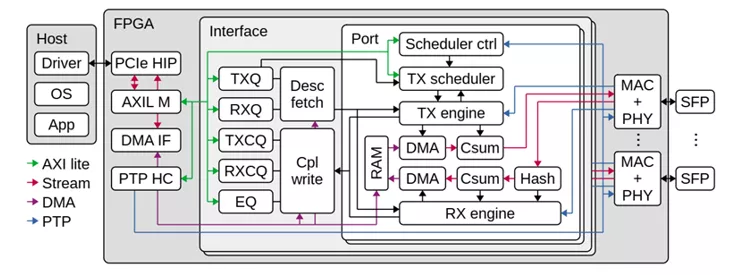
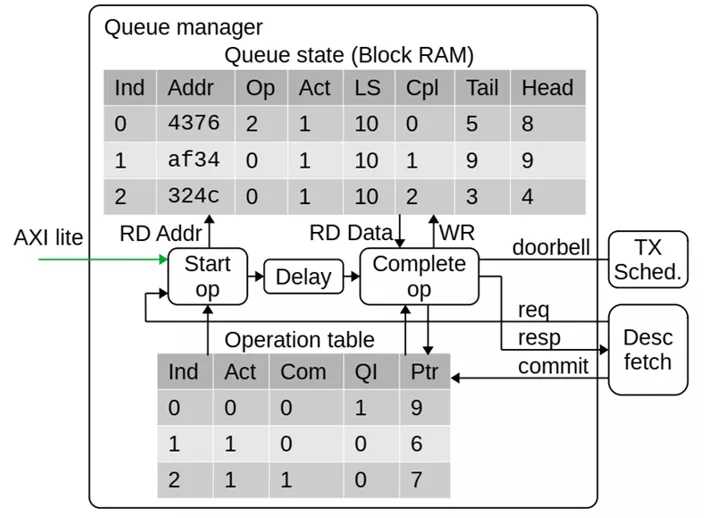
高性能数据中心的网络演进趋势
软硬件协同优化方法
在1Gbps时代,由操作系统网络、协议栈和进程调度引起的开销是可以接受的,但是随着定制化硬件的性能越来越高,网络协议栈和进程上下文切换引起的开销变得不可接受。针对协议栈的开销,人们提出了分段卸载功能,将数据面卸载到可编程网卡设备而在处理器上仅对控制面进行处理;在用户侧,应用程序通过BSD Socket接口和协议栈通信,然而协议栈进程和网卡驱动程序位于内核态,频繁发生的用户态和内核态上下文切换和数据缓冲区的拷贝带来了极大的CPU开销。为了解决这个问题,提出了诸如英特尔的DPDK的用户态协议栈,这些协议栈大多涉及或支持无锁的Ring操作,更换了用户Socket API,采用内存重映射等技术实现DMA零拷贝技术。可见,采用软硬件协同设计方法是优化网络中心的最佳方案。
RDMA技术
RDMA(RemoteDirect Memory Access)技术全称远程直接内存访问,就是为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA有以下三个特性:
Remote:无CPU参与,数据通过网络与远程机器间进行数据传输。
Direct:没有内核态的切换,有关发送传输的所有内容都卸载到网卡上。
Memory:在用户空间虚拟内存与RNIC网卡直接进行数据传输不涉及到系统内核,没有额外的数据移动和复制。
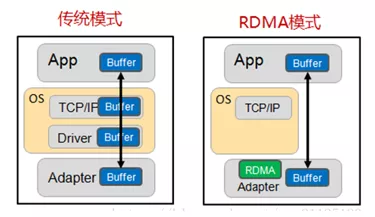
值得注意的是,RDMA没有使用标准的TCP/IP协议,而是提出了自己的一套传输协议,因此不支持广域网的传输,为了支持公有云的设计,RDMA在承载网络上设计了三套标准。
1)实现在InfiniBand网络。InfiniBand是专为RDMA设计的一套网络,在硬件级别保证数据可靠传输。需要专用的IB交换机和IB网卡,不支持Internet连接,主要适用于私有云和分布式计算。
2)RoCE(RDMAover Converged Ethernet),分为V1版本和V2版本。RoCEV1将RDMA协议运行在以太网协议上,而RoCEV2将RDMA协议运行在UDP协议上。构建RoCE网络需要专用网卡,但是交换机可以兼容标准以太网交换机,因此可以用于构建公有云和数据中心。
3)iWarp(internetWide Area RDMA Protocol),iWarp将RDMA协议运行在TCP协议上,与RoCE具有类似特性。
目前,RoCE由于支持Internet并且较iWarp协议更加简单,拥有较大的市场和更好的前景。
另外,针对Smart NIC的研究现在也被推上高潮,由于采用了嵌入式的CPU,智能网卡可以进一步降低对Host主机的依赖,因此正在被数据中心广泛采用。
高性能数据中心的网络演进趋势
软硬件协同优化方法
在1Gbps时代,由操作系统网络、协议栈和进程调度引起的开销是可以接受的,但是随着定制化硬件的性能越来越高,网络协议栈和进程上下文切换引起的开销变得不可接受。针对协议栈的开销,人们提出了分段卸载功能,将数据面卸载到可编程网卡设备而在处理器上仅对控制面进行处理;在用户侧,应用程序通过BSD Socket接口和协议栈通信,然而协议栈进程和网卡驱动程序位于内核态,频繁发生的用户态和内核态上下文切换和数据缓冲区的拷贝带来了极大的CPU开销。为了解决这个问题,提出了诸如英特尔的DPDK的用户态协议栈,这些协议栈大多涉及或支持无锁的Ring操作,更换了用户Socket API,采用内存重映射等技术实现DMA零拷贝技术。可见,采用软硬件协同设计方法是优化网络中心的最佳方案。
RDMA技术
RDMA(RemoteDirect Memory Access)技术全称远程直接内存访问,就是为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA有以下三个特性:
Remote:无CPU参与,数据通过网络与远程机器间进行数据传输。
Direct:没有内核态的切换,有关发送传输的所有内容都卸载到网卡上。
Memory:在用户空间虚拟内存与RNIC网卡直接进行数据传输不涉及到系统内核,没有额外的数据移动和复制。
值得注意的是,RDMA没有使用标准的TCP/IP协议,而是提出了自己的一套传输协议,因此不支持广域网的传输,为了支持公有云的设计,RDMA在承载网络上设计了三套标准。
1)实现在InfiniBand网络。InfiniBand是专为RDMA设计的一套网络,在硬件级别保证数据可靠传输。需要专用的IB交换机和IB网卡,不支持Internet连接,主要适用于私有云和分布式计算。
2)RoCE(RDMAover Converged Ethernet),分为V1版本和V2版本。RoCEV1将RDMA协议运行在以太网协议上,而RoCEV2将RDMA协议运行在UDP协议上。构建RoCE网络需要专用网卡,但是交换机可以兼容标准以太网交换机,因此可以用于构建公有云和数据中心。
3)iWarp(internetWide Area RDMA Protocol),iWarp将RDMA协议运行在TCP协议上,与RoCE具有类似特性。
目前,RoCE由于支持Internet并且较iWarp协议更加简单,拥有较大的市场和更好的前景。
另外,针对Smart NIC的研究现在也被推上高潮,由于采用了嵌入式的CPU,智能网卡可以进一步降低对Host主机的依赖,因此正在被数据中心广泛采用。

 举报
举报