这三类功能包含了3G所需的众多ASR性能。语音-文本转换的典型实例是语音拨号和电子邮件听写。讲者识别功能可以通过语音识别安全地读出存储器中的个人数据,从而满足信用卡定购和银行服务等保密性高的应用需要。语音命令控制功能包括连接语音扩展标记语言(VXML)网站内容的语音接口,它支持财经服务与目录助理等业务。目前VXML被用于规范网站内容的语音标签。
语音识别的两种方法
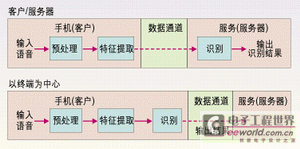
3G手机的ASR应用设计可分为两类,即以终端为中心和以客户/服务器为中心的应用。如图1所示为以终端为中心的设计方法,3G手机(终端)执行整个语音识别过程并送出识别结果。在图2所示的客户/服务器方法中,终端只是执行预处理特征提取,然后通过一个误码受保护的数据信道将这些参数发送给中心服务器,中心服务器最终完成语音识别。如果采用以客户/服务器为中心的设计方法,3G手机应使用数据信道而非移动信道来将语音发送给服务器进行识别,因为移动信道所用的低速率语音编码会严重影响语音识别的性能。
各种ASR系统的差异主要体现在词汇量上。一个简单的网络设备可能只需要16字的词库就能实现所要求的语音识别功能,而3G移动手机则需要更大的专业词库。这些词汇可以跟讲者相关(训练语音识别设备使之熟悉用户的声音特征)或跟讲者无关(语音识别设备可以识别任何人的声音),DSP的计算负荷就随着词汇量和训练数据的增加而增大。
例如,根据隐性马尔可夫模型(HMM)可以分析一个典型的跟讲者无关的100条命令识别的应用实例。假设HMM模型从左到右没有跳跃地顺序摆放,共有6个状态、5个具有对角协方差的混合高斯分布,包含39个特征(13唛-频率对数系数或MFCC,及其一阶和二阶差分),具有16位精度,那么,HMM声学模型的大小就是100×5×5×(39+2)×2=240kB。
为了实现输入语音样本差分、窗口截获、MFCC抽取、概率计算和维特比搜索等运算的实时性,典型情况下需要消耗DSP的1千万个乘法-累加周期(MMAC)。对于连续语音识别来说,上千个三音素模型和多种语法模型需要更多的存储空间,也需要更快的DSP处理速度。
因此,移动电话中ASR系统的成败很大程度上取决于DSP的功能和设计。第三代系统本身就需要比第二代系统更强性能的DSP,而增加ASR功能就对DSP提出了更高的要求。从结构角度看,对DSP性能的要求是处理速度快、功耗低和代码密度高。
采用高速DSP是关键
由于系统要实时对语音进行处理和取样,因此语音识别系统需要具有巨大的计算能力。下面的数字和计算假设采用的是围绕终端的设计方法。如果将DSP计算资源的20%分配给一个10MMAC的语音识别系统使用,那么就需要一个具有50MMAC的DSP才能满足这一功能需要,并可提供足够的空间执行3G手机所需的其它DSP任务,如处理软猫。如果采用较慢的DSP,如25MMAC的DSP,那么词汇表中的命令数量就要减半,或减少HMM参数,这样会降低整个系统性能。
DSP的速度决定了语音识别系统的复杂性和性能。举例来说,如果一个基本的跟讲者无关的连续语音识别系统需要100MMAC,DSP计算资源的50%用于满足3G手机的其它DSP任务的需求,那么DSP的处理速度就需要达到200MMAC。
这三类功能包含了3G所需的众多ASR性能。语音-文本转换的典型实例是语音拨号和电子邮件听写。讲者识别功能可以通过语音识别安全地读出存储器中的个人数据,从而满足信用卡定购和银行服务等保密性高的应用需要。语音命令控制功能包括连接语音扩展标记语言(VXML)网站内容的语音接口,它支持财经服务与目录助理等业务。目前VXML被用于规范网站内容的语音标签。
语音识别的两种方法
3G手机的ASR应用设计可分为两类,即以终端为中心和以客户/服务器为中心的应用。如图1所示为以终端为中心的设计方法,3G手机(终端)执行整个语音识别过程并送出识别结果。在图2所示的客户/服务器方法中,终端只是执行预处理特征提取,然后通过一个误码受保护的数据信道将这些参数发送给中心服务器,中心服务器最终完成语音识别。如果采用以客户/服务器为中心的设计方法,3G手机应使用数据信道而非移动信道来将语音发送给服务器进行识别,因为移动信道所用的低速率语音编码会严重影响语音识别的性能。
各种ASR系统的差异主要体现在词汇量上。一个简单的网络设备可能只需要16字的词库就能实现所要求的语音识别功能,而3G移动手机则需要更大的专业词库。这些词汇可以跟讲者相关(训练语音识别设备使之熟悉用户的声音特征)或跟讲者无关(语音识别设备可以识别任何人的声音),DSP的计算负荷就随着词汇量和训练数据的增加而增大。
例如,根据隐性马尔可夫模型(HMM)可以分析一个典型的跟讲者无关的100条命令识别的应用实例。假设HMM模型从左到右没有跳跃地顺序摆放,共有6个状态、5个具有对角协方差的混合高斯分布,包含39个特征(13唛-频率对数系数或MFCC,及其一阶和二阶差分),具有16位精度,那么,HMM声学模型的大小就是100×5×5×(39+2)×2=240kB。
为了实现输入语音样本差分、窗口截获、MFCC抽取、概率计算和维特比搜索等运算的实时性,典型情况下需要消耗DSP的1千万个乘法-累加周期(MMAC)。对于连续语音识别来说,上千个三音素模型和多种语法模型需要更多的存储空间,也需要更快的DSP处理速度。
因此,移动电话中ASR系统的成败很大程度上取决于DSP的功能和设计。第三代系统本身就需要比第二代系统更强性能的DSP,而增加ASR功能就对DSP提出了更高的要求。从结构角度看,对DSP性能的要求是处理速度快、功耗低和代码密度高。
采用高速DSP是关键
由于系统要实时对语音进行处理和取样,因此语音识别系统需要具有巨大的计算能力。下面的数字和计算假设采用的是围绕终端的设计方法。如果将DSP计算资源的20%分配给一个10MMAC的语音识别系统使用,那么就需要一个具有50MMAC的DSP才能满足这一功能需要,并可提供足够的空间执行3G手机所需的其它DSP任务,如处理软猫。如果采用较慢的DSP,如25MMAC的DSP,那么词汇表中的命令数量就要减半,或减少HMM参数,这样会降低整个系统性能。
DSP的速度决定了语音识别系统的复杂性和性能。举例来说,如果一个基本的跟讲者无关的连续语音识别系统需要100MMAC,DSP计算资源的50%用于满足3G手机的其它DSP任务的需求,那么DSP的处理速度就需要达到200MMAC。

 举报
举报