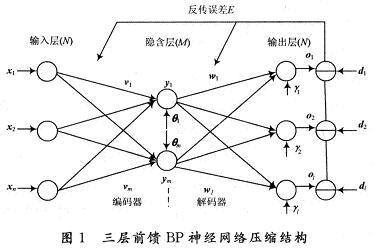
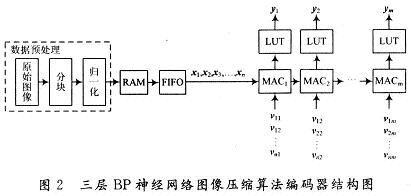
与传统的数字信号处理器DSP(Digital Signal Processor)相比,现场可编程门阵列(Field Programma-ble Gate Array,FPGA)在神经网络的实现上更具优势。DSP处理器在处理时采用指令顺序执行的方式,而且其数据位宽是固定的,因而资源的利用率不高,限制了处理器的数据吞吐量,还需要较大的存储空间。FPGA处理数据的方式是基于硬件的并行处理方式,即一个时钟周期内可并行完成多次运算,特别适合于神经网络的并行特点,而且它还可以根据设计要求配置硬件结构,例如根据实际需要,可灵活设计数据的位宽等。随着数字集成电路技术的飞速发展,FPGA芯片的处理能力得到了极大的提升,已经完全可以承担神经网络数据压缩处理的运算量和数据吞吐量。图像压缩是信息传输和存储系统的关键技术,然而我们该如何进行FPGA设计,以实现给定的功能已经成为神经网络应用的关键呢?

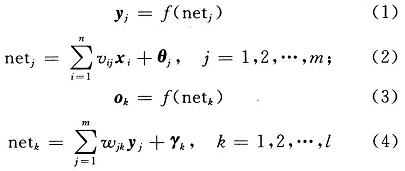
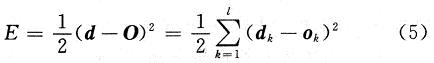

 举报
举报


 举报
举报
更多回帖


