与现有的其他
FPGA云平台相比,Catapult平台的最主要特点就是构建了一个遍布全球的FPGA资源池,并能对资源池中的FPGA硬件资源进行灵活的分配和使用。相比其他方案,这种对FPGA的池化有着巨大的优势。
首先,FPGA池化打破了CPU和FPGA的界限。在传统的FPGA使用模型中,FPGA往往作为硬件加速单元,用于卸载和加速原本在CPU上实现的软件功能,因此与CPU紧耦合,严重依赖于CPU的管理,同时与CPU泾渭分明。
在Catapult平台里,FPGA一跃成为“一等公民”,不再完全受限于CPU的管理。如下图右所示,在Catapult加速卡中,FPGA直接与数据中心网络的TOR交换机相连,而不需要通过CPU和网卡的转发,这使得同一数据中心、甚至不同数据中心里的FPGA可以直接通过高速网络互连和
通信,从而构成FPGA资源池。管理软件可以直接对FPGA资源进行划分,而无需通过与资源池中每个FPGA互连的CPU完成,从而实现了FPGA与CPU的有效解耦。
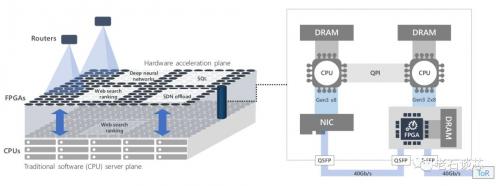
与CPU平行的FPGA资源池
第二,FPGA池化打破了单一FPGA的资源界限。从逻辑层面上看,Catapult的数据中心池化FPGA架构相当于在传统的基于CPU的计算层之上,增加了一层平行的FPGA计算资源,并可以独立的实现多种服务与应用的计算加速,如上图左所示。在微软当前的数据中心里,池化FPGA的数量级以十万记,而这些FPGA的通信延时只有大约十微秒左右。
对于人工智能应用,特别是基于深度学习的应用来说,很多应用场景对实时性有着严格的要求,例如搜索、语音识别等等。同时对于微软来说,它有着很多富文本的AI应用场景,例如网络搜索、语音到文本的转换、翻译与问答等。与传统CNN相比,这些富文本应用和模型对内存带宽有着更加严苛的需求。
如果结合“低延时”和“高带宽”这两点需求,传统的深度学习模型和硬件的通常解决方法是对神经网络进行剪枝和压缩,从而减少模型的大小,直到满足NPU芯片有限的硬件资源为止。然而,这种方法最主要的问题就是会对模型的精度和质量造成不可避免的损失,而且这些损失往往是不可修复的。
与之相比,Catapult平台里的FPGA资源可以看成是“无限”的,因此可以将一个大的DNN模型分解成若干小部分,每个小部分可以完整映射到单个FPGA上实现,然后各部分再通过高速数据中心网络互连。这样不仅保证了低延时与高带宽的性能要求,也保持了模型的完整性,不会造成精度和质量损失。
脑波项目:系统架构
脑波项目的主要目标,是利用Catapult的大规模FPGA基础设施,为没有硬件设计经验的用户提供深度神经网络的自动部署和硬件加速,同时满足系统和模型的实时性和低成本的要求。
为了实现这个目标,脑波项目提出了一个完整的软硬件解决方案,主要包含以下三点:
对已训练的DNN模型根据资源和需求进行自动区域划分的工具链;
对划分好的子模型进行FPGA和CPU映射的系统架构;
在FPGA上实现并优化的NPU软核和指令集。
下图展示了使用脑波项目进行DNN加速的完整流程。对于一个训练好的DNN模型,工具会首先将其表示为计算流图的形式,称为这个模型的“中间表示”(Intermediate Representa
tion - IR)。
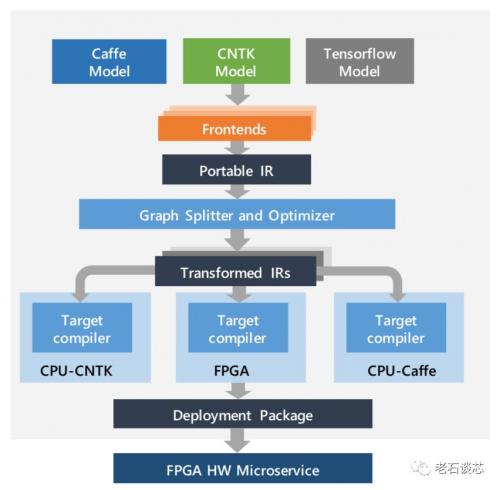
脑波项目DNN加速的完整流程
其中,图的节点表示张量运算,如矩阵乘法等,而连接节点的边表示不同运算之间的数据流,如下图所示。
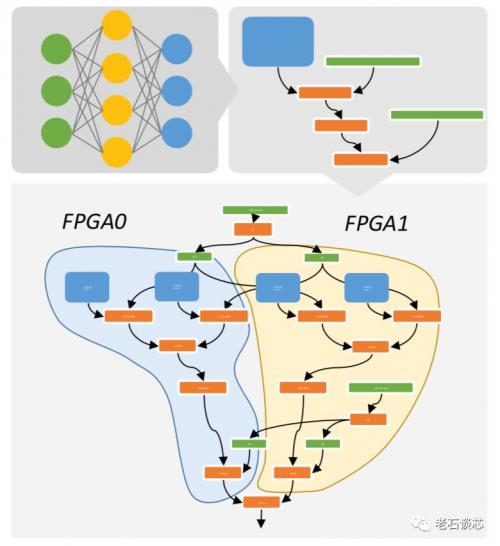
IR表示完成后,工具会继续将整张大图分解成若干小图,使得每个小图都可以完整映射到单个FPGA上实现。对于模型中可能存在的不适合在FPGA上实现的运算和操作,则可以映射到与FPGA相连的CPU上实现。这样就实现了基于Catapult架构的DNN异构加速系统。
在FPGA上进行具体的逻辑实现时,为了解决前文提到的“低延时”与“高带宽”两个关键性需求,脑波项目采用了两种主要的技术措施。
首先,完全弃用了板级DDR内存,全部数据存储都通过片上高速RAM完成。相比其他方案,不管使用ASIC还是FPGA,这一点对于单一芯片的方案都是不可能实现的。
在脑波项目所使用的英特尔Stratix 10 FPGA上,有着11721个512x40b的SRAM模块,相当于30MB的片上内存容量,以及在600MHz运行频率下35Tbps的等效带宽。这30MB片上内存对于DNN应用是完全不够的,但正是基于Catapult的超大规模FPGA的低延时互联,才使得在单一FPGA上十分有限的片上RAM能够组成看似“无限”的资源池,并极大的突破了困扰DNN加速应用已久的内存带宽限制。
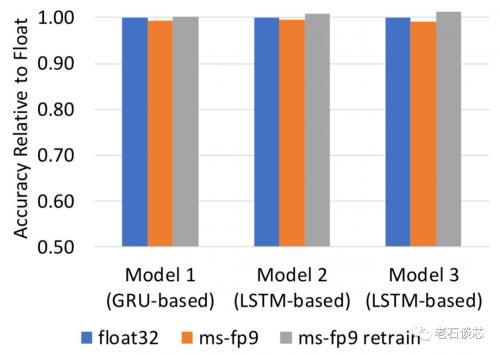
第二,脑波项目采用了自定义的窄精度数据位宽。这个其实也是DNN加速领域的常见方法。项目提出了8~9位的浮点数表达方式,称为ms-fp8和ms-fp9。与相同精度的定点数表达方式相比,这种表达需要的逻辑资源数量大致相同,但能够表达更广的动态范围和更高的精度。
与传统的32位浮点数相比,使用8~9位浮点表示的精度损失很小,如下图所示。值得注意的是,通过对模型的重新训练,就可以补偿这种方法带来的精度损失。
脑波项目的核心单元,是一款在FPGA上实现的软核NPU,及其对应的NPU指令集。这个软核NPU实质上是在高性能与高灵活性之间的一种折中。从宏观上看,DNN的硬件实现可以使用诸如CPU、GPU、FPGA或者ASIC等多种方式实现。在前文中讲过,CPU有着最高的灵活性,但性能不尽如人意;ASIC方案与之相反。而FPGA能够在性能和灵活性之间达到良好的平衡。
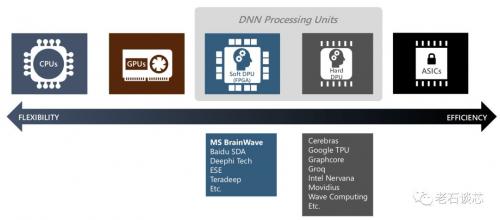
从微观上看,FPGA方案本身对于DNN的实现,既可以使用编写底层RTL的方式,对特定的网络结构进行针对性的优化;也可以采用高层次综合(HLS)的方法,通过高层语言对网络结构进行快速描述。
但是,前者需要丰富的FPGA硬件设计与开发经验,并伴随着很长的开发周期;而后者由于开发工具等限制,最终得到的硬件系统在性能上往往很难满足设计要求。
因此,微软采用了软核NPU与特定指令集的方式。这种方法一方面兼顾了性能,使硬件工程师可以对NPU的架构和实现方式进行进一步优化,另一方面兼顾了灵活性,使软件工程师可以通过指令集对DNN算法进行快速描述。
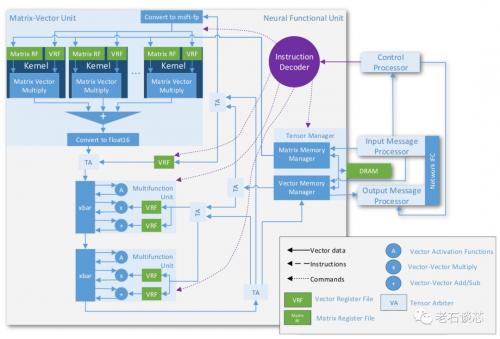
脑波NPU的架构图如下所示,NPU的核心是一个进行矩阵向量乘的算术单元MVU。它针对FPGA的底层硬件结构进行了深度优化,并采用了上文提到的“片上内存”和“低精度”的方法进一步提高系统性能。
NPU的最主要特点之一是采用了“超级SIMD”的指令集架构,这与GPU的SIMD指令集类似,但是NPU的一条指令可以生成超过一百万个运算,等效于在英特尔Stratix 10 FPGA上实现每个时钟周期13万次运算。
 脑波项目:性能提升
脑波项目:性能提升
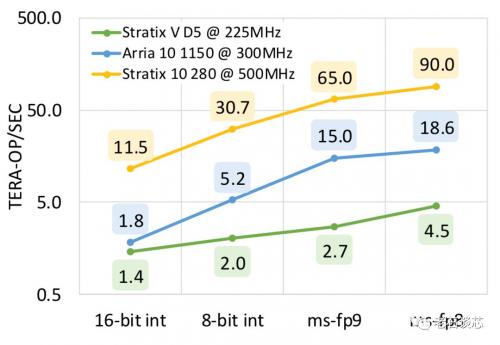
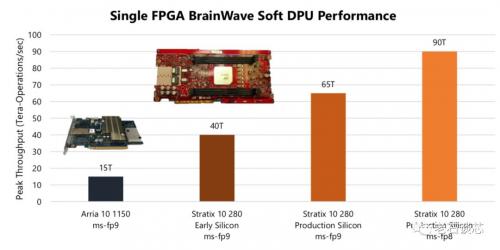
脑波NPU在不同FPGA上的峰值性能如下图所示,当使用ms-fp8精度时,脑波NPU在Stratix 10 FPGA上可以得到90 TFLOPS的峰值性能,这一数据也可以和现有的高端NPU芯片方案相媲美。
脑波项目还对微软的必应搜索中的Turing Prototype(TP1)和DeepScan两个DNN模型进行了加速试验。由于必应搜索的严格实时性要求,如果使用CPU实现这两种DNN模型,势必要对参数和运输量进行大规模削减,从而严重影响结果精度。相比之下,脑波方案可以实现超过十倍的模型规模,同时得到超过十倍的延时缩减。
在Stratix 10 FPGA的测试版产品上,当运行在300MHz的频率时可以得到的等效算力和峰值算力分别为39.5 TFLOPS和48 TFLOPS。预计在量产版的Stratix 10上,稳定运行频率将达到550MHz,从而再带来83%的性能提升,以期达到将近90 TFLOPS。同时,Stratix 10 FPGA的满载功耗约为125W,这意味着脑波项目可以达到720 GOPs/watt的峰值吞吐量。
 结语
结语
脑波项目充分利用了微软遍布全球数据中心的FPGA基础架构,使用FPGA解决了AI应用中“低延时”和“高带宽”两大痛点,并成功构建了基于软核NPU和自定义指令集的实时AI系统。
脑波项目的成功实践,再一次为业界使用FPGA作为AI加速器提供了崭新的思路和借鉴。老石相信,在人工智能时代,FPGA必将在更多应用领域得到更加广泛的使用。


