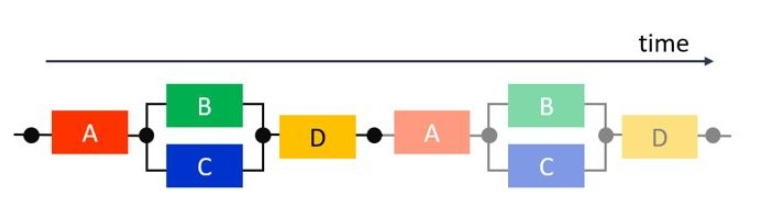
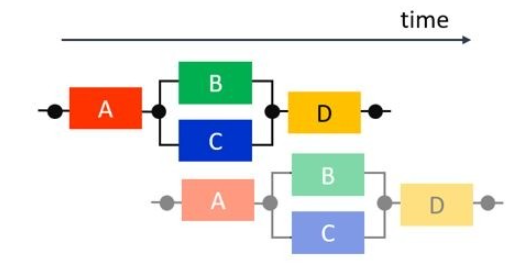
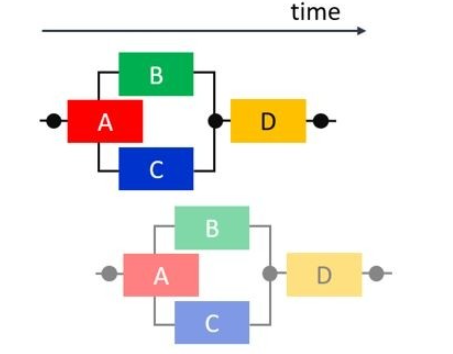
阻止任务级别并行性的常见情况:
1. 单产出单消耗模型违例(Single-producer-consumerviolations)
为了使 VitisHLS 执行 DATAFLOW 优化,任务之间传递的所有元素都必须遵循单产出单消耗模型。每个变量必须从单个任务驱动,并且只能由单个任务使用。在下面的代码示例中是典型的单产出单消耗模型违例,单一的数据流 temp1 同时被 Loop2 和 Loop3 消耗。要解决这个问题很容易,就是将两个任务都要消耗的数据流复制成两个,如右图的 Split 函数。当 temp1数据流被复制为 temp2 和 temp3 后,LOOP1,2,3 就可以实现任务级流水线了。
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N];
Loop1: for(int i = 0; i 《 N; i++) {
temp1[i] = data_in[i] * scale;
}
Loop2: for(int j = 0; j 《 N; j++) {
data_out1[j] = temp1[j] * 123;
}
Loop3: for(int k = 0; k 《 N; k++) {
data_out2[k] = temp1[k] * 456;
}
}
void Split (in[N], out1[N], out2[N]) {
// Duplicated data
L1:for(int i=1;i《N;i++) {
out1[i] = in[i];
out2[i] = in[i];
}
}
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N], temp2[N]。 temp3[N];
Loop1: for(int i = 0; i 《 N; i++) {
temp1[i] = data_in[i] * scale;
}
Split(temp1, temp2, temp3);
Loop2: for(int j = 0; j 《 N; j++) {
data_out1[j] = temp2[j] * 123;
}
Loop3: for(int k = 0; k 《 N; k++) {
data_out2[k] = temp3[k] * 456;
}
2. 旁路任务 Bypassing Tasks
正常情况下我们期望流水线任务是一个接着一个的产出并消耗,然而像下面这个例子中,Loop1 产生了 Temp1和Temp2 两个数据流,但是在下一个任务 Loop2 中只有 temp1 参与了运算,而 temp2 就被旁支了。Loop3 任务的执行依赖 Loop2 任务产生的 temp3 数据,所以 Loop2 和 Loop3 因为数据依赖的关系无法并行执行。
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N], temp2[N]。 temp3[N];
Loop1: for(int i = 0; i 《 N; i++) {
temp1[i] = data_in[i] * scale;
temp2[i] = data_in[i] 》》 scale;
}
Loop2: for(int j = 0; j 《 N; j++) {
temp3[j] = temp1[j] + 123;
}
Loop3: for(int k = 0; k 《N; k++) {
data_out[k] = temp2[k] + temp3[k];
}
}
3. 任务间双向反馈 Feedbackbetween Tasks
假如说当前任务的结果,需要作为之前一个任务的输入的话,就形成了任务之间的数据反馈,它打乱了流水线从上级一直往下级输送数据流的规则。这时候 HLS 就会给出警告或者报错,有可能完成不了 dataflow 优化了。有一种特例是支持的:使用 hls::stream 格式的数据流反馈。
我们分析以下代码的内容:
当第一个程序 firstProc 执行的时候,hls::stream 格式的数据流 forwardOUT 被写入了初始化为10的数值 fromSecond 。由于 hls::stream 格式的数据本身不支持初始化操作,所以这样的操作避免了违反单产出单消耗原则。之后的迭代里,firstProc 通过 backwardIN 接口从 hls :: stream 读取数值写入 forwardOUT 中。
在第二个程序 secondProc 执行的时候,secondProc 读取 forwardIN 上的值,将其加1,然后通过按执行顺序倒退的反馈流将其发送回 FirstProc。从第二次执行开始,firstProc 将使用从流中读取的值进行计算,并且两个过程可以使用第一次执行的初始值,通过正向和反馈通信永远保持下去。这种交互式的反馈中,包含数据流的双向反馈机制,但是它就像货物一直在从左手倒到右手再从右手倒到左手一样,可以不违反 Dataflow 的规范,一直进行下去。
#include “ap_axi_sdata.h”
#include “hls_stream.h”
void firstProc(hls::stream《int》 &forwardOUT, hls::stream《int》 &backwardIN) {
static bool first = true;
int fromSecond;
//Initialize stream
if (first)
fromSecond = 10; // Initial stream value
else
//Read from stream
fromSecond = backwardIN.read(); //Feedback value
first = false;
//Write to stream
forwardOUT.write(fromSecond*2);
}
void secondProc(hls::stream《int》 &forwardIN, hls::stream《int》 &backwardOUT)
{
backwardOUT.write(forwardIN.read() + 1);
}
void top(。..) {
#pragma HLS dataflow
hls::stream《int》 forward, backward;
firstProc(forward, backward);
secondProc(forward, backward);
}
4. 含有条件判断的任务流水
DATAFLOW 优化不会优化有条件执行的任务。下面的示例展现了这个违例。在此示例中,有条件地执行 Loop1 和 Loop2 会阻止 Vitis HLS 优化这些循环之间的数据流,因为 sel 条件直接控制了任务中的数据有可能不会从一个循环流到下一个循环。
void foo(int data_in1[N], int data_out[N], int sel) {
int temp1[N], temp2[N];
if (sel) {
Loop1: for(int i = 0; i 《 N; i++) {
temp1[i] = data_in[i] * 123;
temp2[i] = data_in[i];
}
} else {
Loop2: for(int j = 0; j 《 N; j++) {
temp1[j] = data_in[j] * 321;
temp2[j] = data_in[j];
}
}
Loop3: for(int k = 0; k 《 N; k++) {
data_out[k] = temp1[k] * temp2[k];
}
}
但是我们都知道,其实这些任务之间存在条件判断和选择是非常常见的情况,只需要稍微改变代码风格就可以既保留条件判断,又完成任务流水。为了确保在所有情况下都执行每个循环,我们将条件语句下变化的 Temp1 移入第一个循环。这两个循环始终执行,并且数据始终从一个循环流向下一个循环。
void foo(int data_in[N], int data_out[N], int sel) {
int temp1[N], temp2[N];
Loop1: for(int i = 0; i 《 N; i++) {
if (sel) {
temp1[i] = data_in[i] * 123;
} else {
temp1[i] = data_in[i] * 321;
}
}
Loop2: for(int j = 0; j 《 N; j++) {
temp2[j] = data_in[j];
}
Loop3: for(int k = 0; k 《 N; k++) {
data_out[k] = temp1[k] * temp2[k];
}
}
5. 有多种退出机制的循环
含有多种退出机制的循环不能被包含在流水线区域内,我们来数一数 Loop2 一共有多少种循环退出条件:
1. 由 for 循环定义的 K》N 的情况;
2. 由 switch 条件定义的 default 情况;
3. 由 switch 条件定义的 continue 情况
由于循环的退出条件始终由循环边界定义,因此使用 break 或 continue 语句将禁止在DATAFLOW 区域中使用循环。
void multi_exit(din_t data_in[N], dsc_t scale, dsel_t select, dout_t
data_out[N]) {
dout_t temp1[N], temp2[N];
int i,k;
Loop1:
for(i = 0; i 《 N; i++) {
temp1[i] = data_in[i] * scale;
temp2[i] = data_in[i] 》》 scale;
}
Loop2:
for(k = 0; k 《 N; k++) {
switch(select) {
case 0: data_out[k] = temp1[k] + temp2[k];
case 1: continue;
default: break;
}
}
}
我们理解了可能阻止任务流水线的 5 种经典情况后,我们最后推出适用于 Vitis HLS 的Dataflow 优化的两种规范形式 (canonical forms) ,一种直接应用于函数,一种应用于 for循环。我们可以发现规范形式严格遵守了单产出单消耗的规则。
1. 适用于子程序没有被内联 (inline) 的规范形式
void dataflow(Input0, Input1, Output0, Output1)
{
#pragma HLS dataflow
UserDataType C0, C1, C2;
func1(read Input0, read Input1, write C0, write C1);
func2(read C0, read C1, write C2);
func3(read C2, write Output0, write Output1);
}
2. 适用于循环体内的任务流水的规范形式:
对于 for 循环 (其中没有内联函数的地方),循环变量应具有:
a. 在 for 循环的标题中声明初始值,并设置为 0。
b. 循环条件N是一个正数值常数或常数函数参数。
c. 循环的递增量为1。
d. Dataflow 指令必须位于循环内部。
void dataflow(Input0, Input1, Output0, Output1)
{
for (int i = 0; i 《 N; i++)
{
#pragma HLS dataflow
UserDataType C0, C1, C2;
func1(read Input0, read Input1, write C0, write C1);
func2(read C0, read C0, read C1, write C2);
func3(read C2, write Output0, write Output1);
}
}
阻止任务级别并行性的常见情况:
1. 单产出单消耗模型违例(Single-producer-consumerviolations)
为了使 VitisHLS 执行 DATAFLOW 优化,任务之间传递的所有元素都必须遵循单产出单消耗模型。每个变量必须从单个任务驱动,并且只能由单个任务使用。在下面的代码示例中是典型的单产出单消耗模型违例,单一的数据流 temp1 同时被 Loop2 和 Loop3 消耗。要解决这个问题很容易,就是将两个任务都要消耗的数据流复制成两个,如右图的 Split 函数。当 temp1数据流被复制为 temp2 和 temp3 后,LOOP1,2,3 就可以实现任务级流水线了。
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N];
Loop1: for(int i = 0; i 《 N; i++) {
temp1[i] = data_in[i] * scale;
}
Loop2: for(int j = 0; j 《 N; j++) {
data_out1[j] = temp1[j] * 123;
}
Loop3: for(int k = 0; k 《 N; k++) {
data_out2[k] = temp1[k] * 456;
}
}
void Split (in[N], out1[N], out2[N]) {
// Duplicated data
L1:for(int i=1;i《N;i++) {
out1[i] = in[i];
out2[i] = in[i];
}
}
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N], temp2[N]。 temp3[N];
Loop1: for(int i = 0; i 《 N; i++) {
temp1[i] = data_in[i] * scale;
}
Split(temp1, temp2, temp3);
Loop2: for(int j = 0; j 《 N; j++) {
data_out1[j] = temp2[j] * 123;
}
Loop3: for(int k = 0; k 《 N; k++) {
data_out2[k] = temp3[k] * 456;
}
2. 旁路任务 Bypassing Tasks
正常情况下我们期望流水线任务是一个接着一个的产出并消耗,然而像下面这个例子中,Loop1 产生了 Temp1和Temp2 两个数据流,但是在下一个任务 Loop2 中只有 temp1 参与了运算,而 temp2 就被旁支了。Loop3 任务的执行依赖 Loop2 任务产生的 temp3 数据,所以 Loop2 和 Loop3 因为数据依赖的关系无法并行执行。
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N], temp2[N]。 temp3[N];
Loop1: for(int i = 0; i 《 N; i++) {
temp1[i] = data_in[i] * scale;
temp2[i] = data_in[i] 》》 scale;
}
Loop2: for(int j = 0; j 《 N; j++) {
temp3[j] = temp1[j] + 123;
}
Loop3: for(int k = 0; k 《N; k++) {
data_out[k] = temp2[k] + temp3[k];
}
}
3. 任务间双向反馈 Feedbackbetween Tasks
假如说当前任务的结果,需要作为之前一个任务的输入的话,就形成了任务之间的数据反馈,它打乱了流水线从上级一直往下级输送数据流的规则。这时候 HLS 就会给出警告或者报错,有可能完成不了 dataflow 优化了。有一种特例是支持的:使用 hls::stream 格式的数据流反馈。
我们分析以下代码的内容:
当第一个程序 firstProc 执行的时候,hls::stream 格式的数据流 forwardOUT 被写入了初始化为10的数值 fromSecond 。由于 hls::stream 格式的数据本身不支持初始化操作,所以这样的操作避免了违反单产出单消耗原则。之后的迭代里,firstProc 通过 backwardIN 接口从 hls :: stream 读取数值写入 forwardOUT 中。
在第二个程序 secondProc 执行的时候,secondProc 读取 forwardIN 上的值,将其加1,然后通过按执行顺序倒退的反馈流将其发送回 FirstProc。从第二次执行开始,firstProc 将使用从流中读取的值进行计算,并且两个过程可以使用第一次执行的初始值,通过正向和反馈通信永远保持下去。这种交互式的反馈中,包含数据流的双向反馈机制,但是它就像货物一直在从左手倒到右手再从右手倒到左手一样,可以不违反 Dataflow 的规范,一直进行下去。
#include “ap_axi_sdata.h”
#include “hls_stream.h”
void firstProc(hls::stream《int》 &forwardOUT, hls::stream《int》 &backwardIN) {
static bool first = true;
int fromSecond;
//Initialize stream
if (first)
fromSecond = 10; // Initial stream value
else
//Read from stream
fromSecond = backwardIN.read(); //Feedback value
first = false;
//Write to stream
forwardOUT.write(fromSecond*2);
}
void secondProc(hls::stream《int》 &forwardIN, hls::stream《int》 &backwardOUT)
{
backwardOUT.write(forwardIN.read() + 1);
}
void top(。..) {
#pragma HLS dataflow
hls::stream《int》 forward, backward;
firstProc(forward, backward);
secondProc(forward, backward);
}
4. 含有条件判断的任务流水
DATAFLOW 优化不会优化有条件执行的任务。下面的示例展现了这个违例。在此示例中,有条件地执行 Loop1 和 Loop2 会阻止 Vitis HLS 优化这些循环之间的数据流,因为 sel 条件直接控制了任务中的数据有可能不会从一个循环流到下一个循环。
void foo(int data_in1[N], int data_out[N], int sel) {
int temp1[N], temp2[N];
if (sel) {
Loop1: for(int i = 0; i 《 N; i++) {
temp1[i] = data_in[i] * 123;
temp2[i] = data_in[i];
}
} else {
Loop2: for(int j = 0; j 《 N; j++) {
temp1[j] = data_in[j] * 321;
temp2[j] = data_in[j];
}
}
Loop3: for(int k = 0; k 《 N; k++) {
data_out[k] = temp1[k] * temp2[k];
}
}
但是我们都知道,其实这些任务之间存在条件判断和选择是非常常见的情况,只需要稍微改变代码风格就可以既保留条件判断,又完成任务流水。为了确保在所有情况下都执行每个循环,我们将条件语句下变化的 Temp1 移入第一个循环。这两个循环始终执行,并且数据始终从一个循环流向下一个循环。
void foo(int data_in[N], int data_out[N], int sel) {
int temp1[N], temp2[N];
Loop1: for(int i = 0; i 《 N; i++) {
if (sel) {
temp1[i] = data_in[i] * 123;
} else {
temp1[i] = data_in[i] * 321;
}
}
Loop2: for(int j = 0; j 《 N; j++) {
temp2[j] = data_in[j];
}
Loop3: for(int k = 0; k 《 N; k++) {
data_out[k] = temp1[k] * temp2[k];
}
}
5. 有多种退出机制的循环
含有多种退出机制的循环不能被包含在流水线区域内,我们来数一数 Loop2 一共有多少种循环退出条件:
1. 由 for 循环定义的 K》N 的情况;
2. 由 switch 条件定义的 default 情况;
3. 由 switch 条件定义的 continue 情况
由于循环的退出条件始终由循环边界定义,因此使用 break 或 continue 语句将禁止在DATAFLOW 区域中使用循环。
void multi_exit(din_t data_in[N], dsc_t scale, dsel_t select, dout_t
data_out[N]) {
dout_t temp1[N], temp2[N];
int i,k;
Loop1:
for(i = 0; i 《 N; i++) {
temp1[i] = data_in[i] * scale;
temp2[i] = data_in[i] 》》 scale;
}
Loop2:
for(k = 0; k 《 N; k++) {
switch(select) {
case 0: data_out[k] = temp1[k] + temp2[k];
case 1: continue;
default: break;
}
}
}
我们理解了可能阻止任务流水线的 5 种经典情况后,我们最后推出适用于 Vitis HLS 的Dataflow 优化的两种规范形式 (canonical forms) ,一种直接应用于函数,一种应用于 for循环。我们可以发现规范形式严格遵守了单产出单消耗的规则。
1. 适用于子程序没有被内联 (inline) 的规范形式
void dataflow(Input0, Input1, Output0, Output1)
{
#pragma HLS dataflow
UserDataType C0, C1, C2;
func1(read Input0, read Input1, write C0, write C1);
func2(read C0, read C1, write C2);
func3(read C2, write Output0, write Output1);
}
2. 适用于循环体内的任务流水的规范形式:
对于 for 循环 (其中没有内联函数的地方),循环变量应具有:
a. 在 for 循环的标题中声明初始值,并设置为 0。
b. 循环条件N是一个正数值常数或常数函数参数。
c. 循环的递增量为1。
d. Dataflow 指令必须位于循环内部。
void dataflow(Input0, Input1, Output0, Output1)
{
for (int i = 0; i 《 N; i++)
{
#pragma HLS dataflow
UserDataType C0, C1, C2;
func1(read Input0, read Input1, write C0, write C1);
func2(read C0, read C0, read C1, write C2);
func3(read C2, write Output0, write Output1);
}
}

 举报
举报