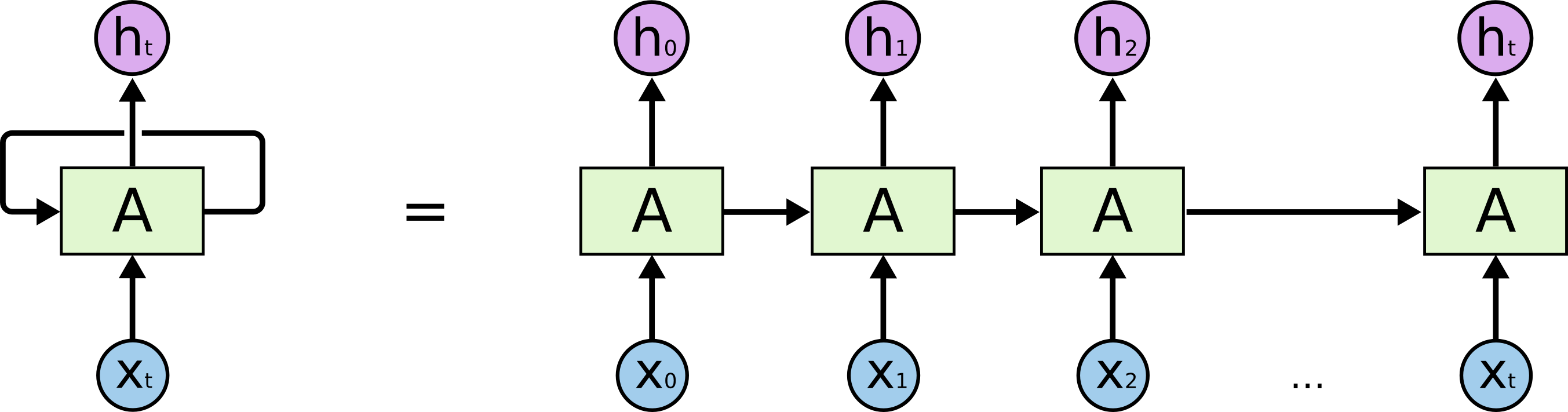
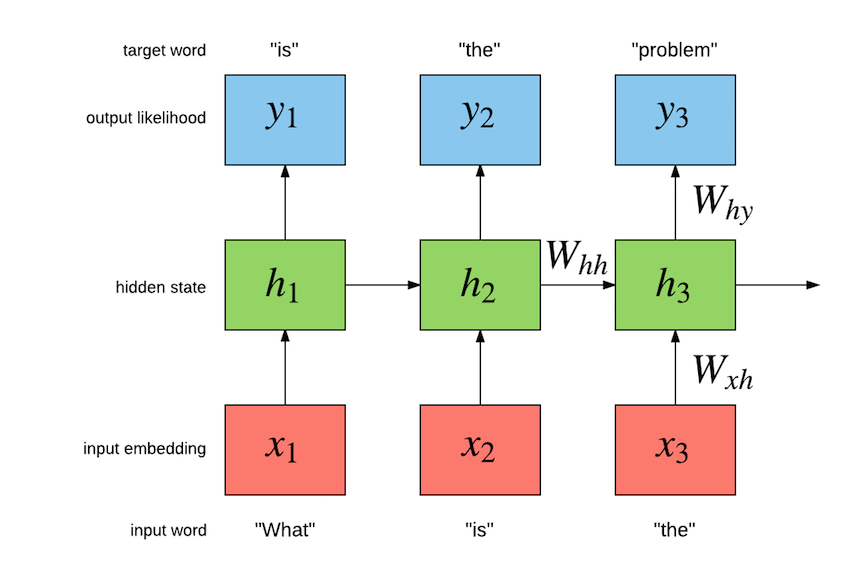
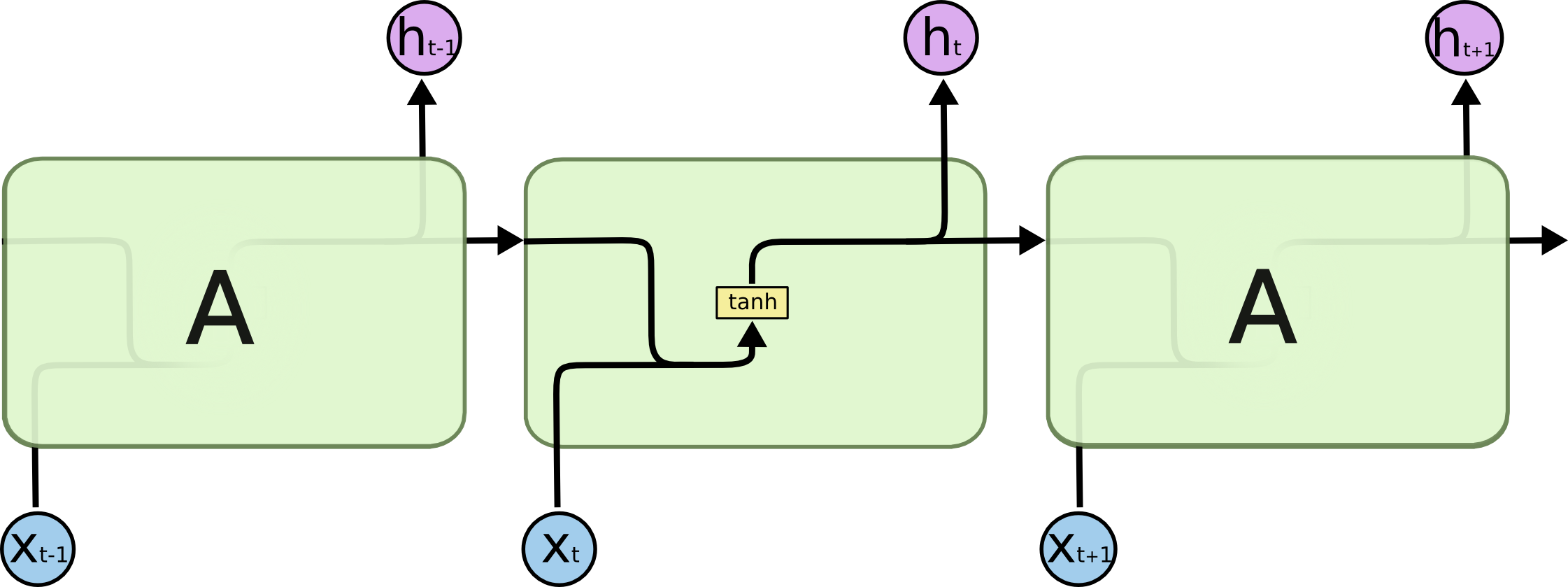
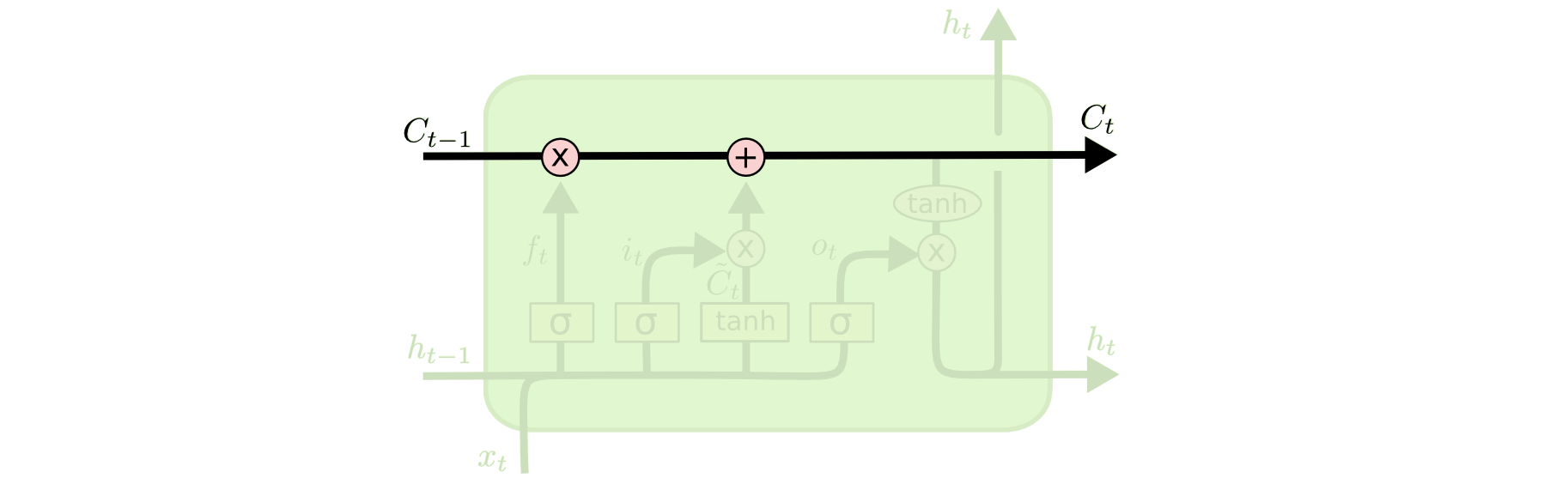
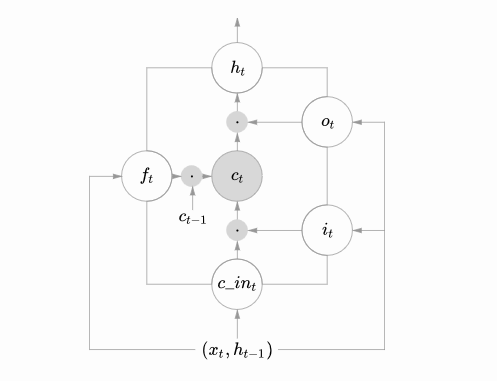
逐步解析LSTM
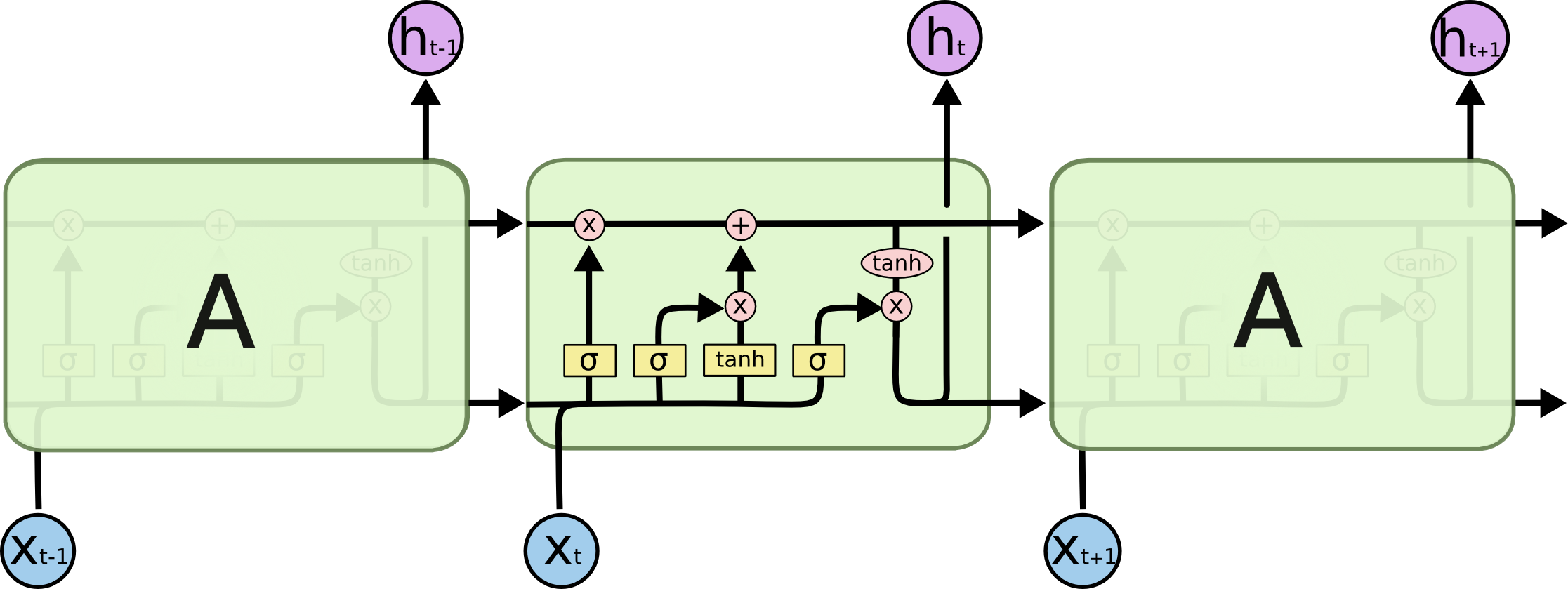
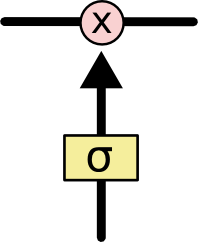
LSTM第一步是用来决定什么信息可以通过cell state。这个决定由“forget gate”层通过sigmoid来控制,它会根据上一时刻的输出h t−1 ht−1 和当前输入x t xt 来产生一个0到1 的f t ft 值,来决定是否让上一时刻学到的信息C t−1 Ct−1 通过或部分通过。如下:

举个例子来说就是,我们在之前的句子中学到了很多东西,一些东西对当前来讲是没用的,可以对它进行选择性地过滤。
第二步是产生我们需要更新的新信息。这一步包含两部分,第一个是一个“input gate”层通过sigmoid来决定哪些值用来更新,第二个是一个tanh层用来生成新的候选值C ~ t C~t ,它作为当前层产生的候选值可能会添加到cell state中。我们会把这两部分产生的值结合来进行更新。
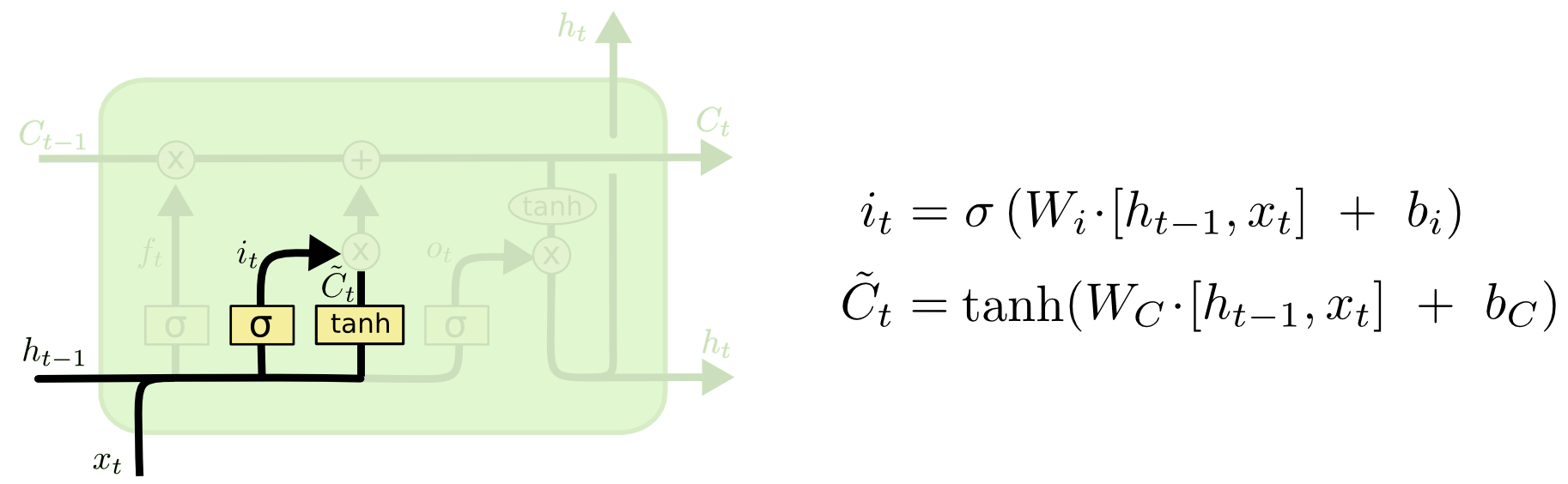
现在我们对老的cell state进行更新,首先,我们将老的cell state乘以f t ft 来忘掉我们不需要的信息,然后再与i t ∗C ~ t it∗C~t 相加,得到了候选值。
一二步结合起来就是丢掉不需要的信息,添加新信息的过程:
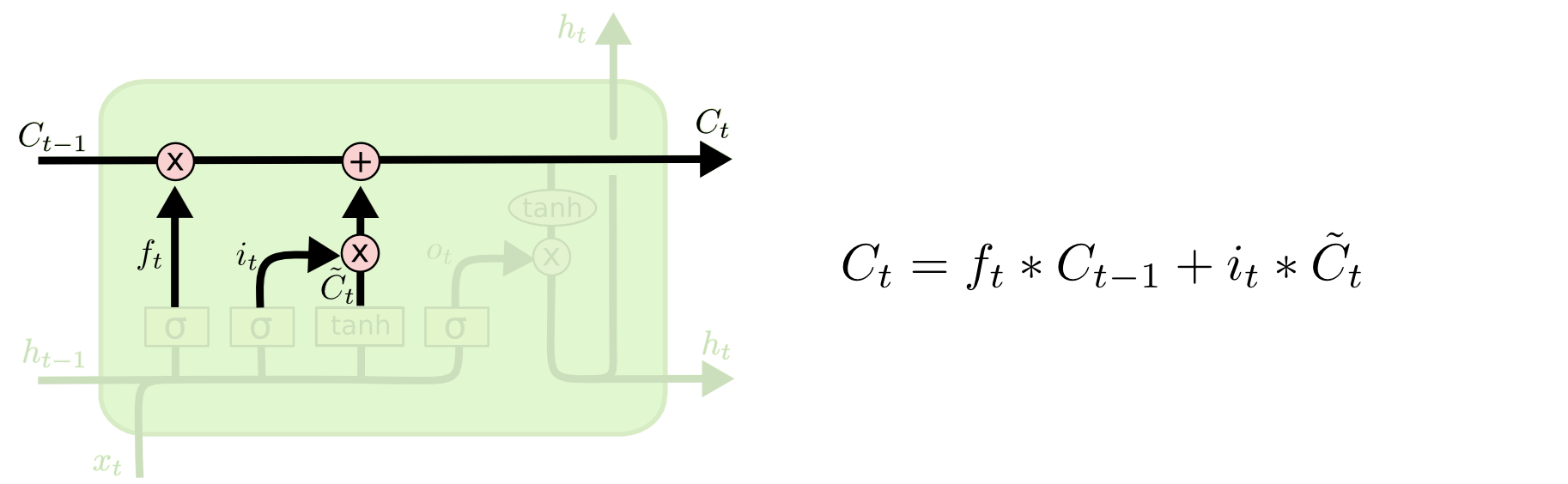
举个例子就是,在前面的句子中我们保存的是张三的信息,现在有了新的李四信息,我们需要把张三的信息丢弃掉,然后把李四的信息保存下来。
最后一步是决定模型的输出,首先是通过sigmoid层来得到一个初始输出,然后使用tanh将
C t Ct 值缩放到-1到1间,再与sigmoid得到的输出逐对相乘,从而得到模型的输出。
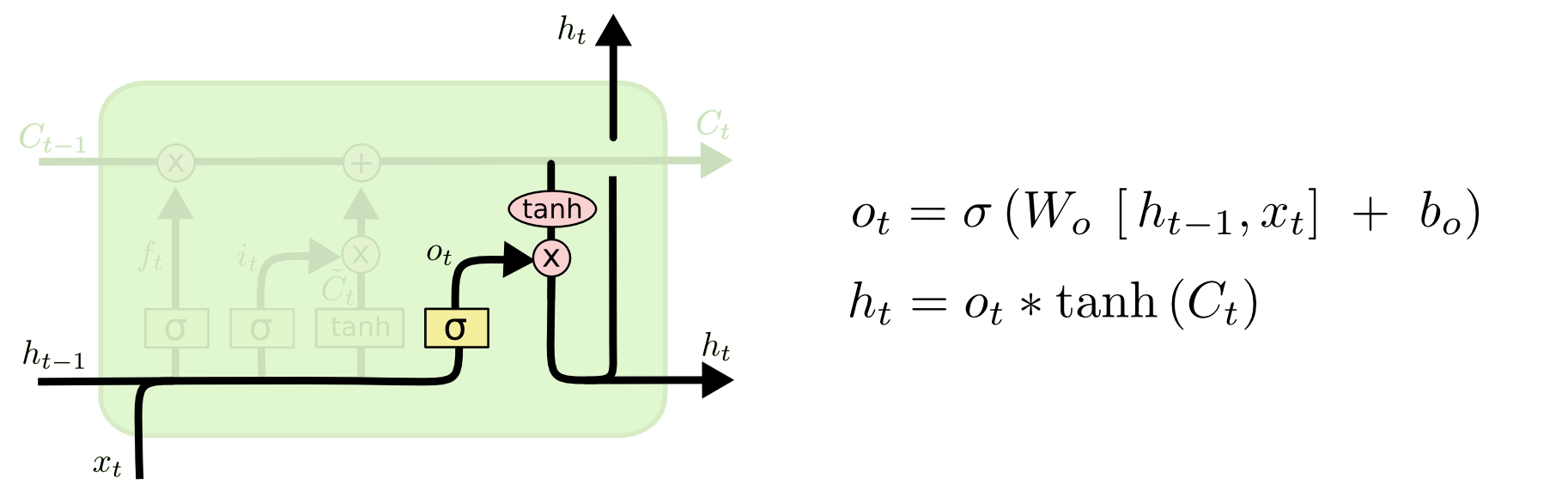
这显然可以理解,首先sigmoid函数的输出是不考虑先前时刻学到的信息的输出,tanh函数是对先前学到信息的压缩处理,起到稳定数值的作用,两者的结合学习就是递归神经网络的学习思想。至于模型是如何学习的,那就是后向传播误差学习权重的一个过程了。
上面是对LSTM一个典型结构的理解,当然,它也会有一些结构上的变形,但思想基本不变,这里也就不多讲了。
逐步解析LSTM
LSTM第一步是用来决定什么信息可以通过cell state。这个决定由“forget gate”层通过sigmoid来控制,它会根据上一时刻的输出h t−1 ht−1 和当前输入x t xt 来产生一个0到1 的f t ft 值,来决定是否让上一时刻学到的信息C t−1 Ct−1 通过或部分通过。如下:
举个例子来说就是,我们在之前的句子中学到了很多东西,一些东西对当前来讲是没用的,可以对它进行选择性地过滤。
第二步是产生我们需要更新的新信息。这一步包含两部分,第一个是一个“input gate”层通过sigmoid来决定哪些值用来更新,第二个是一个tanh层用来生成新的候选值C ~ t C~t ,它作为当前层产生的候选值可能会添加到cell state中。我们会把这两部分产生的值结合来进行更新。
现在我们对老的cell state进行更新,首先,我们将老的cell state乘以f t ft 来忘掉我们不需要的信息,然后再与i t ∗C ~ t it∗C~t 相加,得到了候选值。
一二步结合起来就是丢掉不需要的信息,添加新信息的过程:
举个例子就是,在前面的句子中我们保存的是张三的信息,现在有了新的李四信息,我们需要把张三的信息丢弃掉,然后把李四的信息保存下来。
最后一步是决定模型的输出,首先是通过sigmoid层来得到一个初始输出,然后使用tanh将
C t Ct 值缩放到-1到1间,再与sigmoid得到的输出逐对相乘,从而得到模型的输出。
这显然可以理解,首先sigmoid函数的输出是不考虑先前时刻学到的信息的输出,tanh函数是对先前学到信息的压缩处理,起到稳定数值的作用,两者的结合学习就是递归神经网络的学习思想。至于模型是如何学习的,那就是后向传播误差学习权重的一个过程了。
上面是对LSTM一个典型结构的理解,当然,它也会有一些结构上的变形,但思想基本不变,这里也就不多讲了。

 举报
举报