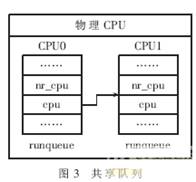
用中断驱动的均衡操作必须针对各个物理 CPU,而不是各个逻辑 CPU。否则可能会出现两种情况:一个物理 CPU 运行两个任务,而另一个物理 CPU 不运行任务;现有的调度程序不会将这种情形认为是“失衡的”。在调度程序看来,似乎是第一个物理处理器上的两个 CPU运行1-1任务,而第二个物理处理器上的两个 CPU运行0-0任务。
在2.6.0版之前,Linux只有通过load_balance( )函数才能进行CPU之间负载均衡。当某个CPU负载过轻而另一个CPU负载较重时,系统会调用load_balance( )函数从重载CPU上迁移线程到负载较轻的CPU上。只有系统最繁忙的CPU的负载超过当前CPU负载的 25% 时才进行负载平衡。找到最繁忙的CPU(源CPU)之后,确定需要迁移的线程数为源CPU负载与本CPU负载之差的一半,然后按照从 expired 队列到 active 队列、从低优先级线程到高优先级线程的顺序进行迁移。
用中断驱动的均衡操作必须针对各个物理 CPU,而不是各个逻辑 CPU。否则可能会出现两种情况:一个物理 CPU 运行两个任务,而另一个物理 CPU 不运行任务;现有的调度程序不会将这种情形认为是“失衡的”。在调度程序看来,似乎是第一个物理处理器上的两个 CPU运行1-1任务,而第二个物理处理器上的两个 CPU运行0-0任务。
在2.6.0版之前,Linux只有通过load_balance( )函数才能进行CPU之间负载均衡。当某个CPU负载过轻而另一个CPU负载较重时,系统会调用load_balance( )函数从重载CPU上迁移线程到负载较轻的CPU上。只有系统最繁忙的CPU的负载超过当前CPU负载的 25% 时才进行负载平衡。找到最繁忙的CPU(源CPU)之后,确定需要迁移的线程数为源CPU负载与本CPU负载之差的一半,然后按照从 expired 队列到 active 队列、从低优先级线程到高优先级线程的顺序进行迁移。



 举报
举报