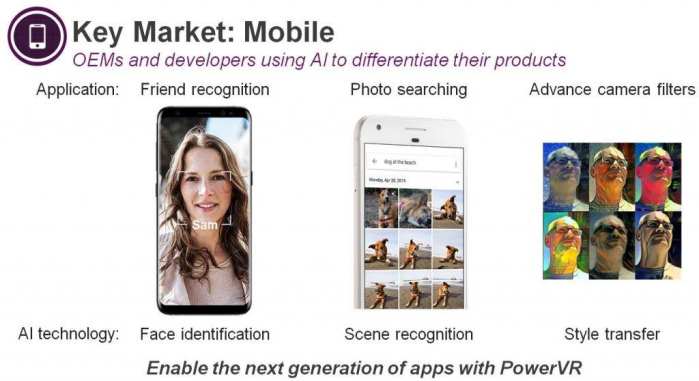
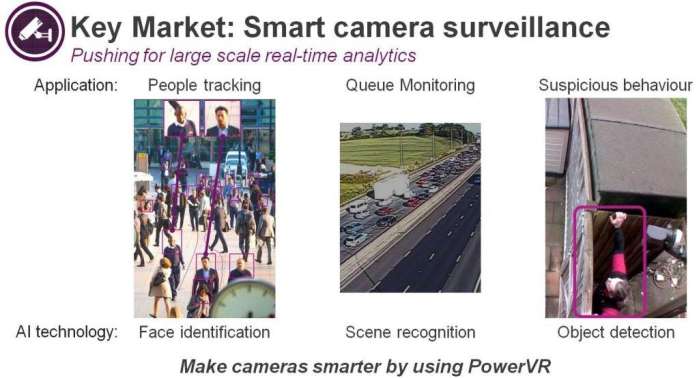
神经网络作为解决问题以及驱动多领域新型应用的工具正变得越来越流行,下图分别说明了在移动设备和智能监控摄像机等领域内快速发展的嵌入式AI应用。
虽然神经网络可以进行离线训练,但是在进行推断处理时——运行神经网络实时识别和处理对象——有必要将这些技术转移到终端设备中,而不是将这些任务放在云端进行处理。举一个例子:无人机,它们的飞行速度可以超过150mph(英里每小时),神经网络可以驱动碰撞检测系统,然而如果没有专门的硬件来进行图像处理,无人机将需要看到前方10-15米的物体才能避开障碍物。由于发送和接收信息所需的延迟和带宽,云服务器并不是合适的解决方案。搭建专用PowerVR NNA的无人机能够以每小时150英里的速度飞行,并且避开1米以内的障碍物,这大大提高了响应能力和安全性,并增强这类应用的创造性。
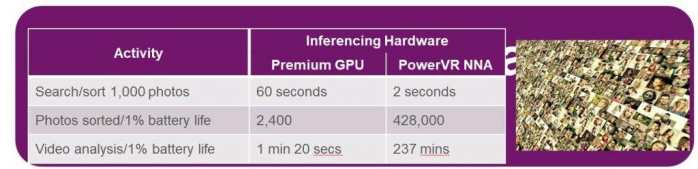
专用神经网络硬件往往被视为SoC集成中的下一步,在20世纪80年代除了早期的桌面CPU之外还集成了数字协同处理器,而且很快就成为了这类设计的标准。虽然很多计算任务已经从CPU转移到GPU上来,但这对于工作来说仍然不是最有效的设计工具,将它们转移到专用的本地硬件才是符合逻辑的解决方案,性能优势是显而易见的,采用高端GPU检索1000张图片需要60秒,但是使用我们的NNA只需要2秒,之前的方案对这些图片进行分类要消耗1%的电量,但是NNA消耗1%的电量可以处理42万8千张图片,这是非常具有说服力的。
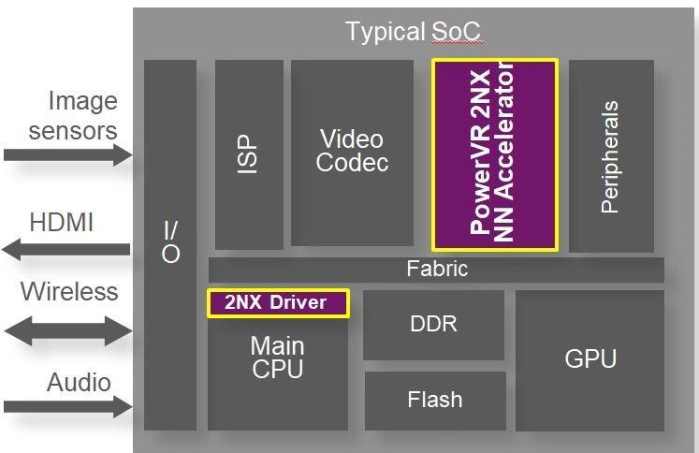
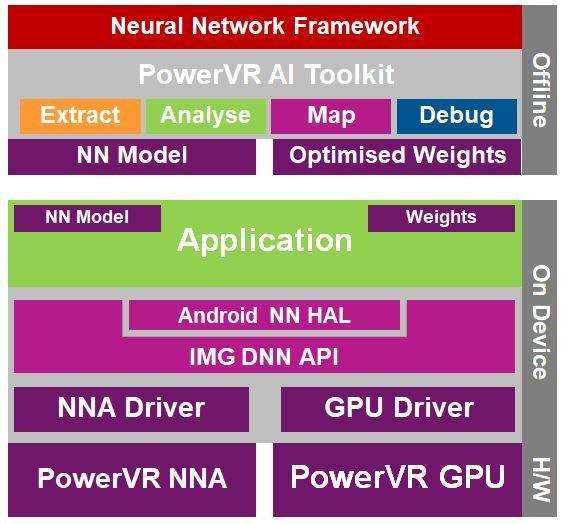
去年9月,Imagination推出的Series2NX加速器是基于神经网络推理而构建的,是目前业界性能最好的解决方案,同时这些加速器还对所有的主要卷积神经网络层提供支持,比如Inception、ResNet,框架包括Tensorflow、Caffe2和PyTorch等。
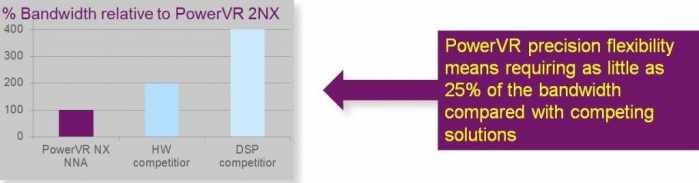
该解决方案一个关键的差异化因素在于它提供了灵活的精度,使用由16位数据组成的经过训练的网络可以达到非常高的准确度,然而使用较低的精度训练网络意味着仍然可以保持较高的精度,而且其优势是可以显著降低功耗和带宽。在实际情况中这使得将NNA集成到智能相机、智能手机等嵌入式设备中可以花费较低的成本同时保持较高的实用性。针对这些已经被验证过的创新,查看Imagination网站上相关博客,可以了解更多关于采用高效推理训练神经网络的处理过程和好处。
下表展示了精度灵活性的好处,简而言之采用4位精度你可以大幅度降低功耗和带宽(内存)需求,精确度仅下降1%,这在大多数实际情况下对于设备的效率没有明显的影响。下面,我们以Imagination的两款神经网络加速器为例,来说明不同市场对性能指标和其他因素的考量:

PowerVR AX2185
Imagination的Series2NX已经在市场上取得了成功并且已经授权给多家厂商,今天它们正在不断扩大市场的选择范围。首先,通过增强原始内核推出了PowerVR AX2185,其次发布另一个版本即PowerVR AX2145。一个关键的新特性是这两款核心都增加了对Android NN API的硬件支持,使得开发人员能够开发更多基于深度学习的应用,大大丰富了安卓市场应用。
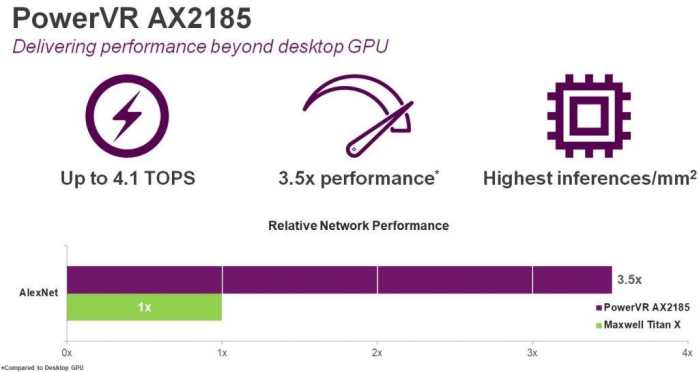
从性能角度来看,PowerVR AX2185面向的是高端嵌入式市场,它集成了8个全位宽计算引擎,能够提供每秒最多可达4.1兆赫的运算,在目前市场上其每平方毫米性能参数是最高的。实际上这个水平是最新的桌面GPU性能的3.5倍。对于那些正在使用功耗较高的GPU进行神经网络训练的公司来说,这是非常具有吸引力的,尤其是汽车领域。与友商提供的硬件解决方案相比,基于4位数据的网络AX2185仅需要50%的带宽,而与基于DSP的竞争厂商的方案相比则降低了75%。
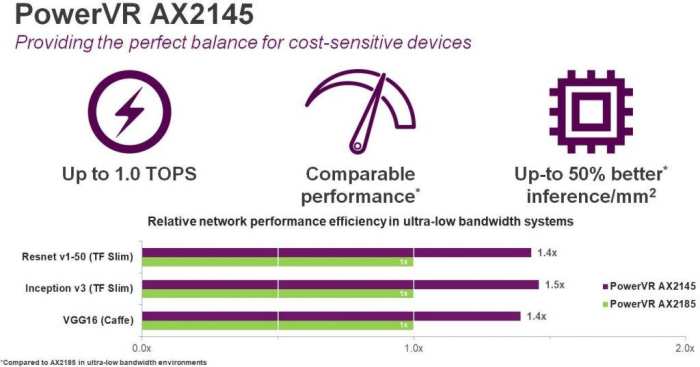
虽然高端设备已经具备了人脸解锁等诸多功能,但是这些功能正在迅速地更新迭代,设备制造商希望以更低的价格提供这些功能,当然消费者也想为他们的手机支付更少的钱但同时还能拥有相同甚至更好的功能,比如智能相机确保家庭安全、智能手机的人脸解锁等。是的,消费者也想分享这个蛋糕。
神经网络作为解决问题以及驱动多领域新型应用的工具正变得越来越流行,下图分别说明了在移动设备和智能监控摄像机等领域内快速发展的嵌入式AI应用。
虽然神经网络可以进行离线训练,但是在进行推断处理时——运行神经网络实时识别和处理对象——有必要将这些技术转移到终端设备中,而不是将这些任务放在云端进行处理。举一个例子:无人机,它们的飞行速度可以超过150mph(英里每小时),神经网络可以驱动碰撞检测系统,然而如果没有专门的硬件来进行图像处理,无人机将需要看到前方10-15米的物体才能避开障碍物。由于发送和接收信息所需的延迟和带宽,云服务器并不是合适的解决方案。搭建专用PowerVR NNA的无人机能够以每小时150英里的速度飞行,并且避开1米以内的障碍物,这大大提高了响应能力和安全性,并增强这类应用的创造性。
专用神经网络硬件往往被视为SoC集成中的下一步,在20世纪80年代除了早期的桌面CPU之外还集成了数字协同处理器,而且很快就成为了这类设计的标准。虽然很多计算任务已经从CPU转移到GPU上来,但这对于工作来说仍然不是最有效的设计工具,将它们转移到专用的本地硬件才是符合逻辑的解决方案,性能优势是显而易见的,采用高端GPU检索1000张图片需要60秒,但是使用我们的NNA只需要2秒,之前的方案对这些图片进行分类要消耗1%的电量,但是NNA消耗1%的电量可以处理42万8千张图片,这是非常具有说服力的。
去年9月,Imagination推出的Series2NX加速器是基于神经网络推理而构建的,是目前业界性能最好的解决方案,同时这些加速器还对所有的主要卷积神经网络层提供支持,比如Inception、ResNet,框架包括Tensorflow、Caffe2和PyTorch等。
该解决方案一个关键的差异化因素在于它提供了灵活的精度,使用由16位数据组成的经过训练的网络可以达到非常高的准确度,然而使用较低的精度训练网络意味着仍然可以保持较高的精度,而且其优势是可以显著降低功耗和带宽。在实际情况中这使得将NNA集成到智能相机、智能手机等嵌入式设备中可以花费较低的成本同时保持较高的实用性。针对这些已经被验证过的创新,查看Imagination网站上相关博客,可以了解更多关于采用高效推理训练神经网络的处理过程和好处。
下表展示了精度灵活性的好处,简而言之采用4位精度你可以大幅度降低功耗和带宽(内存)需求,精确度仅下降1%,这在大多数实际情况下对于设备的效率没有明显的影响。下面,我们以Imagination的两款神经网络加速器为例,来说明不同市场对性能指标和其他因素的考量:
PowerVR AX2185
Imagination的Series2NX已经在市场上取得了成功并且已经授权给多家厂商,今天它们正在不断扩大市场的选择范围。首先,通过增强原始内核推出了PowerVR AX2185,其次发布另一个版本即PowerVR AX2145。一个关键的新特性是这两款核心都增加了对Android NN API的硬件支持,使得开发人员能够开发更多基于深度学习的应用,大大丰富了安卓市场应用。
从性能角度来看,PowerVR AX2185面向的是高端嵌入式市场,它集成了8个全位宽计算引擎,能够提供每秒最多可达4.1兆赫的运算,在目前市场上其每平方毫米性能参数是最高的。实际上这个水平是最新的桌面GPU性能的3.5倍。对于那些正在使用功耗较高的GPU进行神经网络训练的公司来说,这是非常具有吸引力的,尤其是汽车领域。与友商提供的硬件解决方案相比,基于4位数据的网络AX2185仅需要50%的带宽,而与基于DSP的竞争厂商的方案相比则降低了75%。
虽然高端设备已经具备了人脸解锁等诸多功能,但是这些功能正在迅速地更新迭代,设备制造商希望以更低的价格提供这些功能,当然消费者也想为他们的手机支付更少的钱但同时还能拥有相同甚至更好的功能,比如智能相机确保家庭安全、智能手机的人脸解锁等。是的,消费者也想分享这个蛋糕。

 举报
举报