FPGA 学习小组
登录
直播中
刘娜
7年用户
174经验值
私信
关注
如何利用FPGA研究设计平台为网络发展加速?
开启该帖子的消息推送
FPGA
赛灵思
斯坦福大学与赛灵思研究实验室(Xilinx Research Labs)联手开发专门面向研究社群的第二代高速网络设计平台 Net
FPGA
-10G。该新型平台采用最先进的技术,能够帮助研究人员迅速构建高速复杂的原型,以解决网络领域新出现的技术问题。正如第一代平台已在世界各地的大学中得到广泛应用一样,我们希望新平台能够催生一个开源社区,贡献并共享IP,从而加快创新步伐。
回帖
(3)
王国花
2019-8-27 16:19:43
开源软件库有助于软件、IP核以及设计经验的共享,进而催生新一代网络问题的解决方案。
基础平台为最终用户提供了迅速上手所需的所有要素,而开源社区则可以让研究人员利用彼此的成果,这样一来最大限度地减少了理念实际实施所需的时间,从而让设计人员集中精力进行创新。
2007年,我们开发出了第一代开发板NetFPGA-1G,采用赛灵思Virtex-II Pro 50,主要用于电气工程和计算机科学系学生的网络硬件教学。许多电气工程和计算机科学的毕业生走上了开发网络产品的岗位,我们希望他们能够有机会进行实际操作,亲自动手使用业界标准设计流程开发以线速运行且可植入正在运行的网络中的硬件。为此,最初的开发板必须具有低成本性。在多家半导体供应商的慷慨捐赠下,我们得以把设计的最终价格压到500美元以下。结果许多大学很快采用了该开发板,目前约有2,000个NetFPGA-1G开发板被世界各地的150个学院使用。
不过很快NetFPGA就超越了教学工具的范畴。研究社群逐渐将其用于实验和原型设计。为此,NetFPGA小组提供了免费的开源参考设计,并维护着有约50项研究人员所贡献设计的设计库。我们为新用户提供支持,运行在线论坛,提供辅导资料,举办夏令营和开发人员技术座谈。
可编程技术势在必行
10多年以来,网络技术在交换机、路由器及其它产品中的发展越来越体现出转发路径的可编程性。这在很大程度上是因为随着更多隧道格式、服务质量方案、防火墙过滤器和加密技术等的问世,网络硬件日益复杂化。加上日新月异的标准,可编程技术势在必行,比如说使用NPU或FPGA。
研究人员往往想改变部分或所有转发流水线。近来,有许多人关注全新的转发模型,比如OpenFlow。研究人员可以在全国范围内在国家级测试平台上,比如美国的GENI(
http://geni.net
)和欧盟的FIRE(
http://cordis.europa.eu/fp7/ict/fire/calls_en.html
)上试验新型网络架构。
研究人员还越来越多地将NetFPGA开发板用于新理念的硬件原型设计,诸如新的转发模式、调度与查找算法,以及新的深层数据监测器。NetFPGA开发板上最常见的参考设计是功能齐全的开源OpenFlow交换机,可以让研究人员体验到标准设计的各个变体。另一项常用的参考设计则可以通过镜像硬件中内核路由表并以线速转发所有数据包来加速计算机主机内置的路由功能。
第二代NetFPGA
在第二代平台NetFPGA-10G上,我们添加了易用性,旨在为最终客户提供基本的基础架构,以简化他们的设计工作,这不仅扩大了我们的原始设计目标,而且这个目标与赛灵思主流目标设计平台的目标很接近,即除FPGA芯片外,还为客户提供工具、IP核和参考设计,以加快设计流程。
为实现这一目标,我们将以基础IP构建块和特定领域IP构建块形式提供与FPGA基础架构设计配套的开发板,以增强易用性,缩短开发时间。我们将进一步开发诸如网络接口卡和IPv4参考路由器等参考设计,以及协助设计构建、仿真和调试的基本基础架构。我们的想法是让用户把开发时间真正聚焦于他们特定的专业领域或者专题上,无需深入了解底层硬件的详细情况。
与主流目标设计平台不一样,我们的网络平台针对的是一个与众不同的最终用户群体,即囊括了学术研究和商业研究的这样一个庞大的研究群体。为了让该开发板得到广泛采用,多家半导体合作伙伴慷慨解囊,期望能将其成本降至最低。赛灵思及Micron、赛普拉斯半导体公司和NetLogic Microsystems等其他主力组件制造商也纷纷在向学术界最终用户捐赠部件(商业研究人员则需给付更高的价格)。
这个项目的部分优势在于这个平台得到了社区和开源硬件库的支持,可以以最初的基础方案为基础,促进软件、IP核和经验的共享。这样,我们期望在众多知名大学、研究群体和企业的支持下,IP库能够日益扩大完善,最终能够覆盖各种参考组件、网络IP核、软件和尖端的基础构架。我们还期望通过提供精心设计的框架,用系统的方法对专业知识和IP的共享稍加协调,并采用具有标准接口的设计精良的即插即用型架构,就可以让开源硬件库不断扩大,从而催生新一代网络问题的解决方案。
图1:围绕Virtex-5 FPGA构建的NetFPGA-10G板卡。
NetFPGA-10G是一种40Gb/s的PCI Express适配卡,拥有庞大的FPGA架构,能够尽可能多地支持各种应用。如图1所示,该板卡设计以一个大型的赛灵思FPGA器件Virtex-5 XC5VTX240T-2为中心。
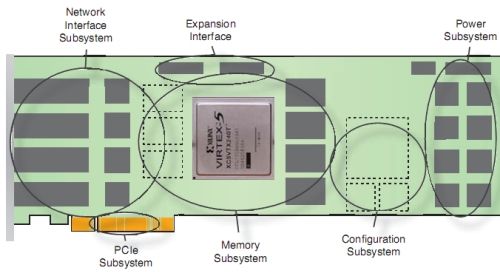
图2:FPGA开发板与网络接口、PCIe、扩展、存储器、配置和电源五个子系统相连。
FPGA与5个子系统相连(见图2)。第一个子系统是网络接口子系统,有4个带有物理层器件的10Gbps以太网接口,用于让网络流量进入FPGA。第二个子系统是存储子系统,其由多个QDRII和RLDRAMII组件构成。I/O主要用于该接口,用来为诸如路由表或包缓存这样的功能提供尽可能高的可用片外带宽。第三个子系统是PCIe子系统。
第四个子系统是扩展接口,用于加载子卡或与其它板卡通信。为此我们把所有剩余的高速串行I/O连接端都接到了两个高速接插件上。第五个子系统是配置子系统,用于FPGA的配置。
总体而言,该板卡就是作为一个双插槽、全尺寸PCIe适配器来实现的。使用两个插槽是出于散热、功耗和高度方面的考虑。与高端图形卡一样,该板卡需要外接ATX电源,因为FPGA在绝对最大负载条件下,功耗可能会超过单槽PCIe允许的50W。不过该板卡也可在服务器环境外独立运行。
开源软件库有助于软件、IP核以及设计经验的共享,进而催生新一代网络问题的解决方案。
基础平台为最终用户提供了迅速上手所需的所有要素,而开源社区则可以让研究人员利用彼此的成果,这样一来最大限度地减少了理念实际实施所需的时间,从而让设计人员集中精力进行创新。
2007年,我们开发出了第一代开发板NetFPGA-1G,采用赛灵思Virtex-II Pro 50,主要用于电气工程和计算机科学系学生的网络硬件教学。许多电气工程和计算机科学的毕业生走上了开发网络产品的岗位,我们希望他们能够有机会进行实际操作,亲自动手使用业界标准设计流程开发以线速运行且可植入正在运行的网络中的硬件。为此,最初的开发板必须具有低成本性。在多家半导体供应商的慷慨捐赠下,我们得以把设计的最终价格压到500美元以下。结果许多大学很快采用了该开发板,目前约有2,000个NetFPGA-1G开发板被世界各地的150个学院使用。
不过很快NetFPGA就超越了教学工具的范畴。研究社群逐渐将其用于实验和原型设计。为此,NetFPGA小组提供了免费的开源参考设计,并维护着有约50项研究人员所贡献设计的设计库。我们为新用户提供支持,运行在线论坛,提供辅导资料,举办夏令营和开发人员技术座谈。
可编程技术势在必行
10多年以来,网络技术在交换机、路由器及其它产品中的发展越来越体现出转发路径的可编程性。这在很大程度上是因为随着更多隧道格式、服务质量方案、防火墙过滤器和加密技术等的问世,网络硬件日益复杂化。加上日新月异的标准,可编程技术势在必行,比如说使用NPU或FPGA。
研究人员往往想改变部分或所有转发流水线。近来,有许多人关注全新的转发模型,比如OpenFlow。研究人员可以在全国范围内在国家级测试平台上,比如美国的GENI(
http://geni.net
)和欧盟的FIRE(
http://cordis.europa.eu/fp7/ict/fire/calls_en.html
)上试验新型网络架构。
研究人员还越来越多地将NetFPGA开发板用于新理念的硬件原型设计,诸如新的转发模式、调度与查找算法,以及新的深层数据监测器。NetFPGA开发板上最常见的参考设计是功能齐全的开源OpenFlow交换机,可以让研究人员体验到标准设计的各个变体。另一项常用的参考设计则可以通过镜像硬件中内核路由表并以线速转发所有数据包来加速计算机主机内置的路由功能。
第二代NetFPGA
在第二代平台NetFPGA-10G上,我们添加了易用性,旨在为最终客户提供基本的基础架构,以简化他们的设计工作,这不仅扩大了我们的原始设计目标,而且这个目标与赛灵思主流目标设计平台的目标很接近,即除FPGA芯片外,还为客户提供工具、IP核和参考设计,以加快设计流程。
为实现这一目标,我们将以基础IP构建块和特定领域IP构建块形式提供与FPGA基础架构设计配套的开发板,以增强易用性,缩短开发时间。我们将进一步开发诸如网络接口卡和IPv4参考路由器等参考设计,以及协助设计构建、仿真和调试的基本基础架构。我们的想法是让用户把开发时间真正聚焦于他们特定的专业领域或者专题上,无需深入了解底层硬件的详细情况。
与主流目标设计平台不一样,我们的网络平台针对的是一个与众不同的最终用户群体,即囊括了学术研究和商业研究的这样一个庞大的研究群体。为了让该开发板得到广泛采用,多家半导体合作伙伴慷慨解囊,期望能将其成本降至最低。赛灵思及Micron、赛普拉斯半导体公司和NetLogic Microsystems等其他主力组件制造商也纷纷在向学术界最终用户捐赠部件(商业研究人员则需给付更高的价格)。
这个项目的部分优势在于这个平台得到了社区和开源硬件库的支持,可以以最初的基础方案为基础,促进软件、IP核和经验的共享。这样,我们期望在众多知名大学、研究群体和企业的支持下,IP库能够日益扩大完善,最终能够覆盖各种参考组件、网络IP核、软件和尖端的基础构架。我们还期望通过提供精心设计的框架,用系统的方法对专业知识和IP的共享稍加协调,并采用具有标准接口的设计精良的即插即用型架构,就可以让开源硬件库不断扩大,从而催生新一代网络问题的解决方案。
图1:围绕Virtex-5 FPGA构建的NetFPGA-10G板卡。
NetFPGA-10G是一种40Gb/s的PCI Express适配卡,拥有庞大的FPGA架构,能够尽可能多地支持各种应用。如图1所示,该板卡设计以一个大型的赛灵思FPGA器件Virtex-5 XC5VTX240T-2为中心。
图2:FPGA开发板与网络接口、PCIe、扩展、存储器、配置和电源五个子系统相连。
FPGA与5个子系统相连(见图2)。第一个子系统是网络接口子系统,有4个带有物理层器件的10Gbps以太网接口,用于让网络流量进入FPGA。第二个子系统是存储子系统,其由多个QDRII和RLDRAMII组件构成。I/O主要用于该接口,用来为诸如路由表或包缓存这样的功能提供尽可能高的可用片外带宽。第三个子系统是PCIe子系统。
第四个子系统是扩展接口,用于加载子卡或与其它板卡通信。为此我们把所有剩余的高速串行I/O连接端都接到了两个高速接插件上。第五个子系统是配置子系统,用于FPGA的配置。
总体而言,该板卡就是作为一个双插槽、全尺寸PCIe适配器来实现的。使用两个插槽是出于散热、功耗和高度方面的考虑。与高端图形卡一样,该板卡需要外接ATX电源,因为FPGA在绝对最大负载条件下,功耗可能会超过单槽PCIe允许的50W。不过该板卡也可在服务器环境外独立运行。
举报
李凯生
2019-8-27 16:19:51
存储器子系统
我们设计流程的核心焦点是到SRAM和DRAM组件的接口。因为FPGA器件上的I/O总数限制了可用的片外总带宽,我们必须小心地达成一定的妥协,争取尽量多支持一些应用。要支持从网络监控到安全性、路由、流量管理等各类应用,会带来很大不同的约束。
例如,对外部存储器存取来说,网络监控器会采用一个大型的基于流量的统计表,而且多数情况下可能还需要一个流量分类查找表。对两者的存取都会带来较短的时延,因为流量分类需要对内部依赖性进行多次查找,而流量统计表的更新则一般会覆盖整个读取—修改—写入周期。因此,SRAM是合适的器件选择。不过流量管理器主要需要大量存储空间用于包缓存,通常出于密度要求,还会采用DRAM组件。对外部存储器而言,最后可以考虑使用需要路由表查找和包缓存的IPv4路由器。
总结各种应用的要求,我们认识到某些功能会占用外部存储器带宽,不管是SRAM还是DRAM。包缓存(要求大量存储空间)适合采用DRAM,SRAM则更适用于流量分类搜索存取、路由表查询、基于流量的数据统计表或基于规则的防火墙、用于包缓冲区实现的存储器管理表以及报头队列等。
所有这些功能都需要逐包执行。因此,假定在最恶劣的情况下最小尺寸的包是带20字节开销的64字节,系统需要处理的包率就是大约每秒6000万个包。其次,我们需要将存取做进一步的区分。首先,许多存储器组件,比如QDR SRAM和RLDRAM SIO器件有独立的读/写数据总线。由于存取模式不能假定为系统分布,我们就无法汇聚总的存取带宽,不得不对单独考虑每项业务。
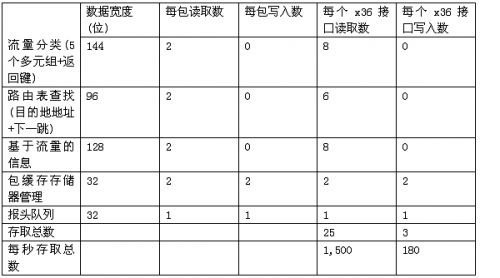
另外,还存在第三类存取,就是“搜索”。搜索可以通过基于TCAM的器件很好地完成,搜索时延固定,且确保能获得搜索结果。不过,出于价格和功耗方面的考虑,以及TCAM会进一步限制I/O使用,我们不准备在我们的开发板上使用TCAM器件。搜索还可以通过诸如决策树、哈希算法和分解法等其他方式来完成,可采用高速缓存也可不用,仅以这些为例。为了便于探讨,我们假定完成一次搜索平均需要近两次读取。鉴于此,以及对数据宽度进行了一些惯常的假设后,我们将要求精简为表1所示。
表1:SRAM带宽需求。
假定接口上的时钟速度为300MHz,那么QDRII接口可以实现每秒2X300=6亿次读/写存取操作。因此,三个QDRII x36位的接口就可以满足我们的所有要求。
对于DRAM存取,我们主要考虑的是包存储的方便程度,仅从存储器中对包进行一次读/写。把包开销从原本进入的2x40Gbps中扣除后,这相对于约62Gbps的存取带宽。用物理资源来衡量,RLDRAMII存取可以实现约97%的效率,而DDR2或DDR3存储设备则可能在40%左右,因此会要求多得多的I/O。因此我们选择了RLDRAMII CIO组件。两个运行在300MHz的64位RLDRAMII接口提供的总带宽可以大致满足这个要求。
网络接口
NetFPGA-10G的网络接口由4个能够以10Gbps或1Gbps以太网链路方式运行的子系统构成。为了最大化平台的利用率和最小化功耗,我们使用了4个增强型小型封装可热插拔(SFP+)模块(cage)作为物理接口。与XENPAK和XFP等其他10G收发器标准相比,SFP+在功耗和尺寸方面有着明显的优势。使用SFP+模块,可以支持一系列接口标准,包括10GBase-LR、10GBase-SR、10GBase-LRM和低成本直联SFP+铜缆(双同轴)。此外,还可以利用针对1Gpbs运行的SFP模块,从而支持1000Base-T或1000Base-X物理标准。
4个SFP+模块每个都通过SFI接口连接到一个NetLogic AEL2005器件。AEL2005是一个带有符合IEEE 802.3aq规范的嵌入式电分散补偿引擎的10Gb以太网物理层收发器。除了常规的10G模式,该物理层器件还能够支持千兆位以太网(1G)模式。在系统侧,这些物理层器件通过一个10Gb连接单元接口(XAUI)连接到FPGA。在1G模式下工作时,其中一个XAUI信道用作串行千兆位介质无关接口(SGMII)。
Virtex-5 FPGA内部提供适当的IP核。对于10Gbps的业务,赛灵思推出了XAUI LogiCORE IP核和10Gb以太网媒体访问控制器(10GEMAC)LogiCORE IP核。对于1G的业务,接口可以直接连接至赛灵思嵌入式三态以太网MAC内核。
PCIe子系统
NetFPGA-10G平台使用开放式组件可移植性基础架构(OpenCPI)作为开发板和计算机主机通过PCIe互联的主要互联实现方式[7]。我们目前支持x8的第一代,将来可能会升级到支持第二代。OpenCPI是一种通用开源框架,用于连接使用不同类型的通信接口、且带宽和时延要求不同的IP模块(串流、字节可寻址等)。就其本质来说,OpenCPI是一种高度可配置的框架,能够为用于快速实现新设计的IP核提供关键性的通信“桥梁”。
OpenCPI为NetFPGA-10G平台带来了一些关键特性。在软件侧,我们能够提供无干扰(clean)DMA接口,用于传输数据(主要是数据包,虽然也有其他类型的信息)以及通过编程的输入/输出控制器件。对于网络应用,我们提供Linux网络驱动程序,将网络接口导出到NetFPGA器件上的每个物理以太网端口上。这样可以让用户空间软件把网络数据包传输到器件上,并且读取设计中任何主机可视寄存器。
在硬件侧,OpenCPI为我们提供了无干扰、甚至多种数据流接口,而且每个接口都可以通过OpenCPI框架进行配置。此外,OpenCPI能够处理主机侧和硬件侧所有的缓存和PCIe事务处理,这样用户就能够集中精力进行特定应用开发,而不必处理器件通信的细节。
扩展接口与配置子系统
扩展接口子系统的目的是让用户通过连接第二块NetFPGA-10G板卡来增加端口密度,比如通过光学子卡来丰富网络接口特性,或者通过高速串行接口连接更多搜索组件,比如基于知识的处理器等。我们将FPGA上的20个GTX收发器取出,然后通过AC耦合传输线连接到两个高速接插件上。这些接插件是为诸如XAUI、PCIe、SATA和Infiniband这样的传输接口设计的,既可以通过匹配接插件直接连接到另一块板卡上,也可以通过电缆组件连接到另一块板卡上。每条传输线经测试双向传输速率均可达到6.5Gbps,从而为进出FPGA提供了一条额外的130Gbps数据路径。
例如,对外部存储器存取来说,网络监控器会采用一个大型的基于流量的统计表,而且多数情况下可能还需要一个流量分类查找表。对两者的存取都会带来较短的时延,因为流量分类需要对内部依赖性进行多次查找,而流量统计表的更新则一般会覆盖整个读取—修改—写入周期。因此,SRAM是合适的器件选择。不过流量管理器主要需要大量存储空间用于包缓存,通常出于密度要求,还会采用DRAM组件。对外部存储器而言,最后可以考虑使用需要路由表查找和包缓存的IPv4路由器。
总结各种应用的要求,我们认识到某些功能会占用外部存储器带宽,不管是SRAM还是DRAM。包缓存(要求大量存储空间)适合采用DRAM,SRAM则更适用于流量分类搜索存取、路由表查询、基于流量的数据统计表或基于规则的防火墙、用于包缓冲区实现的存储器管理表以及报头队列等。
所有这些功能都需要逐包执行。因此,假定在最恶劣的情况下最小尺寸的包是带20字节开销的64字节,系统需要处理的包率就是大约每秒6000万个包。其次,我们需要将存取做进一步的区分。首先,许多存储器组件,比如QDR SRAM和RLDRAM SIO器件有独立的读/写数据总线。由于存取模式不能假定为系统分布,我们就无法汇聚总的存取带宽,不得不对单独考虑每项业务。
另外,还存在第三类存取,就是“搜索”。搜索可以通过基于TCAM的器件很好地完成,搜索时延固定,且确保能获得搜索结果。不过,出于价格和功耗方面的考虑,以及TCAM会进一步限制I/O使用,我们不准备在我们的开发板上使用TCAM器件。搜索还可以通过诸如决策树、哈希算法和分解法等其他方式来完成,可采用高速缓存也可不用,仅以这些为例。为了便于探讨,我们假定完成一次搜索平均需要近两次读取。鉴于此,以及对数据宽度进行了一些惯常的假设后,我们将要求精简为表1所示。
表1:SRAM带宽需求。
假定接口上的时钟速度为300MHz,那么QDRII接口可以实现每秒2X300=6亿次读/写存取操作。因此,三个QDRII x36位的接口就可以满足我们的所有要求。
对于DRAM存取,我们主要考虑的是包存储的方便程度,仅从存储器中对包进行一次读/写。把包开销从原本进入的2x40Gbps中扣除后,这相对于约62Gbps的存取带宽。用物理资源来衡量,RLDRAMII存取可以实现约97%的效率,而DDR2或DDR3存储设备则可能在40%左右,因此会要求多得多的I/O。因此我们选择了RLDRAMII CIO组件。两个运行在300MHz的64位RLDRAMII接口提供的总带宽可以大致满足这个要求。
存储器子系统
我们设计流程的核心焦点是到SRAM和DRAM组件的接口。因为FPGA器件上的I/O总数限制了可用的片外总带宽,我们必须小心地达成一定的妥协,争取尽量多支持一些应用。要支持从网络监控到安全性、路由、流量管理等各类应用,会带来很大不同的约束。
例如,对外部存储器存取来说,网络监控器会采用一个大型的基于流量的统计表,而且多数情况下可能还需要一个流量分类查找表。对两者的存取都会带来较短的时延,因为流量分类需要对内部依赖性进行多次查找,而流量统计表的更新则一般会覆盖整个读取—修改—写入周期。因此,SRAM是合适的器件选择。不过流量管理器主要需要大量存储空间用于包缓存,通常出于密度要求,还会采用DRAM组件。对外部存储器而言,最后可以考虑使用需要路由表查找和包缓存的IPv4路由器。
总结各种应用的要求,我们认识到某些功能会占用外部存储器带宽,不管是SRAM还是DRAM。包缓存(要求大量存储空间)适合采用DRAM,SRAM则更适用于流量分类搜索存取、路由表查询、基于流量的数据统计表或基于规则的防火墙、用于包缓冲区实现的存储器管理表以及报头队列等。
所有这些功能都需要逐包执行。因此,假定在最恶劣的情况下最小尺寸的包是带20字节开销的64字节,系统需要处理的包率就是大约每秒6000万个包。其次,我们需要将存取做进一步的区分。首先,许多存储器组件,比如QDR SRAM和RLDRAM SIO器件有独立的读/写数据总线。由于存取模式不能假定为系统分布,我们就无法汇聚总的存取带宽,不得不对单独考虑每项业务。
另外,还存在第三类存取,就是“搜索”。搜索可以通过基于TCAM的器件很好地完成,搜索时延固定,且确保能获得搜索结果。不过,出于价格和功耗方面的考虑,以及TCAM会进一步限制I/O使用,我们不准备在我们的开发板上使用TCAM器件。搜索还可以通过诸如决策树、哈希算法和分解法等其他方式来完成,可采用高速缓存也可不用,仅以这些为例。为了便于探讨,我们假定完成一次搜索平均需要近两次读取。鉴于此,以及对数据宽度进行了一些惯常的假设后,我们将要求精简为表1所示。
表1:SRAM带宽需求。
假定接口上的时钟速度为300MHz,那么QDRII接口可以实现每秒2X300=6亿次读/写存取操作。因此,三个QDRII x36位的接口就可以满足我们的所有要求。
对于DRAM存取,我们主要考虑的是包存储的方便程度,仅从存储器中对包进行一次读/写。把包开销从原本进入的2x40Gbps中扣除后,这相对于约62Gbps的存取带宽。用物理资源来衡量,RLDRAMII存取可以实现约97%的效率,而DDR2或DDR3存储设备则可能在40%左右,因此会要求多得多的I/O。因此我们选择了RLDRAMII CIO组件。两个运行在300MHz的64位RLDRAMII接口提供的总带宽可以大致满足这个要求。
网络接口
NetFPGA-10G的网络接口由4个能够以10Gbps或1Gbps以太网链路方式运行的子系统构成。为了最大化平台的利用率和最小化功耗,我们使用了4个增强型小型封装可热插拔(SFP+)模块(cage)作为物理接口。与XENPAK和XFP等其他10G收发器标准相比,SFP+在功耗和尺寸方面有着明显的优势。使用SFP+模块,可以支持一系列接口标准,包括10GBase-LR、10GBase-SR、10GBase-LRM和低成本直联SFP+铜缆(双同轴)。此外,还可以利用针对1Gpbs运行的SFP模块,从而支持1000Base-T或1000Base-X物理标准。
4个SFP+模块每个都通过SFI接口连接到一个NetLogic AEL2005器件。AEL2005是一个带有符合IEEE 802.3aq规范的嵌入式电分散补偿引擎的10Gb以太网物理层收发器。除了常规的10G模式,该物理层器件还能够支持千兆位以太网(1G)模式。在系统侧,这些物理层器件通过一个10Gb连接单元接口(XAUI)连接到FPGA。在1G模式下工作时,其中一个XAUI信道用作串行千兆位介质无关接口(SGMII)。
Virtex-5 FPGA内部提供适当的IP核。对于10Gbps的业务,赛灵思推出了XAUI LogiCORE IP核和10Gb以太网媒体访问控制器(10GEMAC)LogiCORE IP核。对于1G的业务,接口可以直接连接至赛灵思嵌入式三态以太网MAC内核。
PCIe子系统
NetFPGA-10G平台使用开放式组件可移植性基础架构(OpenCPI)作为开发板和计算机主机通过PCIe互联的主要互联实现方式[7]。我们目前支持x8的第一代,将来可能会升级到支持第二代。OpenCPI是一种通用开源框架,用于连接使用不同类型的通信接口、且带宽和时延要求不同的IP模块(串流、字节可寻址等)。就其本质来说,OpenCPI是一种高度可配置的框架,能够为用于快速实现新设计的IP核提供关键性的通信“桥梁”。
OpenCPI为NetFPGA-10G平台带来了一些关键特性。在软件侧,我们能够提供无干扰(clean)DMA接口,用于传输数据(主要是数据包,虽然也有其他类型的信息)以及通过编程的输入/输出控制器件。对于网络应用,我们提供Linux网络驱动程序,将网络接口导出到NetFPGA器件上的每个物理以太网端口上。这样可以让用户空间软件把网络数据包传输到器件上,并且读取设计中任何主机可视寄存器。
在硬件侧,OpenCPI为我们提供了无干扰、甚至多种数据流接口,而且每个接口都可以通过OpenCPI框架进行配置。此外,OpenCPI能够处理主机侧和硬件侧所有的缓存和PCIe事务处理,这样用户就能够集中精力进行特定应用开发,而不必处理器件通信的细节。
扩展接口与配置子系统
扩展接口子系统的目的是让用户通过连接第二块NetFPGA-10G板卡来增加端口密度,比如通过光学子卡来丰富网络接口特性,或者通过高速串行接口连接更多搜索组件,比如基于知识的处理器等。我们将FPGA上的20个GTX收发器取出,然后通过AC耦合传输线连接到两个高速接插件上。这些接插件是为诸如XAUI、PCIe、SATA和Infiniband这样的传输接口设计的,既可以通过匹配接插件直接连接到另一块板卡上,也可以通过电缆组件连接到另一块板卡上。每条传输线经测试双向传输速率均可达到6.5Gbps,从而为进出FPGA提供了一条额外的130Gbps数据路径。
例如,对外部存储器存取来说,网络监控器会采用一个大型的基于流量的统计表,而且多数情况下可能还需要一个流量分类查找表。对两者的存取都会带来较短的时延,因为流量分类需要对内部依赖性进行多次查找,而流量统计表的更新则一般会覆盖整个读取—修改—写入周期。因此,SRAM是合适的器件选择。不过流量管理器主要需要大量存储空间用于包缓存,通常出于密度要求,还会采用DRAM组件。对外部存储器而言,最后可以考虑使用需要路由表查找和包缓存的IPv4路由器。
总结各种应用的要求,我们认识到某些功能会占用外部存储器带宽,不管是SRAM还是DRAM。包缓存(要求大量存储空间)适合采用DRAM,SRAM则更适用于流量分类搜索存取、路由表查询、基于流量的数据统计表或基于规则的防火墙、用于包缓冲区实现的存储器管理表以及报头队列等。
所有这些功能都需要逐包执行。因此,假定在最恶劣的情况下最小尺寸的包是带20字节开销的64字节,系统需要处理的包率就是大约每秒6000万个包。其次,我们需要将存取做进一步的区分。首先,许多存储器组件,比如QDR SRAM和RLDRAM SIO器件有独立的读/写数据总线。由于存取模式不能假定为系统分布,我们就无法汇聚总的存取带宽,不得不对单独考虑每项业务。
另外,还存在第三类存取,就是“搜索”。搜索可以通过基于TCAM的器件很好地完成,搜索时延固定,且确保能获得搜索结果。不过,出于价格和功耗方面的考虑,以及TCAM会进一步限制I/O使用,我们不准备在我们的开发板上使用TCAM器件。搜索还可以通过诸如决策树、哈希算法和分解法等其他方式来完成,可采用高速缓存也可不用,仅以这些为例。为了便于探讨,我们假定完成一次搜索平均需要近两次读取。鉴于此,以及对数据宽度进行了一些惯常的假设后,我们将要求精简为表1所示。
表1:SRAM带宽需求。
假定接口上的时钟速度为300MHz,那么QDRII接口可以实现每秒2X300=6亿次读/写存取操作。因此,三个QDRII x36位的接口就可以满足我们的所有要求。
对于DRAM存取,我们主要考虑的是包存储的方便程度,仅从存储器中对包进行一次读/写。把包开销从原本进入的2x40Gbps中扣除后,这相对于约62Gbps的存取带宽。用物理资源来衡量,RLDRAMII存取可以实现约97%的效率,而DDR2或DDR3存储设备则可能在40%左右,因此会要求多得多的I/O。因此我们选择了RLDRAMII CIO组件。两个运行在300MHz的64位RLDRAMII接口提供的总带宽可以大致满足这个要求。
举报
李辉
2019-8-27 16:19:53
网络接口
NetFPGA-10G的网络接口由4个能够以10Gbps或1Gbps以太网链路方式运行的子系统构成。为了最大化平台的利用率和最小化功耗,我们使用了4个增强型小型封装可热插拔(SFP+)模块(cage)作为物理接口。与XENPAK和XFP等其他10G收发器标准相比,SFP+在功耗和尺寸方面有着明显的优势。使用SFP+模块,可以支持一系列接口标准,包括10GBase-LR、10GBase-SR、10GBase-LRM和低成本直联SFP+铜缆(双同轴)。此外,还可以利用针对1Gpbs运行的SFP模块,从而支持1000Base-T或1000Base-X物理标准。
4个SFP+模块每个都通过SFI接口连接到一个NetLogic AEL2005器件。AEL2005是一个带有符合IEEE 802.3aq规范的嵌入式电分散补偿引擎的10Gb以太网物理层收发器。除了常规的10G模式,该物理层器件还能够支持千兆位以太网(1G)模式。在系统侧,这些物理层器件通过一个10Gb连接单元接口(XAUI)连接到FPGA。在1G模式下工作时,其中一个XAUI信道用作串行千兆位介质无关接口(SGMII)。
Virtex-5 FPGA内部提供适当的IP核。对于10Gbps的业务,赛灵思推出了XAUI LogiCORE IP核和10Gb以太网媒体访问控制器(10GEMAC)LogiCORE IP核。对于1G的业务,接口可以直接连接至赛灵思嵌入式三态以太网MAC内核。
PCIe子系统
NetFPGA-10G平台使用开放式组件可移植性基础架构(OpenCPI)作为开发板和计算机主机通过PCIe互联的主要互联实现方式[7]。我们目前支持x8的第一代,将来可能会升级到支持第二代。OpenCPI是一种通用开源框架,用于连接使用不同类型的通信接口、且带宽和时延要求不同的IP模块(串流、字节可寻址等)。就其本质来说,OpenCPI是一种高度可配置的框架,能够为用于快速实现新设计的IP核提供关键性的通信“桥梁”。
OpenCPI为NetFPGA-10G平台带来了一些关键特性。在软件侧,我们能够提供无干扰(clean)DMA接口,用于传输数据(主要是数据包,虽然也有其他类型的信息)以及通过编程的输入/输出控制器件。对于网络应用,我们提供Linux网络驱动程序,将网络接口导出到NetFPGA器件上的每个物理以太网端口上。这样可以让用户空间软件把网络数据包传输到器件上,并且读取设计中任何主机可视寄存器。
在硬件侧,OpenCPI为我们提供了无干扰、甚至多种数据流接口,而且每个接口都可以通过OpenCPI框架进行配置。此外,OpenCPI能够处理主机侧和硬件侧所有的缓存和PCIe事务处理,这样用户就能够集中精力进行特定应用开发,而不必处理器件通信的细节。
扩展接口与配置子系统
扩展接口子系统的目的是让用户通过连接第二块NetFPGA-10G板卡来增加端口密度,比如通过光学子卡来丰富网络接口特性,或者通过高速串行接口连接更多搜索组件,比如基于知识的处理器等。我们将FPGA上的20个GTX收发器取出,然后通过AC耦合传输线连接到两个高速接插件上。这些接插件是为诸如XAUI、PCIe、SATA和Infiniband这样的传输接口设计的,既可以通过匹配接插件直接连接到另一块板卡上,也可以通过电缆组件连接到另一块板卡上。每条传输线经测试双向传输速率均可达到6.5Gbps,从而为进出FPGA提供了一条额外的130Gbps数据路径。
网络接口
NetFPGA-10G的网络接口由4个能够以10Gbps或1Gbps以太网链路方式运行的子系统构成。为了最大化平台的利用率和最小化功耗,我们使用了4个增强型小型封装可热插拔(SFP+)模块(cage)作为物理接口。与XENPAK和XFP等其他10G收发器标准相比,SFP+在功耗和尺寸方面有着明显的优势。使用SFP+模块,可以支持一系列接口标准,包括10GBase-LR、10GBase-SR、10GBase-LRM和低成本直联SFP+铜缆(双同轴)。此外,还可以利用针对1Gpbs运行的SFP模块,从而支持1000Base-T或1000Base-X物理标准。
4个SFP+模块每个都通过SFI接口连接到一个NetLogic AEL2005器件。AEL2005是一个带有符合IEEE 802.3aq规范的嵌入式电分散补偿引擎的10Gb以太网物理层收发器。除了常规的10G模式,该物理层器件还能够支持千兆位以太网(1G)模式。在系统侧,这些物理层器件通过一个10Gb连接单元接口(XAUI)连接到FPGA。在1G模式下工作时,其中一个XAUI信道用作串行千兆位介质无关接口(SGMII)。
Virtex-5 FPGA内部提供适当的IP核。对于10Gbps的业务,赛灵思推出了XAUI LogiCORE IP核和10Gb以太网媒体访问控制器(10GEMAC)LogiCORE IP核。对于1G的业务,接口可以直接连接至赛灵思嵌入式三态以太网MAC内核。
PCIe子系统
NetFPGA-10G平台使用开放式组件可移植性基础架构(OpenCPI)作为开发板和计算机主机通过PCIe互联的主要互联实现方式[7]。我们目前支持x8的第一代,将来可能会升级到支持第二代。OpenCPI是一种通用开源框架,用于连接使用不同类型的通信接口、且带宽和时延要求不同的IP模块(串流、字节可寻址等)。就其本质来说,OpenCPI是一种高度可配置的框架,能够为用于快速实现新设计的IP核提供关键性的通信“桥梁”。
OpenCPI为NetFPGA-10G平台带来了一些关键特性。在软件侧,我们能够提供无干扰(clean)DMA接口,用于传输数据(主要是数据包,虽然也有其他类型的信息)以及通过编程的输入/输出控制器件。对于网络应用,我们提供Linux网络驱动程序,将网络接口导出到NetFPGA器件上的每个物理以太网端口上。这样可以让用户空间软件把网络数据包传输到器件上,并且读取设计中任何主机可视寄存器。
在硬件侧,OpenCPI为我们提供了无干扰、甚至多种数据流接口,而且每个接口都可以通过OpenCPI框架进行配置。此外,OpenCPI能够处理主机侧和硬件侧所有的缓存和PCIe事务处理,这样用户就能够集中精力进行特定应用开发,而不必处理器件通信的细节。
扩展接口与配置子系统
扩展接口子系统的目的是让用户通过连接第二块NetFPGA-10G板卡来增加端口密度,比如通过光学子卡来丰富网络接口特性,或者通过高速串行接口连接更多搜索组件,比如基于知识的处理器等。我们将FPGA上的20个GTX收发器取出,然后通过AC耦合传输线连接到两个高速接插件上。这些接插件是为诸如XAUI、PCIe、SATA和Infiniband这样的传输接口设计的,既可以通过匹配接插件直接连接到另一块板卡上,也可以通过电缆组件连接到另一块板卡上。每条传输线经测试双向传输速率均可达到6.5Gbps,从而为进出FPGA提供了一条额外的130Gbps数据路径。
举报
更多回帖
rotate(-90deg);
回复
相关问答
FPGA
赛灵思
如何
利用
FPGA
开发高性能
网络
安全处理
平台
?
2019-08-12
3433
华为
FPGA
加速
云服务器如何
加速
让硬件应用高效上云?
2019-10-22
3569
基于中间件的智能家电嵌入式
平台
2019-07-02
1374
FTDI
FPGA
平台
加速
基于
FPGA
的应用与制作
2019-07-03
2030
如何
利用
赛灵思28纳米工艺
加速
平台
开发?
2019-08-09
1897
如何
利用
视频套件
加速
FPGA
上的视频开发?
2021-04-30
754
基于中间件upnp的智能家电嵌入式开放
平台
2019-07-16
1787
如何
利用
片上高速
网络
创新地实现
FPGA
内部超高带宽逻辑互连?
2021-06-17
1135
FPGA
是如何实现30倍速度的云
加速
的?都
加速
了哪些东西?
2017-04-15
6015
FPGA
的
发展
现状如何?
2021-04-08
2168
发帖
登录/注册
20万+
工程师都在用,
免费
PCB检查工具
无需安装、支持浏览器和手机在线查看、实时共享
查看
点击登录
登录更多精彩功能!
首页
论坛版块
小组
免费开发板试用
ebook
直播
搜索
登录
×
20
完善资料,
赚取积分



 举报
举报