低密度奇偶校验(LowDensityParityCheck,LDPC)码是由Gallager博士在1962年首次提出来的,由于LDPC码的误码性能能够逼近香农限,因而在无线
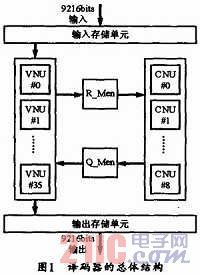
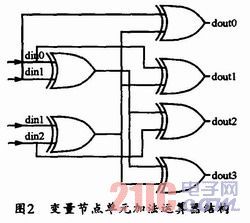
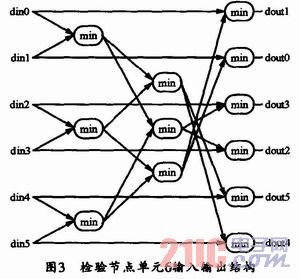
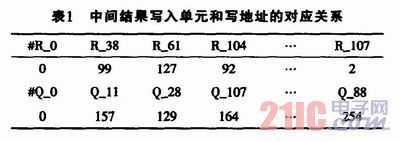
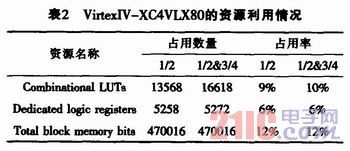
通信、卫星通信等领域都得到了较多应用。中国移动多媒体广播(CMMB)中使用的就是LDPC纠错编码。在CMMB标准中,LDPC码长为9216,可支持1/2和3/4两种码率。作者通过深入分析CMMB中LDPC码校验矩阵的特点,采用了一种合适的硬件实现结构,因而在保证译码器较高性能和较快译码速度的情况下,以较低的硬件资源实现了两种码率的复用。



 举报
举报