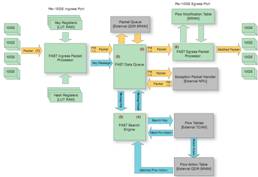
我们的流程加速子系统 (FAST) 采用 Xilinx® Virtex®-class FPGA 来完成为 CloudShield 深度包处理与修改 (CloudShield Deep Packet Processing and Modification) 刀片的包预处理。这些 FPGA 包含 10Gb 以太网 MAC,并为每个端口配备了用于分类及密钥提取的入口处理器 (ingress processor)、用于包修改的出口处理器 (egress processor)、使用四倍数据速率 (QDR) SRAM的包队列、基于赛灵思 Aurora 的消息传输通道以及基于三态内容可寻址存储器 (TCAM) 的搜索引擎。我们的 FPGA 芯片组能够以最少的 CPU 参与来完成包的高速缓存及处理,可实现每秒高达 40Gb 的高性能处理能力。其采用 2 至 7 层字段查询法,能够根据动态可重配置规则在线速条件下以灵活和可确定的方式进行包修改。
FAST 包处理器的核心功能
我们当前部署的深度包处理刀片采用两个刀片存取控制器 FPGA 和一个包交换 FPGA,所有这些都通过 LX110T Virtex-5 FPGA 来实施。每个刀片存取控制器都具备使用两个赛灵思10GbE MAC/PHY 内核实现的数据层连接功能、基于赛灵思 ChipSyncTM 技术的芯片间接口以及使用赛灵思 IP 核的包处理功能。包交换 PFGA 使用标准的赛灵思 SPI-4.2 IP 核来实现与我们的网络处理器 (NPU) 及我们的 IP 核搜索引擎接口相连。
为了将片上系统的设计重点集中在包处理功能上,我们尽可能使用标准的赛灵思 IP 核。我们选用赛灵思 10Gb 以太网 MAC 内核配合双 GTP 收发器来实施 4 x 3.125-Gbps 的 XAUI 物理层接口。针对 NPU 接口,我们使用了带动态相位对准与 ChipSync 技术且支持每 LVDS 差分对高达 1Gbps 速率的赛灵思 SPI-4 Phase 2 内核。我们主要的包处理 IP 核如下:
• FAST 包处理器:FPP 的入口包处理器 (FIPP) 负责第一层包解析、密钥与数据流 ID 的散列生成以及按端口进行的第 3 层至第 4 层校验和验证。FPP 的出口包处理器 (FEPP) 可执行出口包修改并重新计算第 3 层至第 4 层的校验和。
• FAST 搜索引擎:我们 FSE 在 TCAM 和 QDR SRAM 中维护着一个流数据库,可用于决定需要在入口包上执行的处理任务。该 FSE 可从每个端口的 FIPP 处接受密钥消息,决定针对该包需要执行的处理任务,然后将结果消息返还给原始发出消息的队列。
• FAST 数据队列:我们的数据队列 (FDQ) 可在“无序”保持缓冲器中存储传送进来的包。当入口包被写入到 QDR SRAM 时,该队列将密钥消息从 FIPP 发送至 FAST 搜索引擎。该 FSE 将使用这一密钥来决定如何处理此包,然后将结果消息返还给 FDQ。根据该结果消息,队列可对每个缓冲的包进行转发、复制或丢弃处理。此外,该队列还可对已转发或已复制的包独立进行包修改。
我们的流程加速子系统 (FAST) 采用 Xilinx® Virtex®-class FPGA 来完成为 CloudShield 深度包处理与修改 (CloudShield Deep Packet Processing and Modification) 刀片的包预处理。这些 FPGA 包含 10Gb 以太网 MAC,并为每个端口配备了用于分类及密钥提取的入口处理器 (ingress processor)、用于包修改的出口处理器 (egress processor)、使用四倍数据速率 (QDR) SRAM的包队列、基于赛灵思 Aurora 的消息传输通道以及基于三态内容可寻址存储器 (TCAM) 的搜索引擎。我们的 FPGA 芯片组能够以最少的 CPU 参与来完成包的高速缓存及处理,可实现每秒高达 40Gb 的高性能处理能力。其采用 2 至 7 层字段查询法,能够根据动态可重配置规则在线速条件下以灵活和可确定的方式进行包修改。
FAST 包处理器的核心功能
我们当前部署的深度包处理刀片采用两个刀片存取控制器 FPGA 和一个包交换 FPGA,所有这些都通过 LX110T Virtex-5 FPGA 来实施。每个刀片存取控制器都具备使用两个赛灵思10GbE MAC/PHY 内核实现的数据层连接功能、基于赛灵思 ChipSyncTM 技术的芯片间接口以及使用赛灵思 IP 核的包处理功能。包交换 PFGA 使用标准的赛灵思 SPI-4.2 IP 核来实现与我们的网络处理器 (NPU) 及我们的 IP 核搜索引擎接口相连。
为了将片上系统的设计重点集中在包处理功能上,我们尽可能使用标准的赛灵思 IP 核。我们选用赛灵思 10Gb 以太网 MAC 内核配合双 GTP 收发器来实施 4 x 3.125-Gbps 的 XAUI 物理层接口。针对 NPU 接口,我们使用了带动态相位对准与 ChipSync 技术且支持每 LVDS 差分对高达 1Gbps 速率的赛灵思 SPI-4 Phase 2 内核。我们主要的包处理 IP 核如下:
• FAST 包处理器:FPP 的入口包处理器 (FIPP) 负责第一层包解析、密钥与数据流 ID 的散列生成以及按端口进行的第 3 层至第 4 层校验和验证。FPP 的出口包处理器 (FEPP) 可执行出口包修改并重新计算第 3 层至第 4 层的校验和。
• FAST 搜索引擎:我们 FSE 在 TCAM 和 QDR SRAM 中维护着一个流数据库,可用于决定需要在入口包上执行的处理任务。该 FSE 可从每个端口的 FIPP 处接受密钥消息,决定针对该包需要执行的处理任务,然后将结果消息返还给原始发出消息的队列。
• FAST 数据队列:我们的数据队列 (FDQ) 可在“无序”保持缓冲器中存储传送进来的包。当入口包被写入到 QDR SRAM 时,该队列将密钥消息从 FIPP 发送至 FAST 搜索引擎。该 FSE 将使用这一密钥来决定如何处理此包,然后将结果消息返还给 FDQ。根据该结果消息,队列可对每个缓冲的包进行转发、复制或丢弃处理。此外,该队列还可对已转发或已复制的包独立进行包修改。

 举报
举报