66x核 (包括其本地存储器) ,外部存储器, EDMA控制器,和片上外设之间的互联。总共有10个EDMA传输控制器可以被配置起来同时执行任意存储器之间的数据传输。芯片内部有两个主要的TeraNet模块,一个用128 bit总线连接每个端点,速度是DSP 核频率的1/3,理论上,在1GHz的器件上每个端口支持 5.333GB/秒的带宽;另一个TeraNet内部总线交换网络用256 bit总线连接每个端点,速度是DSP核频率的1/2,理论上,在1GHz的器件上每个端口支持16GB/秒的带宽。
总共有10个EDMA传输控制器可以被配置起来同时执行任意存储器之间的数据传输。它们中的两个连接到256-bit, 1/2 DSP核速度的 TeraNet内部总线交换网络;另外8个连接到128-bit, 1/3 DSP核速度的TeraNet内部总线交换网络。
图1展示了TMS320C6678的存储器系统。总线上的数字代表它的宽度。大部分模块运行速度是DSP核时钟的1/n,DDR的典型速度是1333MTS(Million Transfer per Second)。

图1 TMS320C6678 存储器系统
本文为设计人员提供存储器访问性能评估的基本信息;提供各种操作条件下的性能测试数据;还探讨了影响存储器访问性能的一些因素。
本文对分析以下常见问题会有所帮助:
1. 应该用DSP核还是DMA来拷贝数据?
2. 一个频繁访问存储器的函数会消耗多少时钟周期?
3. 当多个主模块共享存储器时,对某个模块的性能会有多大的影响?
本文中的大部分数据是在C6678 EVM(EValuation Module)板上测试得到的,它上面有64-bit 1333MTS的DDR 存储器。
2. DSP核,EDMA3,IDMA拷贝数据的性能比较
数据拷贝的带宽由下面三个因素中最差的一个决定:
1. 总线带宽
2. 源端吞吐量
3. 目的端吞吐量
表1 总结了C6678 上C66x 核,IDMA 和EDMA 的理论带宽。

表1 1GHz C6678上C66x核,IDMA和EDMA的理论带宽
表2 总结了C6678 EVM(64-bit 1333MTS DDR)上各种存储器端口的理论带宽。

表2 1GHz C6678上各种存储器端口的理论带宽
表3 列出了在1GHz C6678 EVM(64-bit 1333MTS DDR)上,在不同情况下用EDMA,IDMA和DSP核做大块连续数据拷贝测得的吞吐量。
在这些测试中,L1上的测试数据块的大小是8KB;IDMA LL2-》LL2 拷贝的数据块的大小是32KB;其它DSP核拷贝测试的数据块的大小是64KB,其它EDMA拷贝测试的数据块大小是128KB。
吞吐量由拷贝的数据量除以消耗的时间得到。

表3 DSP核,EDMA和IDMA数据拷贝的吞吐量比较
总的来说,DSP核可以高效地访问内部存储器,而用DSP 核访问外部存储器则不是有效利用资源的方式;IDMA非常适用于DSP核本地存储器 (L1D,L1P,LL2) 内连续数据块的传输,但它不能访问共享存储器(SL2, DDR) ;而外部存储器的访问则应尽量使用EDMA。
Cache配置显著地影响DSP核的访问性能,Prefetch buffer也能提高读访问的效率,但它们不影响EDMA和IDMA。这里所有DSP核的测试都是基于cold cache(cache 和Prefetch buffer在测试前被清空)。
对DSP核,SL2可以通过从0x0C000000开始的缺省地址空间被访问,通常这个地址空间被设置为cacheable 而且prefetchable。SL2可以通过XMC(eXtended Memory Controller) 被重映射到其它存储器空间,通常重映射空间被用作non-cacheable, nonprefetchable访问(当然它也可以被设置为cacheable 而且prefetchable)。通过缺省地址空间访问比通过重映射空间访问稍微快一点。
前面列出的EDMA 吞吐量数据是在EDMA CC0(Channel Controller 0) TC0(Transfer Controller 0)上测得的,EDMA CC1和EDMA CC2的吞吐量比EDMA CC0低一些,后面有专门的章节来比较10个EDMA传输控制器的差别。
3. DSP核访问存储器的时延
L1和DSP核的速度相同,所以DSP核每个时钟周期可以访问L1存储器一次。对一些特殊应用,需要非常快的访问小块数据,可以把L1的一部分配置成普通RAM(而不是cache)来存放数据。
通常,L1被全部配置成cache,如果cache访问命中(hit),DSP核可在一个周期完成访问;如果cache访问没有命中(miss),DSP核需要等待数据从下一级存储器中被读到cache中。
本节讨论DSP核访问内部存储器和外部DDR存储器的时延。下面是时延测试的伪代码:

3.1 DSP核访问LL2的时延
图2是在1GHz C6678 EVM上测得的DSP核访问LL2的时延。DSP核执行512个连续的LDDW(LoaD Double Word) 或STDW(STore Double Word) 指令所花的时间被测量,平均下来每个操作所花的时间被画在图中。这个测试使用了32KB L1D cache。
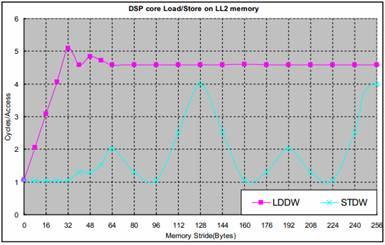
图2 DSP核访问LL2
对LDB/STB和LDW/STW的测试表明,它们的时延与LDDW/STDW相同。
由于L1D cache只有在读操作时才会被分配,DSP核读LL2总是通过L1D cache。所以,DSP核访问LL2的性能高度依赖cache。多个访问之间的地址偏移(stride)显著地影响访问效率,地址连续的访问可以充分地利用cache;大于或等于64字节的地址偏移导致每次访问都miss L1 cache因为L1D cache行大小是64 bytes。
由于L1D cache不会在写操作时被分配,并且这里的测试之前cache都被清空了,所以任何对LL2的写操作都通过L1D write buffer(4x16bytes)。对多个写操作,如果地址偏移小于16bytes,这些操作可能在write buffer中被合并成一个对LL2的写操作,从而获得接近平均每个写操作用1个时钟周期的效率。
当多个写操作之间的偏移是128bytes整数倍时,每个写操作都访问LL2的相同sub-bank(LL2包含两个banks,每个bank包含4个总线宽度为16-byte的sub-bank),对相同sub-bank的连续访问的时延是4个时钟周期。对其它的访问偏移量,连续的写操作会访问LL2不同的bank,这样的多个访问的在流水线上可以被重叠起来,从而使平均的访问时延比较小。
C66x核在C64x+核的基础上有很多改进,C66x核的L2存储器控制器和DSP核速度相同,而C64x+的L2存储器控制器的运行速度是DSP核速度的1/2。图3比较了C66x和C64x+Load/Store LL2存储器的性能

图3 C66x和C64x+核在LL2上Load/Store的时延比较
3.2 DSP核访问SL2的时延
图4 是在1GHz C6678 EVM上测得的DSP核访问SL2的时延。DSP核执行512个连续的LDDW(LoaD Double Word) 或STDW(STore Double Word)指令所花的时间被测量,平均下来每个操作所花的时间被画在图中。测试中,L1D被配置成32KB cache。
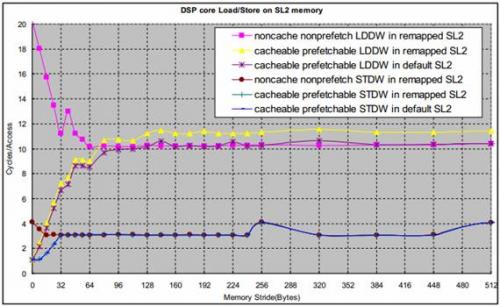
图4 DSP核访问SL2
对LDB/STB和LDW/STW的测试表明,它们的时延LDDW/STDW相同。
DSP核读SL2通常会通过L1D cache,所以,和访问LL2一样,DSP核访问SL2的性能高度依赖cache。
XMC中还有一个prefetch buffer(8x128bytes),它可以被看作是一个额外的只对读操作可用的cache。DSP核之外的每16-MB存储器块都可以通过MAR(Memory Attribute Register)的PFX(PreFetchable eXternally)bit 被配置为是否通过prefetch buffer读,使能它会对多个主模块共享存储器的效率有很大帮助;它也能显著地改善对SL2连续读的性能。不过,prefetch buffer对写操作没有任何作用。
SL2可以通过从0x0C000000开始的缺省的地址空间访问,这个空间总是cacheable,通常它也被配置为prefetchable。SL2可以通过XMC的配置被重映射到其它地址空间,通常重映射空间被用作non-cacheable, nonprefetchable 访问(当然它也可以被设置为cacheable而且prefetchable)。通过缺省地址空间访问比通过重映射空间访问稍微快一点,因为地址重映射需要一个额外的时钟周期。
由于L1D cache不会在写操作时被分配,并且这里的测试之前cache都被清空了,所以任何对SL2的写操作都通过L1D write buffer(4x16bytes)。对多个写操作,如果地址偏移小于16bytes,这些操作可能在write buffer中被合并成一个对SL2的写操作,从而获得比较高的效率。XMC也有类似的写合并buffer,它可以合并两个在32 bytes内的写操作,所以,对偏移小于32bytes的写操作,XMC的写buffer改善了写操作的性能。
当写偏移是N*256 bytes时,每个写操作总是访问SL2相同的bank(SL2存储器组织结构是4 bankx2sub-bankx 32 bytes),对相同bank的连续访问间隔是4个时钟周期。对其它的访问偏移量,连续的写操作会访问SL2不同的bank,这样的多个访问的在流水线上可以被重叠起来,从而使平均的访问时延比较小。
图5 比较了DSP核访问SL2和LL2的访问时延。对地址偏移小于16bytes的连续访问,访问SL2的性能和LL2几乎相同。而对地址偏移比较大的连续访问,访问SL2的性能比LL2差。因此,SL2最适合于存放代码。

图5 DSP核访问SL2和LL2的性能比较
3.3 DSP核访问外部DDR存储器的时延
DSP核访问外部DDR存储器高度依赖cache。当DSP核访问外部存储器时,一个传输请求会被发给XMC。根据cacheable和prefetchable的设置,传输请求可能是下列情况中的一种:
一个数据单元–如果存储器空间是non-cacheable,nonprefetchable
一个L1 cache line-如果存储器空间是cacheable而没有L2 cache,
一个L2 cache line-如果存储器空间是cacheable并且设置了L2 cache。
如果要访问的数据在L1/L2 cache或prefetch buffer中,则不会有传输请求发出。
如果被访问的空间是prefetchable的,可能还会产生额外的prefetch请求。
外部存储器的内容可以被缓存在L1 cache或/和L2 cache,或者都不用。DSP核之外的每16-MB存储器块都可以通过MAR(Memory Attribute Register)的PC(Permit Copy)bit被配置为是否通过cache访问。如果PC比特为0,这段空间就不是cacheable的。如果PC比特是1而L2 cache大小为0(所有LL2都被用作普通SRAM),那外部存储器的内容只会被L1 cache缓存。如果PC比特是1并且L2 cache大于0,则外部存储器的内容可以被L1和L2 cache同时缓存。
像访问SL2一样,对外部存储器的读操作也可以利用XMC里的prefetch buffer。它可以通过MAR(Memory Attribute Register)的PFX(PreFetchable eXternally)bit来配置。
多个访问之间的地址偏移(stride)显著地影响访问效率,地址连续的访问可以充分地利用cache和prefetch buffer;大于或等于64字节的地址偏移导致每次访问都miss L1 cache因为L1D cache行大小是64 bytes;大于或等于128字节的地址偏移导致每次访问都miss L2 cache因为L2 cache行大小是128 bytes。
如果发生cache miss,DSP需要等待外部数据传输完成。等待的时间是请求发出时间,数据传输时间或数据返回时间的总和。
图6是在1GHz C6678 EVM(64-bit 1333MTS DDR)上测得的DSP核访问DDR的时延。DSP核执行512个连续的LDDW(LoaD Double Word)或STDW(STore Double Word)指令所花的时间被测量,平均下来每个操作所花的时间被画在图中。测试中,L1D被配置成32KB cache,LL2的256KB被设置为cache。
对LDB/STB和LDW/STW的测试表明,它们的时延与LDDW/STDW相同。
注意,下面第二和第三个图实际上是第一个图左边的放大。


图6 DSP核对DDR Load/Store的时延
对地址偏移小于128 bytes的访问,性能主要受cache的影响。
L2 cache会在写操作时被分配,对任何写操作,cache控制器总是先把被访问的数据所在的cache行(128 bytes)读进L2 cache,然后在cache中改写数据。被改写是数据会在发生cache冲突或手工cache回写操作时被最终写到外部存储里。当写操作的地址偏移是1024 bytes的整数倍时,多个访问在L2 cache中发生冲突的概率很大,所以L2 cacheable写操作的时延会显著地增加。最坏的情况下,每个写操作都会导致一个cache行的回写 (之前的数据因为冲突而被替换/回写)和一个cache行的读入(新的数据被分配到cache中)。
当地址偏移大于512bytes时,DDR页(行)切换开销成为性能下降的主要因素。C6678 EVM上的DDR页(行)大小或bank宽度是8KB,而DDR3存储器包含8个banks。最坏的情况是,当访问地址偏移量是64KB时,每个读或写操作都会访问相同bank中一个新的行,而这种行切换会增加大约40个时钟周期的时延。请注意,不同的DDR存储器的时延可能会不一样。
摘要
TMS320C6678 有8 个C66x核,典型速度是1GHz,每个核有 32KB L1D SRAM,32KB L1P SRAM和512KB LL2 SRAM;所有 DSP核共享4MB SL2 SRAM。一个64-bit 1333MTS DDR3 SDRAM接口可以支持8GB外部扩展存储器。
存储器访问性能对DSP上运行的软件是非常关键的。在C6678 DSP上,所有的主模块,包括多个DSP核和多个DMA都可以访问所有的存储器。
每个DSP核每个时钟周期都可以执行最多128 bits的load或store操作。在1GHz的时钟频率下,DSP核访问L1D SRAM的带宽可以达到16GB/S。
DSP的内部总线交换网络,TeraNet,提供了C66x核(包括其本地存储器),外部存储器,EDMA控制器,和片上外设之间的互连总共有10个EDMA传输控制器可以被配置起来同时执行任意存储器之间的数据传输。
本文为设计人员提供存储器访问性能评估的基本信息;提供各种操作条件下的性能测试数据;还探讨了影响存储器访问性能的一些因素。
1. 存储器系统简介
TMS320C6678有8个C66x核,每个核有:
32KB L1D(Level 1 Data) SRAM,它和DSP核运行在相同的速度上,可以被用作普通的数据存储器或数据cache。
32KB L1P(Level 1 Program) SRAM,它和DSP核运行在相同的速度上,可以被用作普通的程序存储器或程序cache。
512KB LL2(Local Level 2)SRAM,它的运行速度是DSP核的一半,可以被用作普通存储器或cache,既可以存放数据也可以存放程序。
所有DSP核共享4MB SL2(Shared Level 2)SRAM,它的运行速度是DSP核的一半,既可以存放数据也可以存放程序。TMS320C6678集成一个64-bit 1333MTS DDR3 SDRAM接口,可以支持8GB外部扩展存储器,既可以存放数据也可以存放程序。它的总线宽度也可以被配置成32bits或16bits。
存储器访问性能对DSP上软件运行的效率是非常关键的。在C6678 DSP上,所有的主模块,包括多个DSP核和多个DMA都可以访问所有的存储器。
每个DSP核每个时钟周期都可以执行最多128 bits 的load 或store操作。在1GHz的时钟频率下,DSP核访问L1D SRAM 的带宽可以达到16GB/S。当访问二级(L2)存储器或外部存储器时,访问性能主要取决于访问的方式和cache。
每个DSP核有一个内部DMA (IDMA),在1GHz的时钟频率下,它能支持高达8GB/秒的传输。但IDMA只能访问L1和LL2以及配置寄存器,它不能访问外部存储器。
DSP的内部总线交换网络,TeraNet,提供了C66x核 (包括其本地存储器) ,外部存储器, EDMA控制器,和片上外设之间的互联。总共有10个EDMA传输控制器可以被配置起来同时执行任意存储器之间的数据传输。芯片内部有两个主要的TeraNet模块,一个用128 bit总线连接每个端点,速度是DSP 核频率的1/3,理论上,在1GHz的器件上每个端口支持 5.333GB/秒的带宽;另一个TeraNet内部总线交换网络用256 bit总线连接每个端点,速度是DSP核频率的1/2,理论上,在1GHz的器件上每个端口支持16GB/秒的带宽。
总共有10个EDMA传输控制器可以被配置起来同时执行任意存储器之间的数据传输。它们中的两个连接到256-bit, 1/2 DSP核速度的 TeraNet内部总线交换网络;另外8个连接到128-bit, 1/3 DSP核速度的TeraNet内部总线交换网络。
图1展示了TMS320C6678的存储器系统。总线上的数字代表它的宽度。大部分模块运行速度是DSP核时钟的1/n,DDR的典型速度是1333MTS(Million Transfer per Second)。
图1 TMS320C6678 存储器系统
本文为设计人员提供存储器访问性能评估的基本信息;提供各种操作条件下的性能测试数据;还探讨了影响存储器访问性能的一些因素。
本文对分析以下常见问题会有所帮助:
1. 应该用DSP核还是DMA来拷贝数据?
2. 一个频繁访问存储器的函数会消耗多少时钟周期?
3. 当多个主模块共享存储器时,对某个模块的性能会有多大的影响?
本文中的大部分数据是在C6678 EVM(EValuation Module)板上测试得到的,它上面有64-bit 1333MTS的DDR 存储器。
2. DSP核,EDMA3,IDMA拷贝数据的性能比较
数据拷贝的带宽由下面三个因素中最差的一个决定:
1. 总线带宽
2. 源端吞吐量
3. 目的端吞吐量
表1 总结了C6678 上C66x 核,IDMA 和EDMA 的理论带宽。
表1 1GHz C6678上C66x核,IDMA和EDMA的理论带宽
表2 总结了C6678 EVM(64-bit 1333MTS DDR)上各种存储器端口的理论带宽。
表2 1GHz C6678上各种存储器端口的理论带宽
表3 列出了在1GHz C6678 EVM(64-bit 1333MTS DDR)上,在不同情况下用EDMA,IDMA和DSP核做大块连续数据拷贝测得的吞吐量。
在这些测试中,L1上的测试数据块的大小是8KB;IDMA LL2-》LL2 拷贝的数据块的大小是32KB;其它DSP核拷贝测试的数据块的大小是64KB,其它EDMA拷贝测试的数据块大小是128KB。
吞吐量由拷贝的数据量除以消耗的时间得到。
表3 DSP核,EDMA和IDMA数据拷贝的吞吐量比较
总的来说,DSP核可以高效地访问内部存储器,而用DSP 核访问外部存储器则不是有效利用资源的方式;IDMA非常适用于DSP核本地存储器 (L1D,L1P,LL2) 内连续数据块的传输,但它不能访问共享存储器(SL2, DDR) ;而外部存储器的访问则应尽量使用EDMA。
Cache配置显著地影响DSP核的访问性能,Prefetch buffer也能提高读访问的效率,但它们不影响EDMA和IDMA。这里所有DSP核的测试都是基于cold cache(cache 和Prefetch buffer在测试前被清空)。
对DSP核,SL2可以通过从0x0C000000开始的缺省地址空间被访问,通常这个地址空间被设置为cacheable 而且prefetchable。SL2可以通过XMC(eXtended Memory Controller) 被重映射到其它存储器空间,通常重映射空间被用作non-cacheable, nonprefetchable访问(当然它也可以被设置为cacheable 而且prefetchable)。通过缺省地址空间访问比通过重映射空间访问稍微快一点。
前面列出的EDMA 吞吐量数据是在EDMA CC0(Channel Controller 0) TC0(Transfer Controller 0)上测得的,EDMA CC1和EDMA CC2的吞吐量比EDMA CC0低一些,后面有专门的章节来比较10个EDMA传输控制器的差别。
3. DSP核访问存储器的时延
L1和DSP核的速度相同,所以DSP核每个时钟周期可以访问L1存储器一次。对一些特殊应用,需要非常快的访问小块数据,可以把L1的一部分配置成普通RAM(而不是cache)来存放数据。
通常,L1被全部配置成cache,如果cache访问命中(hit),DSP核可在一个周期完成访问;如果cache访问没有命中(miss),DSP核需要等待数据从下一级存储器中被读到cache中。
本节讨论DSP核访问内部存储器和外部DDR存储器的时延。下面是时延测试的伪代码:
3.1 DSP核访问LL2的时延
图2是在1GHz C6678 EVM上测得的DSP核访问LL2的时延。DSP核执行512个连续的LDDW(LoaD Double Word) 或STDW(STore Double Word) 指令所花的时间被测量,平均下来每个操作所花的时间被画在图中。这个测试使用了32KB L1D cache。
图2 DSP核访问LL2
对LDB/STB和LDW/STW的测试表明,它们的时延与LDDW/STDW相同。
由于L1D cache只有在读操作时才会被分配,DSP核读LL2总是通过L1D cache。所以,DSP核访问LL2的性能高度依赖cache。多个访问之间的地址偏移(stride)显著地影响访问效率,地址连续的访问可以充分地利用cache;大于或等于64字节的地址偏移导致每次访问都miss L1 cache因为L1D cache行大小是64 bytes。
由于L1D cache不会在写操作时被分配,并且这里的测试之前cache都被清空了,所以任何对LL2的写操作都通过L1D write buffer(4x16bytes)。对多个写操作,如果地址偏移小于16bytes,这些操作可能在write buffer中被合并成一个对LL2的写操作,从而获得接近平均每个写操作用1个时钟周期的效率。
当多个写操作之间的偏移是128bytes整数倍时,每个写操作都访问LL2的相同sub-bank(LL2包含两个banks,每个bank包含4个总线宽度为16-byte的sub-bank),对相同sub-bank的连续访问的时延是4个时钟周期。对其它的访问偏移量,连续的写操作会访问LL2不同的bank,这样的多个访问的在流水线上可以被重叠起来,从而使平均的访问时延比较小。
C66x核在C64x+核的基础上有很多改进,C66x核的L2存储器控制器和DSP核速度相同,而C64x+的L2存储器控制器的运行速度是DSP核速度的1/2。图3比较了C66x和C64x+Load/Store LL2存储器的性能
图3 C66x和C64x+核在LL2上Load/Store的时延比较
3.2 DSP核访问SL2的时延
图4 是在1GHz C6678 EVM上测得的DSP核访问SL2的时延。DSP核执行512个连续的LDDW(LoaD Double Word) 或STDW(STore Double Word)指令所花的时间被测量,平均下来每个操作所花的时间被画在图中。测试中,L1D被配置成32KB cache。
图4 DSP核访问SL2
对LDB/STB和LDW/STW的测试表明,它们的时延LDDW/STDW相同。
DSP核读SL2通常会通过L1D cache,所以,和访问LL2一样,DSP核访问SL2的性能高度依赖cache。
XMC中还有一个prefetch buffer(8x128bytes),它可以被看作是一个额外的只对读操作可用的cache。DSP核之外的每16-MB存储器块都可以通过MAR(Memory Attribute Register)的PFX(PreFetchable eXternally)bit 被配置为是否通过prefetch buffer读,使能它会对多个主模块共享存储器的效率有很大帮助;它也能显著地改善对SL2连续读的性能。不过,prefetch buffer对写操作没有任何作用。
SL2可以通过从0x0C000000开始的缺省的地址空间访问,这个空间总是cacheable,通常它也被配置为prefetchable。SL2可以通过XMC的配置被重映射到其它地址空间,通常重映射空间被用作non-cacheable, nonprefetchable 访问(当然它也可以被设置为cacheable而且prefetchable)。通过缺省地址空间访问比通过重映射空间访问稍微快一点,因为地址重映射需要一个额外的时钟周期。
由于L1D cache不会在写操作时被分配,并且这里的测试之前cache都被清空了,所以任何对SL2的写操作都通过L1D write buffer(4x16bytes)。对多个写操作,如果地址偏移小于16bytes,这些操作可能在write buffer中被合并成一个对SL2的写操作,从而获得比较高的效率。XMC也有类似的写合并buffer,它可以合并两个在32 bytes内的写操作,所以,对偏移小于32bytes的写操作,XMC的写buffer改善了写操作的性能。
当写偏移是N*256 bytes时,每个写操作总是访问SL2相同的bank(SL2存储器组织结构是4 bankx2sub-bankx 32 bytes),对相同bank的连续访问间隔是4个时钟周期。对其它的访问偏移量,连续的写操作会访问SL2不同的bank,这样的多个访问的在流水线上可以被重叠起来,从而使平均的访问时延比较小。
图5 比较了DSP核访问SL2和LL2的访问时延。对地址偏移小于16bytes的连续访问,访问SL2的性能和LL2几乎相同。而对地址偏移比较大的连续访问,访问SL2的性能比LL2差。因此,SL2最适合于存放代码。
图5 DSP核访问SL2和LL2的性能比较
3.3 DSP核访问外部DDR存储器的时延
DSP核访问外部DDR存储器高度依赖cache。当DSP核访问外部存储器时,一个传输请求会被发给XMC。根据cacheable和prefetchable的设置,传输请求可能是下列情况中的一种:
一个数据单元–如果存储器空间是non-cacheable,nonprefetchable
一个L1 cache line-如果存储器空间是cacheable而没有L2 cache,
一个L2 cache line-如果存储器空间是cacheable并且设置了L2 cache。
如果要访问的数据在L1/L2 cache或prefetch buffer中,则不会有传输请求发出。
如果被访问的空间是prefetchable的,可能还会产生额外的prefetch请求。
外部存储器的内容可以被缓存在L1 cache或/和L2 cache,或者都不用。DSP核之外的每16-MB存储器块都可以通过MAR(Memory Attribute Register)的PC(Permit Copy)bit被配置为是否通过cache访问。如果PC比特为0,这段空间就不是cacheable的。如果PC比特是1而L2 cache大小为0(所有LL2都被用作普通SRAM),那外部存储器的内容只会被L1 cache缓存。如果PC比特是1并且L2 cache大于0,则外部存储器的内容可以被L1和L2 cache同时缓存。
像访问SL2一样,对外部存储器的读操作也可以利用XMC里的prefetch buffer。它可以通过MAR(Memory Attribute Register)的PFX(PreFetchable eXternally)bit来配置。
多个访问之间的地址偏移(stride)显著地影响访问效率,地址连续的访问可以充分地利用cache和prefetch buffer;大于或等于64字节的地址偏移导致每次访问都miss L1 cache因为L1D cache行大小是64 bytes;大于或等于128字节的地址偏移导致每次访问都miss L2 cache因为L2 cache行大小是128 bytes。
如果发生cache miss,DSP需要等待外部数据传输完成。等待的时间是请求发出时间,数据传输时间或数据返回时间的总和。
图6是在1GHz C6678 EVM(64-bit 1333MTS DDR)上测得的DSP核访问DDR的时延。DSP核执行512个连续的LDDW(LoaD Double Word)或STDW(STore Double Word)指令所花的时间被测量,平均下来每个操作所花的时间被画在图中。测试中,L1D被配置成32KB cache,LL2的256KB被设置为cache。
对LDB/STB和LDW/STW的测试表明,它们的时延与LDDW/STDW相同。
注意,下面第二和第三个图实际上是第一个图左边的放大。
图6 DSP核对DDR Load/Store的时延
对地址偏移小于128 bytes的访问,性能主要受cache的影响。
L2 cache会在写操作时被分配,对任何写操作,cache控制器总是先把被访问的数据所在的cache行(128 bytes)读进L2 cache,然后在cache中改写数据。被改写是数据会在发生cache冲突或手工cache回写操作时被最终写到外部存储里。当写操作的地址偏移是1024 bytes的整数倍时,多个访问在L2 cache中发生冲突的概率很大,所以L2 cacheable写操作的时延会显著地增加。最坏的情况下,每个写操作都会导致一个cache行的回写 (之前的数据因为冲突而被替换/回写)和一个cache行的读入(新的数据被分配到cache中)。
当地址偏移大于512bytes时,DDR页(行)切换开销成为性能下降的主要因素。C6678 EVM上的DDR页(行)大小或bank宽度是8KB,而DDR3存储器包含8个banks。最坏的情况是,当访问地址偏移量是64KB时,每个读或写操作都会访问相同bank中一个新的行,而这种行切换会增加大约40个时钟周期的时延。请注意,不同的DDR存储器的时延可能会不一样。

 举报
举报




