作者:SFXiang
首发:AI算法修炼营

本文是一种端到端的先分割后分类的表面缺陷检测方法。主要的创新点在于如何将两类任务更好地进行同步学习,本文首先平衡分割损失和分类损失,然后对负样本的采样方法进行了改进,能够适应于小样本、弱标注等场景。
论文地址:https://arxiv.org/pdf/2007.07...
基于分割的两阶段神经网络在表面缺陷检测中显示出优异的结果,使该网络能够从相对较少的样本中学习。在这项工作中,本文介绍了一种端到端训练的两阶段网络用于缺陷检测,并对训练过程进行了一些扩展,从而减少了训练时间,同时对表面缺陷检测任务的结果进行改进。为了实现端到端训练,本文在学习过程中
仔细平衡了分割损失和分类损失的贡献。同时,调整了从分类到分割网络的梯度流,以防止不稳定的特征破坏学习。作为对学习的进一步扩展,本文提出了
负样本的使用频率采样方案,以解决训练期间图像过采样和欠采样的问题,同时在基于区域的分割mask的距离变换算法上采用正像素权重,因此在不需要详细标注的情况下,对存在缺陷可能性较高的区域给予了更高的重视。最后,在三个缺陷检测数据集DAGM,KolektorSDD和SeverstalSteel缺陷数据集上测试了本文方案的性能和所提出的扩展策略,实现了最新的结果。在DAGM和KolektorSDD上达到了100%的检测率。并且在三个数据集上进行的附加消融实验定量地证明了所提出的扩展对总体结果改进的贡献。
简介一种新颖的两阶段体系结构已被证明在表面缺陷检测中非常成功。具体来说,是在第一阶段进行缺陷分割,然后在第二阶段对有缺陷与无缺陷的表面按图像分类。但是,现有的两阶段体系结构依赖于繁琐的训练过程,因为它们
需要首先训练分割层,然后冻结分割层,然后再学习分类层。尽管这种两阶段学习方法产生了最新的结果,但由于需要多次学习,因此它也会导致学习过程缓慢。
在本文工作中,解决了用于表面缺陷检测的两阶段体系结构的缺点,并提出了一种端到端的训练方案,该方案
只需要精度不高的像素级标注而且不会影响性能。该方法通过以端到端的方式同时引入分割和分类层的学习来改善学习过程,因此所提出的体系结构不仅使网络的学习更加容易和快速,而且还提高了缺陷检测率。同时,还提出了一种
考虑像素级标注的梯度流调整策略,并没有像图像处理那样仅在图像级别的标签上使用弱监督学习,梯度流的策略反而扩展了损失函数,可用来解决基于区域的标注的不确定性,这使得粗略的标注仍然相当容易获得。此外,还引入了无缺陷样本的使用频率采样方法,这进一步提高了缺陷检测性能。
本文的方法:END-TO-END LEARNING FOR TWO-STAGEARCHITECTURE 1、End-to-end learning
1、End-to-end learning
为了实现端到端的学习,将损失(分割损失和分类损失)合并为一个统一的损失,以实现同步学习。新的合并损失定义为:
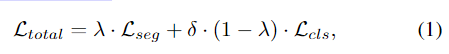
其中Lseg和Lcls分别代表分割损失和分类损失,δ是防止分类损失占主导的额外分类损失权重,而λ是平衡每个网络在最终损失中的贡献的混合因子。注意,λ和δ不会代替SGD中的学习率η,而是对其进行补充。由于损失程度不一,因此它们可以充分控制学习过程。分割损失是在所有像素上平均的,由于只有少数像素是异常的,与分类损失相比,其值相对较小,因此通常
使用较小的δ值来防止分类损失占总损失的主导。
同时学习的另一个挑战是在分割网络的特征稳定之前学习分类网络。为了解决这个问题,本文建议从一开始就只学习分割网络,然后逐渐向最后只学习分类的趋势发展。通过
将分割和分类混合因子计算为简单的线性函数来表示,公式为:
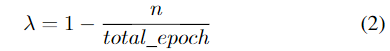
其中,n代表当前训练周期epoch的索引,total_epoch代表训练周期的总数。如果没有两种损失的逐渐混合,在某些情况下学习将导致爆炸梯度,从而使模型更难以使用。
将逐步包括分类网络和排除分段网络的过程称为动态平衡损失。此外,使用
较低的δ值可进一步减少早期就学习嘈杂的分割特征的问题,而使用较大的值有时会导致梯度爆炸的问题。
Gradient-flow adjustments 梯度流调整策略
本文建议
消除从分类网络到分割网络过程中产生的梯度流,这对于分别以端对端的方式学习分割和分类层是必需的。 首先,通过在分类网络使用的最大/平均池化shortcut方法来消除梯度流。在图1中,它用(a)标记。这些shortcut方式利用分割网络的输出映射来加快分类学习的速度。反传播梯度会在分割网络的输出映射中添加误差梯度,但这可能是有害的,因为该输出已经存在像素级标注形式的误差。
同时,本文还建议限制源自于分类网络的分割梯度。在图1中,用(b)标记。在训练的初始阶段,分割网络尚未产生有意义的输出,因此从分类网络反向传播的梯度会对分割部分产生负面影响,因此可以完全停止这些梯度,从而防止分类网络更改分割网络。训练过程首先对分割网络进行训练,然后冻结分割层,最后仅对分类网络进行训练。
2、 Frequency-of-use sampling
当前,先分割再分类的两阶段体系结构通常采用交替采样方案实现,该方案在每个训练步骤中通过正样本和负样本之间交替采样来平衡正负样本。而本文通过
基于每个负样本的使用频率替换一次随机抽样来改进交替采样方案。现有的交替采样方案会在相同数量的正样本图像中为每个训练周期强制选择负样本图像,然而,由于正样本数量远远小于负样本,所以选择出的样本将相对较小。同时,对每个训练周期均对负样本图像进行均匀随机采样,因此会导致某些样本的过度使用和其他样本的使用不足,如图2左侧所示。

而本文
根据使用频率将负样本的随机抽样替换为一个样本抽样。以与该图像的
使用频率成反比的概率对每个图像进行采样。如图2的直方图所示,使用频率采样可同时减少样本过度使用和使用不足等问题,并确保在训练过程中均匀使用每个负样本。
3、Loss weighting for positive pixels
当只有近似的,基于区域的标签可用时(如图3所示),本文的方法
以不同的方式考虑带标注的缺陷区域的不同像素,特别是,将更多的注意力放在带标注的区域的中心,而不是外部。这减轻了在缺陷边缘产生的歧义,在该边缘通常无法确定缺陷是否存在。因此,通过相应地加权分割损失来实现标签不同部分中的重要性。具体地,
使用距离变换算法加权每个像素在正标签处的影响,而不取决于其与最近的负标签像素的距离。
将正像素的权重表示为:
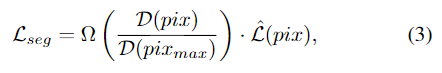
其中,
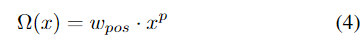
 实验与结果数据集: DAGM 2007
实验与结果数据集: DAGM 2007 (《Design of deep convo-lutional neural network architectures for automated feature extractionin industrial inspection》)、
KolektorSDD(《Segmentation-based deep-learning approach for surface-defect detection》)、
Steel Defect(《Severstal: Steel Defect Detection on Kaggle Challenge》)
评价指标:AP平均精度
实验结果
1、DAGM 2007数据集上的结果


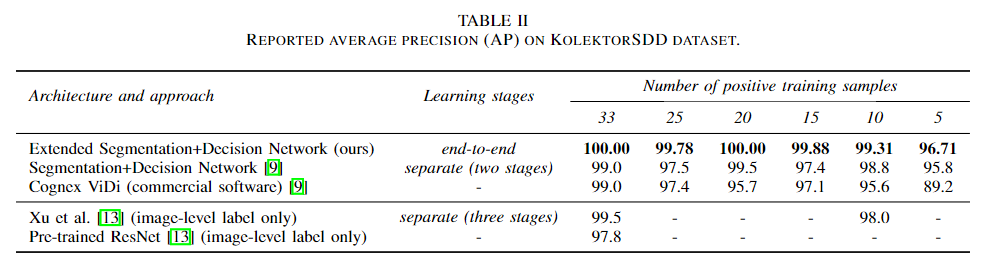
2、 The KolektorSDD数据集上结果
本文的方法在所有情况下均优于baseline,如表II所示。
当使用所有正训练样本时,该方法均达到了100%的AP,没有错误分类。所提出的方法还优于其他所有相关方法,包括使用更精确标注进行训练的以及在较弱的监督下进行训练的两阶段体系结构。
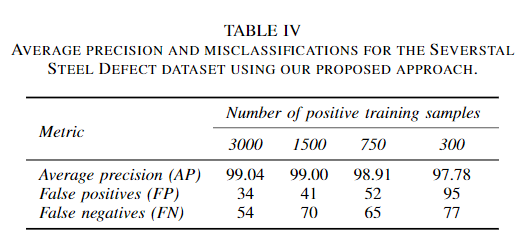
3、The Severstal Steel defect数据集上的结果
前两个数据集的结果显示令人满意,因为这两个数据集都包含太多示例,这对于深度学习方法来说是困难的。因此,我们还对The Severstal Steel defect数据集进行了评估,该数据集包含一组更大的更困难的样本。该数据集总共包含12,568张图像,具有4种不同类型的缺陷。图4中显示了来自数据集的少量图像,以及来自分割网络的检测结果和检测结果。

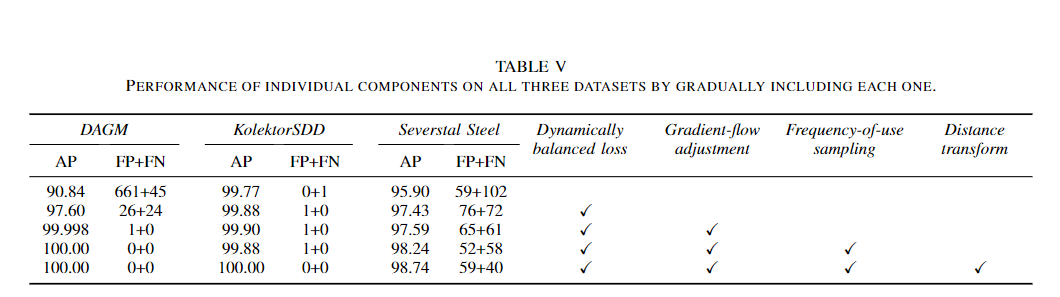
 消融实验
消融实验
 推荐阅读
推荐阅读
- 推荐!私藏的深度学习模型推理加速项目
- 表面缺陷检测数据集汇总及其相关项目推荐
- 目标检测 | 已开源!全新水下目标检测算法SWIPENet+IMA框架
- CVPR2020 | 对数字屏幕拍照时的摩尔纹怎么去除?
- PolyLaneNet:最新车道线检测开源算法,多项式回归实时高效
- 停车位检测新数据集、新方法,精准又快速(含视频解读)


