计算复杂度评估
无论是依据每位周期数来评估,还是依据执行任务所需的存储空间来评估,这种Turbo码算法实现方法的计算负荷都是相对适中的。
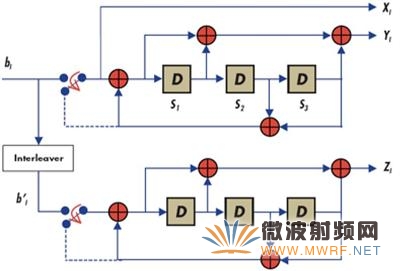
周期估算。如表3和表4所示,对交织数据执行拆包、交织和封包处理,每位需要4个周期。在表2所示的数据编码中,每位需要2.5个周期。这样,Turbo编码器总的周期成本为每位6.5个周期。请注意,这一估算没有考虑周期开销。假设每位的开销为1个周期,则执行Turbo编码,每位需要大约7.5个周期。借助这一高效的实现方法,我们在14.4 Mbps比特率时只需使用Blackfin处理器的108 MIPS,或者约18%的处理器MIPS。相比之下,简单编码方法则需要使用60%的处理器MIPS。由于Turbo编码器只消耗18%的MIPS,还剩下约82%的处理器MIPS,因此我们有充足的裕量来应对毫微微蜂窝基站的其它模块。
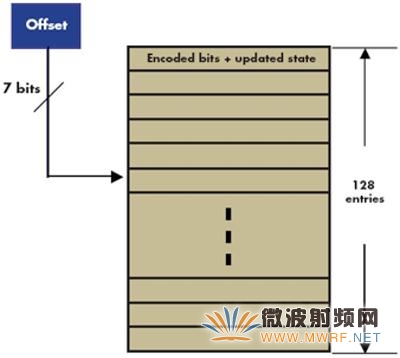
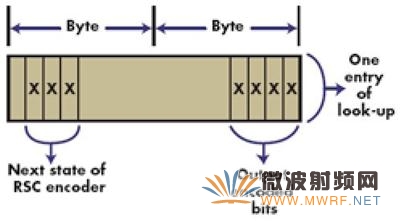
存储空间估算。利用查找表方法实现Turbo编码时,我们需要256字节的数据存储空间来存储预计算的编码信息。采用高效方法时,我们将各位封包成字节,因而存储交织数据所需的数据存储空间更小(仅1/8)。即时计算交织地址的方法非常昂贵,所以两种方法均需要数据存储器来存储交织地址。
利用预先计算的查找表,我们可以仅使用18%的处理器MIPS来执行Turbo编码;否则,使用简单方法则要消耗约60%的MIPS。这种高效方法使用256字节的存储器来存储查找表,所用的总存储空间少于简单方法所需的存储空间。
作者:Hazarathaiah Malepati和Yosi Stein,ADI半导体
参考文献
1. Berrou C, A Glavieux, and P. Thitimajshima,, "Near Shannon Limit Error-Correcting Coding: Turbo Codes," Proc IEEE Int. Conf. Commun., Geneva, Switzerland, pp.1064–1070, 1993.
2. 3GPP: 3rd Generation Partnership Project, "Technical Specification Group Radio Access Network, Multiplexing and Channel Coding," V8.0.0, 2007.
计算复杂度评估
无论是依据每位周期数来评估,还是依据执行任务所需的存储空间来评估,这种Turbo码算法实现方法的计算负荷都是相对适中的。
周期估算。如表3和表4所示,对交织数据执行拆包、交织和封包处理,每位需要4个周期。在表2所示的数据编码中,每位需要2.5个周期。这样,Turbo编码器总的周期成本为每位6.5个周期。请注意,这一估算没有考虑周期开销。假设每位的开销为1个周期,则执行Turbo编码,每位需要大约7.5个周期。借助这一高效的实现方法,我们在14.4 Mbps比特率时只需使用Blackfin处理器的108 MIPS,或者约18%的处理器MIPS。相比之下,简单编码方法则需要使用60%的处理器MIPS。由于Turbo编码器只消耗18%的MIPS,还剩下约82%的处理器MIPS,因此我们有充足的裕量来应对毫微微蜂窝基站的其它模块。
存储空间估算。利用查找表方法实现Turbo编码时,我们需要256字节的数据存储空间来存储预计算的编码信息。采用高效方法时,我们将各位封包成字节,因而存储交织数据所需的数据存储空间更小(仅1/8)。即时计算交织地址的方法非常昂贵,所以两种方法均需要数据存储器来存储交织地址。
利用预先计算的查找表,我们可以仅使用18%的处理器MIPS来执行Turbo编码;否则,使用简单方法则要消耗约60%的MIPS。这种高效方法使用256字节的存储器来存储查找表,所用的总存储空间少于简单方法所需的存储空间。
作者:Hazarathaiah Malepati和Yosi Stein,ADI半导体
参考文献
1. Berrou C, A Glavieux, and P. Thitimajshima,, "Near Shannon Limit Error-Correcting Coding: Turbo Codes," Proc IEEE Int. Conf. Commun., Geneva, Switzerland, pp.1064–1070, 1993.
2. 3GPP: 3rd Generation Partnership Project, "Technical Specification Group Radio Access Network, Multiplexing and Channel Coding," V8.0.0, 2007.

 举报
举报