传感器开发平台
登录
直播中
刘易
7年用户
137经验值
私信
关注
网络核心设备的系统架构怎么构建?
开启该帖子的消息推送
网络驱动
中断
内存
处理器
互联网已成为人们低成本高效率获取信息的平台,随着各站点访问量和信息交流量的迅猛增长,网络接入边缘的瓶颈阻塞日益严重。因此,必须提高网络中核心设备的性能,以满足网络流量日益增长的需要。常见的
通信
网由
电路
交换系统和基于分组的交换系统构成,整个网络由一系列小网络、传输和终端设备组成,网络间互通性差、可管理性不强,网络业务不灵活。随着
电子
商务、多媒体业务和VoIP等对带宽的要求较高的业务的出现,设计并实现高性能的网络设备更加重要。
回帖
(2)
陈迪
2019-10-23 15:35:26
1 引言
互联网已成为人们低成本高效率获取信息的平台,随着各站点访问量和信息交流量的迅猛增长,网络接入边缘的瓶颈阻塞日益严重。因此,必须提高网络中核心设备的性能,以满足网络流量日益增长的需要。常见的通信网由电路交换系统和基于分组的交换系统构成,整个网络由一系列小网络、传输和终端设备组成,网络间互通性差、可管理性不强,网络业务不灵活。随着电子商务、多媒体业务和VoIP等对带宽的要求较高的业务的出现,设计并实现高性能的网络设备更加重要。为了满足越来越多的网络业务对网络带宽的需求,有研究机构和企业提出采用X86+FPGA/ASIC的系统架构,这种架构带有明显的数据平面和控制平面相分离的特征,因此能够实现高性能目标。但由于FPGA或ASIC技术需要很大的研发投入,且进行功能扩展的性能较差,产品更新换代的速度很慢。因此,这里提出在网络设备中应用多核多线程处理器,继续分离数据平面和控制平面,满足用户对网络业务丰富和性能增长同步发展的需求。
2 框架设计及实现
RMI公司的XLR系列是基于RMI增强型MIPS64内核,可同时支持32个线程的独特构架的处理器,工作频率达1.5 GHz,同时支持高度集成的独立硬件安全引擎和网络应用加速器。XLR系列处理器采用多核多线程技术,具有很高的数据处理能力,可以在复杂的网络环境中承担网络设备高速转发任务。为了平衡高速的数据转发和复杂的业务处理之间的矛盾,本系统在XLR系列器件的32个线程上运行Linux和VxWorks两种操作系统,并使用VxWorks完成高速的数据转发,使用Linux进行复杂的业务处理。
如果Linux和VxWorks两种操作系统运行在不同的CORE上,则两种操作系统不会竞争中断和BUCKET等硬件资源,但却对业务部署带来很大麻烦,导致业务的划分粒度也很粗犷。因此,本文提出Linux和VxWorks共CORE,通过共享内存区快速通信的方案,细化业务划分粒度,并优化XLR器件驱动程序框架,充分发挥软硬件资源优势,提升网络核心设备性能。
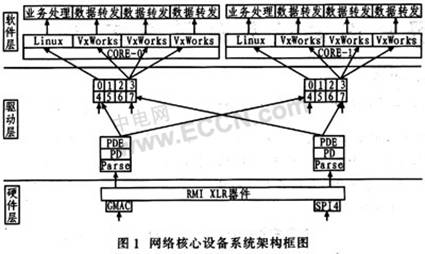
从硬件配置、网络驱动、软件结构3个层次构建网络中核心设备框架,其中硬件配置用于配置XLR器件硬件资源分布,包括每个CORE相应站内的桶的深度以及GMAC/SPl4与CORE通过FMN总线通信所需的credits,以支持上层业务需要;网络驱动的主要作用是屏蔽操作系统对底层硬件资源的竞争,正确区分控制业务报文和转发数据报文,每个网口的网络加速引擎将报文地址和长度信息封装成FMN消息并提交给相应模块进行处理;软件层的主要作用是更好地利用不同操作系统的优点,分离控制平面和数据平面,实现两种操作系统间的通信,以实现复杂的业务控制和高速的数据转发。图1为该网络核心设备系统架构。
2.1硬件配置
XLR系列处理器通过快速消息网络FMN(Fast MessageNetwork)将系统的CPU CORE、报文处理单元PDE、加密单元Cypto引擎、多处理器互联的HT接口(HyperTransport)、PCI-X等互联。默认情况下,FMN总线上每个站内包含8个桶,每个桶的深度为32。每个桶都有其固定的ID,系统中共有128个桶,其中CORE使用前64个桶(0~63号桶)。
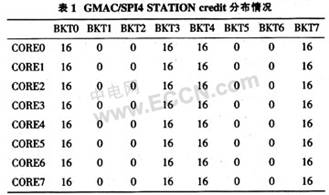
为了区分控制报文信息和数据报文信息,并结合网络驱动程序将报文送至正确目的地,使能每个CORE内的0,3,4,7号桶,禁用1,2,5,6号桶。每个桶内含有64个entry。其中0号桶用于存放目的地是Linux的数据报文,而3号桶用于存放目的地是VxWorks的数据报文。4号桶用于存放Linux操作系统发送消息后产生的freeback消息,7号桶用于存放VxWorks操作系统发送消息后产生的freeback消息。为了实现GMAC/SP14和CORE能够通过FMN总线通信,必须在每个站维护一定的credits数,表1列出系统credits分布情况。
2.2 网络驱动
根据不同的网络环境,可设计不同的网络驱动类型。如果网络环境中流量较小,使用网络处理器中的一个或几个硬件线程即可满足网络带宽要求,则可设计集中式网络驱动程序。在集中式网络驱动程序中,一个或少数几个VCPU作为数据转发的代理,大部分数据报文由这组代理VCPU接收、处理并转发;如果这组代理VCPU收到控制报文,则判断报文目的地,并通过IPI中断将控制报文转发给相应VCPU处理。这种驱动程序设计彻底分离数据平面和控制平面,但其缺点是代理VCPU的压力很大,如果网络流量变大,则很可能因为数据报文拥塞而导致代理VCPU瘫痪,这时整个系统就必须重启。为了能够适应更大的网络流量,这里设计分布式网络驱动。分布式网络驱动中,所有VCPU都会接收数据报文和控制报文,并进行相应的处理和转发。分布式网络驱动程序的优点是所有VCPU平均分担网络流量,不会因为某几个VCPU瘫痪而导致系统重启。而分布式驱动程序使数据平面和控制平面的隔离不够彻底,一定程度上影响数据转发性能。
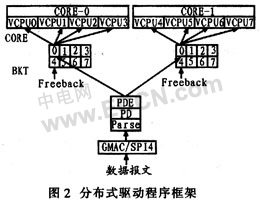
这里的应用场景为网络中的核心设备,因此网络流量非常大,可以采用分布式驱动程序设计。GMAC或SPI4接口收到数据后,数据通过NA的DMA直接存入内存区,而NA将收到报文的信息封装成FMN消息格式送到CORE0的0号桶。在分布式驱动程序设计中,所有VCPU都要相应中断,中断掩码为0xffffffff。每个站内的桶接收到消息会随机发送中断信号到4个VCPU中的一个,收到中断信号的VCPU响应中断到桶内收消息,收到消息后,判断消息是否需其本身处理,如果无需自己处理,就发送IPI中断到目的VCPU,通知目的VCPU处理该消息。图2为分布式驱动程序框架。
由于每个硬件线程都运行独立的操作系统,而且由于操作系统的差异性,操作系统会竞争资源,因此必须提出一种方案,使资源竞争对Linux和VxWorks操作系统透明。因为中断信号的响应单位是CORE,并且CORE内4个硬件线程响应此中断是随机的,所以硬件线程对中断的竞争是不可避免的。为此,提出通过下列方案实现消息发送到指定的目的地,也即保证Linux不会取走目的地是VxWorks的数据报文。
方案如下:①用某个GMAC网口接收控制消息,用其余GMAC和SP14接口处理数据报文;②每个CORE内8个桶,使能4个,禁用4个。分别使能0号桶,3号桶,4号桶,7号桶,禁用1,2,5,6号桶。每个桶内含有64个entry。其中0号桶用于存放目的地是Linux的数据报文,而3号桶用于存放目的地是VxWorks的数据报文。4号桶用于存放Linux操作系统发送消息后产生的freeback消息,7号桶用于存放VxWorks操作系统发送消息后产生的freeback消息;配置GMAC口NA中的pdeclass寄存器,将所有报文发送到CORE内的0号桶。配置其余GMAC口和SPI4接口NA的pdeclass寄存器,将所有报文发送到CORE内的3号桶。分别修改GMAC和SPl4发送函数,将FREEBACK消息目的地设定为CORE内的4号桶和7号桶。该方案通过优化数据接收流程,使资源的竞争对操作系统透明,每个操作系统以为自己独享全部资源。
由于本文的应用环境网络流量很大,其中数据流量占到90%左右,而控制信息只占约10%,所以在第1个CORE上,系统在VCPUO上运行Linux操作系统,负责处理控制消息;而其余3个VCPU运行VxWorks,负责数据报文的转发。
2.3 软件结构
网络核心设备系统架构软件层完成操作系统部署方案。XLR系列器件有8个CORE,每个CORE内有4个硬件线程,4个硬件线程共享一级高速缓存、桶、中断等资源。如果以CORE为单位部署操作系统,那么CORE内4个硬件线程是SMP结构,不会竞争上述资源。但按CORE部署操作系统是一种粗粒度的划分,是资源利用和系统性能的瓶颈。所以本文提出操作系统的部署以VCPU为单位,同一个CORE内既可有Linux也可有VxWorks。
Linux和VxWorks的优缺点比较:Linux的优点有,模块化设计,可划分细粒度业务;无版权,免费获取;功能丰富,可扩展性强;用户进程地址空间独立;网络资源丰富;系统稳定性很高。其缺点为自旋锁等机制导致实时性下降;可能导致中断丢失;Linux系统管理复杂,培训需要较长时间。而Vx-Works的优点有:实时性好;内存碎片少;系统简单,调试容易,有Tomado开发环境;商用操作实时系统,提供的资源非常适合嵌入式应用:BSP开发非常规范。其缺点为内核保留的信息很少,导致很难开发复杂业务流程;网络资源很少,技术支持只有WindRiver;系统稳定性取决于开发者能力;内核采用实存储管理方式。
为了更好的结合Linux和VxWorks两种操作系统的优点,这里使用Linux操作系统控制平面的业务处理,使用Vx-Works负责数据平面的转发任务。
除了资源竞争带来的问题外,还必须实现两种操作系统之间的通信。由于两种操作系统存在差异性,使两者之间的交互不能通过简单进程间通信方式FIFO,PIPE等实现。为了解决两者间的通信问题,本文提出通过共享内存实现两种操作系统之间通信的方案。首先,Linux和VxWorks将需要交互的数据放人共享内存区,然后发送IPI中断到目标操作系统,通知目标操作系统去共享内存区取数据并进行处理。实现步骤:①VxWorks通过TLB映射共享内存区到虚拟地址。共享内存区经TLB映射后,VxWorks操作系统就可读写该区域。②Linux修改link脚本,在进程运行前预留共享内存区。③注册一个字符设备,用于管理共享内存区。修改该设备的mmap函数,该mmap函数实现共享内存区物理地址到虚拟地址的映射。④如果Linux用户态进程运行,首先打开该字符设备,调用mmap函数映射共享内存区。这样该用户态进程就可以操作该共享内存区。⑤如果Linux内核态进程运行,调用iormap调用映射共享内存区物理地址到虚拟地址,这样内核态进程就可以操作该共享内存。通过以上5个步骤,建立Linux和VxWorks两种操作系统之间的共享内存区。
1 引言
互联网已成为人们低成本高效率获取信息的平台,随着各站点访问量和信息交流量的迅猛增长,网络接入边缘的瓶颈阻塞日益严重。因此,必须提高网络中核心设备的性能,以满足网络流量日益增长的需要。常见的通信网由电路交换系统和基于分组的交换系统构成,整个网络由一系列小网络、传输和终端设备组成,网络间互通性差、可管理性不强,网络业务不灵活。随着电子商务、多媒体业务和VoIP等对带宽的要求较高的业务的出现,设计并实现高性能的网络设备更加重要。为了满足越来越多的网络业务对网络带宽的需求,有研究机构和企业提出采用X86+FPGA/ASIC的系统架构,这种架构带有明显的数据平面和控制平面相分离的特征,因此能够实现高性能目标。但由于FPGA或ASIC技术需要很大的研发投入,且进行功能扩展的性能较差,产品更新换代的速度很慢。因此,这里提出在网络设备中应用多核多线程处理器,继续分离数据平面和控制平面,满足用户对网络业务丰富和性能增长同步发展的需求。
2 框架设计及实现
RMI公司的XLR系列是基于RMI增强型MIPS64内核,可同时支持32个线程的独特构架的处理器,工作频率达1.5 GHz,同时支持高度集成的独立硬件安全引擎和网络应用加速器。XLR系列处理器采用多核多线程技术,具有很高的数据处理能力,可以在复杂的网络环境中承担网络设备高速转发任务。为了平衡高速的数据转发和复杂的业务处理之间的矛盾,本系统在XLR系列器件的32个线程上运行Linux和VxWorks两种操作系统,并使用VxWorks完成高速的数据转发,使用Linux进行复杂的业务处理。
如果Linux和VxWorks两种操作系统运行在不同的CORE上,则两种操作系统不会竞争中断和BUCKET等硬件资源,但却对业务部署带来很大麻烦,导致业务的划分粒度也很粗犷。因此,本文提出Linux和VxWorks共CORE,通过共享内存区快速通信的方案,细化业务划分粒度,并优化XLR器件驱动程序框架,充分发挥软硬件资源优势,提升网络核心设备性能。
从硬件配置、网络驱动、软件结构3个层次构建网络中核心设备框架,其中硬件配置用于配置XLR器件硬件资源分布,包括每个CORE相应站内的桶的深度以及GMAC/SPl4与CORE通过FMN总线通信所需的credits,以支持上层业务需要;网络驱动的主要作用是屏蔽操作系统对底层硬件资源的竞争,正确区分控制业务报文和转发数据报文,每个网口的网络加速引擎将报文地址和长度信息封装成FMN消息并提交给相应模块进行处理;软件层的主要作用是更好地利用不同操作系统的优点,分离控制平面和数据平面,实现两种操作系统间的通信,以实现复杂的业务控制和高速的数据转发。图1为该网络核心设备系统架构。
2.1硬件配置
XLR系列处理器通过快速消息网络FMN(Fast MessageNetwork)将系统的CPU CORE、报文处理单元PDE、加密单元Cypto引擎、多处理器互联的HT接口(HyperTransport)、PCI-X等互联。默认情况下,FMN总线上每个站内包含8个桶,每个桶的深度为32。每个桶都有其固定的ID,系统中共有128个桶,其中CORE使用前64个桶(0~63号桶)。
为了区分控制报文信息和数据报文信息,并结合网络驱动程序将报文送至正确目的地,使能每个CORE内的0,3,4,7号桶,禁用1,2,5,6号桶。每个桶内含有64个entry。其中0号桶用于存放目的地是Linux的数据报文,而3号桶用于存放目的地是VxWorks的数据报文。4号桶用于存放Linux操作系统发送消息后产生的freeback消息,7号桶用于存放VxWorks操作系统发送消息后产生的freeback消息。为了实现GMAC/SP14和CORE能够通过FMN总线通信,必须在每个站维护一定的credits数,表1列出系统credits分布情况。
2.2 网络驱动
根据不同的网络环境,可设计不同的网络驱动类型。如果网络环境中流量较小,使用网络处理器中的一个或几个硬件线程即可满足网络带宽要求,则可设计集中式网络驱动程序。在集中式网络驱动程序中,一个或少数几个VCPU作为数据转发的代理,大部分数据报文由这组代理VCPU接收、处理并转发;如果这组代理VCPU收到控制报文,则判断报文目的地,并通过IPI中断将控制报文转发给相应VCPU处理。这种驱动程序设计彻底分离数据平面和控制平面,但其缺点是代理VCPU的压力很大,如果网络流量变大,则很可能因为数据报文拥塞而导致代理VCPU瘫痪,这时整个系统就必须重启。为了能够适应更大的网络流量,这里设计分布式网络驱动。分布式网络驱动中,所有VCPU都会接收数据报文和控制报文,并进行相应的处理和转发。分布式网络驱动程序的优点是所有VCPU平均分担网络流量,不会因为某几个VCPU瘫痪而导致系统重启。而分布式驱动程序使数据平面和控制平面的隔离不够彻底,一定程度上影响数据转发性能。
这里的应用场景为网络中的核心设备,因此网络流量非常大,可以采用分布式驱动程序设计。GMAC或SPI4接口收到数据后,数据通过NA的DMA直接存入内存区,而NA将收到报文的信息封装成FMN消息格式送到CORE0的0号桶。在分布式驱动程序设计中,所有VCPU都要相应中断,中断掩码为0xffffffff。每个站内的桶接收到消息会随机发送中断信号到4个VCPU中的一个,收到中断信号的VCPU响应中断到桶内收消息,收到消息后,判断消息是否需其本身处理,如果无需自己处理,就发送IPI中断到目的VCPU,通知目的VCPU处理该消息。图2为分布式驱动程序框架。
由于每个硬件线程都运行独立的操作系统,而且由于操作系统的差异性,操作系统会竞争资源,因此必须提出一种方案,使资源竞争对Linux和VxWorks操作系统透明。因为中断信号的响应单位是CORE,并且CORE内4个硬件线程响应此中断是随机的,所以硬件线程对中断的竞争是不可避免的。为此,提出通过下列方案实现消息发送到指定的目的地,也即保证Linux不会取走目的地是VxWorks的数据报文。
方案如下:①用某个GMAC网口接收控制消息,用其余GMAC和SP14接口处理数据报文;②每个CORE内8个桶,使能4个,禁用4个。分别使能0号桶,3号桶,4号桶,7号桶,禁用1,2,5,6号桶。每个桶内含有64个entry。其中0号桶用于存放目的地是Linux的数据报文,而3号桶用于存放目的地是VxWorks的数据报文。4号桶用于存放Linux操作系统发送消息后产生的freeback消息,7号桶用于存放VxWorks操作系统发送消息后产生的freeback消息;配置GMAC口NA中的pdeclass寄存器,将所有报文发送到CORE内的0号桶。配置其余GMAC口和SPI4接口NA的pdeclass寄存器,将所有报文发送到CORE内的3号桶。分别修改GMAC和SPl4发送函数,将FREEBACK消息目的地设定为CORE内的4号桶和7号桶。该方案通过优化数据接收流程,使资源的竞争对操作系统透明,每个操作系统以为自己独享全部资源。
由于本文的应用环境网络流量很大,其中数据流量占到90%左右,而控制信息只占约10%,所以在第1个CORE上,系统在VCPUO上运行Linux操作系统,负责处理控制消息;而其余3个VCPU运行VxWorks,负责数据报文的转发。
2.3 软件结构
网络核心设备系统架构软件层完成操作系统部署方案。XLR系列器件有8个CORE,每个CORE内有4个硬件线程,4个硬件线程共享一级高速缓存、桶、中断等资源。如果以CORE为单位部署操作系统,那么CORE内4个硬件线程是SMP结构,不会竞争上述资源。但按CORE部署操作系统是一种粗粒度的划分,是资源利用和系统性能的瓶颈。所以本文提出操作系统的部署以VCPU为单位,同一个CORE内既可有Linux也可有VxWorks。
Linux和VxWorks的优缺点比较:Linux的优点有,模块化设计,可划分细粒度业务;无版权,免费获取;功能丰富,可扩展性强;用户进程地址空间独立;网络资源丰富;系统稳定性很高。其缺点为自旋锁等机制导致实时性下降;可能导致中断丢失;Linux系统管理复杂,培训需要较长时间。而Vx-Works的优点有:实时性好;内存碎片少;系统简单,调试容易,有Tomado开发环境;商用操作实时系统,提供的资源非常适合嵌入式应用:BSP开发非常规范。其缺点为内核保留的信息很少,导致很难开发复杂业务流程;网络资源很少,技术支持只有WindRiver;系统稳定性取决于开发者能力;内核采用实存储管理方式。
为了更好的结合Linux和VxWorks两种操作系统的优点,这里使用Linux操作系统控制平面的业务处理,使用Vx-Works负责数据平面的转发任务。
除了资源竞争带来的问题外,还必须实现两种操作系统之间的通信。由于两种操作系统存在差异性,使两者之间的交互不能通过简单进程间通信方式FIFO,PIPE等实现。为了解决两者间的通信问题,本文提出通过共享内存实现两种操作系统之间通信的方案。首先,Linux和VxWorks将需要交互的数据放人共享内存区,然后发送IPI中断到目标操作系统,通知目标操作系统去共享内存区取数据并进行处理。实现步骤:①VxWorks通过TLB映射共享内存区到虚拟地址。共享内存区经TLB映射后,VxWorks操作系统就可读写该区域。②Linux修改link脚本,在进程运行前预留共享内存区。③注册一个字符设备,用于管理共享内存区。修改该设备的mmap函数,该mmap函数实现共享内存区物理地址到虚拟地址的映射。④如果Linux用户态进程运行,首先打开该字符设备,调用mmap函数映射共享内存区。这样该用户态进程就可以操作该共享内存区。⑤如果Linux内核态进程运行,调用iormap调用映射共享内存区物理地址到虚拟地址,这样内核态进程就可以操作该共享内存。通过以上5个步骤,建立Linux和VxWorks两种操作系统之间的共享内存区。
举报
王海燕
2019-10-23 15:35:35
3 性能分析
这里性能测试的目的是测试目标网络设备的网络吞吐量,即在不丢包的前提下,该设备所能提供的最大传输速率。本次测试使用两块XLR系列器件级联测试此系统性能,测试用两块器件均启动一个VCPU,也即VCPU0,其上运行Linux操作系统,安装netperf网络性能测试工具。其中,第1块器件的VCPU0使用netperf发送数据报文,另一块的VCPU0接收并处理数据。表2为测试得到的转发速率。
在数据转发过程中,查看得到每个VCPU的CPU占用率为60%左右,通过优化netperf工具,可进一步提高转发性能。
4 结束语
本文基于多核多线程的处理器,从硬件配置、网络驱动程序、软件结构3个层次构建一套网络核心设备的系统架构。该架构对复杂的业务处理和高速的网络流量转发都做了优化处理。给出3个层次的设计框架,并对关键问题提出解决方案。根据本文得到的实验数据,得出利用多核多线程处理器并优化硬件配置,在软件层次优化网络流量处理流程,细粒度化业务模型,分离数据平面和控制平面,可以在完成复杂业务处理流程的前提下,大大提高网络流量转发速率。
3 性能分析
这里性能测试的目的是测试目标网络设备的网络吞吐量,即在不丢包的前提下,该设备所能提供的最大传输速率。本次测试使用两块XLR系列器件级联测试此系统性能,测试用两块器件均启动一个VCPU,也即VCPU0,其上运行Linux操作系统,安装netperf网络性能测试工具。其中,第1块器件的VCPU0使用netperf发送数据报文,另一块的VCPU0接收并处理数据。表2为测试得到的转发速率。
在数据转发过程中,查看得到每个VCPU的CPU占用率为60%左右,通过优化netperf工具,可进一步提高转发性能。
4 结束语
本文基于多核多线程的处理器,从硬件配置、网络驱动程序、软件结构3个层次构建一套网络核心设备的系统架构。该架构对复杂的业务处理和高速的网络流量转发都做了优化处理。给出3个层次的设计框架,并对关键问题提出解决方案。根据本文得到的实验数据,得出利用多核多线程处理器并优化硬件配置,在软件层次优化网络流量处理流程,细粒度化业务模型,分离数据平面和控制平面,可以在完成复杂业务处理流程的前提下,大大提高网络流量转发速率。
举报
更多回帖
rotate(-90deg);
回复
相关问答
网络驱动
中断
内存
处理器
以软件为
核心
的模块化仪器五层
架构
看完你就懂了
2021-05-12
1535
基于MEC的
网络
架构
介绍
2020-12-25
4852
数据基础
架构
的未来
2019-07-29
1321
如何利用FPGA开发高性能
网络
安全处理平台?
2019-08-12
3420
网络
存储NAS
系统
嵌入式微处理器怎么实现?
2020-04-13
2780
如何助力SDN技术实现革命性突破?
2019-09-30
1642
如何chroot不同
架构
的Ubuntu
系统
?
2019-07-30
2224
基于ATCA的测试
系统
架构
是如何构成的?
2021-05-11
1647
5G
核心
网极简开局技术
架构
及市场实践
2020-12-22
1828
平台安全
架构
对物联网安全的影响
2019-07-22
1663
发帖
登录/注册
20万+
工程师都在用,
免费
PCB检查工具
无需安装、支持浏览器和手机在线查看、实时共享
查看
点击登录
登录更多精彩功能!
首页
论坛版块
小组
免费开发板试用
ebook
直播
搜索
登录
×
20
完善资料,
赚取积分


 举报
举报



