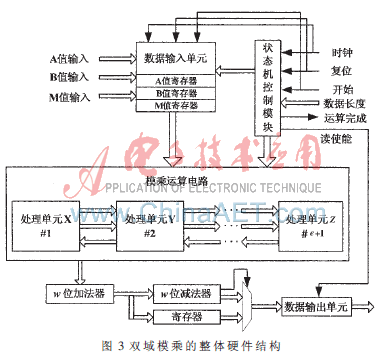
随着计算机网络的发展和普及,信息安全问题越来越多地被人们所关注。公钥密码体制有效地解决了在公共信道上保护信息的抗抵赖性、身份认证、密钥分发等问题。椭圆曲线密码ECC(Ellip
tic Curve Cryptography)是一种基于椭圆曲线离散对数问题的公钥密码,1985年分别由Miller [1]和Koblitz[2]独立提出。相对于其他公钥密码系统,椭圆曲线密码系统具有计算速度快、存储空间小、带宽要求低等优点,特别适用于各种无线设备和智能卡等计算资源受限的设备,因而受到了人们的广泛关注,成为新一代公钥密码标准。而模乘运算是椭圆曲线加密算法中的核心运算,如何高效地实现模乘运算是当前的一个研究热点。




 举报
举报