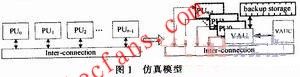
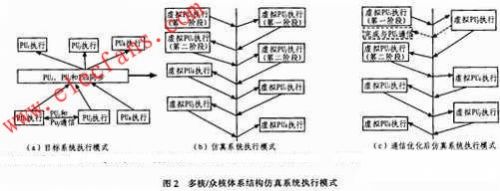
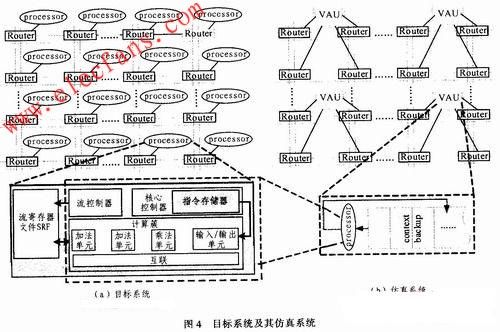
对称多核如SMP(Symmetry Multi-Processor)体系结构中,通常包含多个对称的处理器核或计算核心,这里统称为计算核。计算核占据了多核体系结构的主要硬件开销,且对称多核体系结构的硬件仿真平台FPGA资源消耗随计算核数目成线性增加。这里提出的对称多核体系结构FPGA仿真模型,解耦合计算核数目与系统硬件开销的线性关系,其核心设计思想是:在构建仿真系统时,使用一个与目标系统中单个计算核等同的处理单元,称为虚拟计算单元VAU(Virtual Arithmetic Unit)代替所有的对称计算核,通过分时复用VAU实现一个计算单元虚拟多个计算核的行为。



 举报
举报
 举报
举报
更多回帖


