NPU的运行速度有待提高
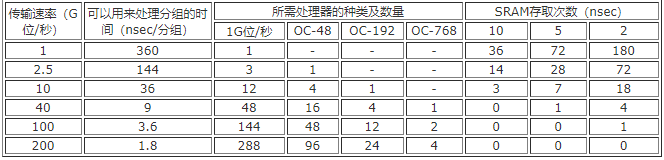
表1给出了在不同的数据传输速率条件下,网络处理器处理一个40字节的分组(的通信分组)所需要的时间。例如,在数据传输速率为1G位/秒时,网络处理器可以有360 ns 的时间来处理此分组。在这段时间内,NPU必须对分组进行检查,语法分析,以及必要的编辑和查表(有时对于分组的内容需要按照不同的策略采取不同的处理措施,有的继续向前传送,有的要送去排队,有的需要作标记;一般说来,对于一个分组可能要进行2到3种数据库的查表处理)。对于即使是比较低的传输速率1G位/秒,网络处理器也只有360 ns 来完成上述作业;如果传输速率为100G位/秒,对于每个分组就只有3.6 ns 的时间来进行处理了。
从目前情况来看,价格适中的SRAM,存取时间为10 nsec,有望提高到5 nsec。如果将一个10 nsec的SRAM用于1G/秒的数据流,在留给处理分组的360 nsec 时间窗口内,只能对存储器进行36次的存取。如果用于10 G位/秒的数据流,存取次数将减少到只能进行3次了;即使是采用5 nsec的SRAM,也只能进行7次存取。
从表1所给出的数据可以看出,为了有效地提高数据处理速率,只能将处理步骤分段,并采用流水线的方式来进行处理,或者采用多个处理机来并行处理(即多个处理机同时对不同分组进行处理)。这种解决办法,对于策略查表存储器,和内容寻址存储器(CAM)都适用。例如,对于40 G位/秒的数据流,采用10 nsec 的存储器,在允许的时间内存取也进行不了。这时,设计人员必须采用许多并行的存储器陈列。
网络处理器可以按照它们对于数据处理的速率来进行分类。在表1的中间部分列出了对于一定的数据速率,需要采用的网络处理器种类和数量。例如,对于2.5 G位/秒的数据流,需要使用3个1G位/秒的处理器来进行处理。而对于100 G位/秒的数据流,则需要144个这样的处理器。对于这样的数据流,也许改为采用12个OC-192处理器,或两个OC-768处理器更合适一些。
表1 对网络处理器处理速率的要求(以每分组40字节为例)
除了实际处理分组需要时间以外,将分组从网络一方转移进来,和将数据转移到交换结构一方去也去要花费时间。表2给出的分摊时间是总时间的25%。以上数字对于MAC接口是很符合实际的假设,但是对于交换结构接口,由于分段(segmentation)的效率一般只有50%,因此在计算时需要留下100%的速度余度,才能跟得上通信线路的速度。
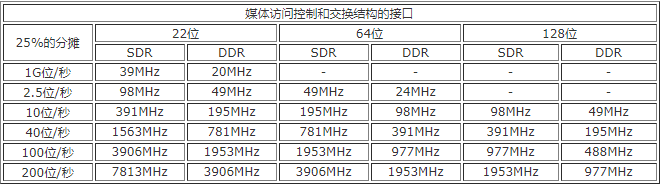
表2 对于网络媒体/交换结构接口的要求
从表2可以看出,对于10G位/秒的传输速率,如果采用32位单数据速率(SDR)总线,则总线必须工作在391MHz。而对于40G位/秒的传输速率,假定采用64位SDR总线,总线必须工作在781MHz。表3总结了对分组缓冲存储器的要求。分组缓冲存储器至少必须具有3倍用通信线路的速度的传输速率(300%的速度余度)。表3中分门别类地给出了这一要求。例如,对于10G位/秒的传输速率,如果采用的是64位的双倍数据速率(DDR)缓冲存储器,则需要工作在313MHz以上的频率。
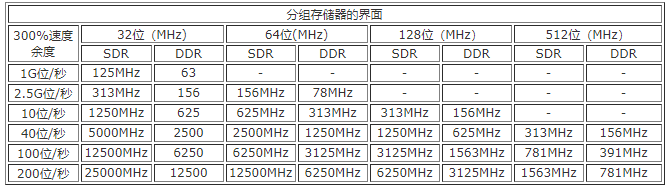
表3 对分组缓冲存储器的要求
NPU的运行速度有待提高
表1给出了在不同的数据传输速率条件下,网络处理器处理一个40字节的分组(的通信分组)所需要的时间。例如,在数据传输速率为1G位/秒时,网络处理器可以有360 ns 的时间来处理此分组。在这段时间内,NPU必须对分组进行检查,语法分析,以及必要的编辑和查表(有时对于分组的内容需要按照不同的策略采取不同的处理措施,有的继续向前传送,有的要送去排队,有的需要作标记;一般说来,对于一个分组可能要进行2到3种数据库的查表处理)。对于即使是比较低的传输速率1G位/秒,网络处理器也只有360 ns 来完成上述作业;如果传输速率为100G位/秒,对于每个分组就只有3.6 ns 的时间来进行处理了。
从目前情况来看,价格适中的SRAM,存取时间为10 nsec,有望提高到5 nsec。如果将一个10 nsec的SRAM用于1G/秒的数据流,在留给处理分组的360 nsec 时间窗口内,只能对存储器进行36次的存取。如果用于10 G位/秒的数据流,存取次数将减少到只能进行3次了;即使是采用5 nsec的SRAM,也只能进行7次存取。
从表1所给出的数据可以看出,为了有效地提高数据处理速率,只能将处理步骤分段,并采用流水线的方式来进行处理,或者采用多个处理机来并行处理(即多个处理机同时对不同分组进行处理)。这种解决办法,对于策略查表存储器,和内容寻址存储器(CAM)都适用。例如,对于40 G位/秒的数据流,采用10 nsec 的存储器,在允许的时间内存取也进行不了。这时,设计人员必须采用许多并行的存储器陈列。
网络处理器可以按照它们对于数据处理的速率来进行分类。在表1的中间部分列出了对于一定的数据速率,需要采用的网络处理器种类和数量。例如,对于2.5 G位/秒的数据流,需要使用3个1G位/秒的处理器来进行处理。而对于100 G位/秒的数据流,则需要144个这样的处理器。对于这样的数据流,也许改为采用12个OC-192处理器,或两个OC-768处理器更合适一些。
表1 对网络处理器处理速率的要求(以每分组40字节为例)
除了实际处理分组需要时间以外,将分组从网络一方转移进来,和将数据转移到交换结构一方去也去要花费时间。表2给出的分摊时间是总时间的25%。以上数字对于MAC接口是很符合实际的假设,但是对于交换结构接口,由于分段(segmentation)的效率一般只有50%,因此在计算时需要留下100%的速度余度,才能跟得上通信线路的速度。
表2 对于网络媒体/交换结构接口的要求
从表2可以看出,对于10G位/秒的传输速率,如果采用32位单数据速率(SDR)总线,则总线必须工作在391MHz。而对于40G位/秒的传输速率,假定采用64位SDR总线,总线必须工作在781MHz。表3总结了对分组缓冲存储器的要求。分组缓冲存储器至少必须具有3倍用通信线路的速度的传输速率(300%的速度余度)。表3中分门别类地给出了这一要求。例如,对于10G位/秒的传输速率,如果采用的是64位的双倍数据速率(DDR)缓冲存储器,则需要工作在313MHz以上的频率。
表3 对分组缓冲存储器的要求

 举报
举报




