综合技术
登录
直播中
丁峙昌
8年用户
162经验值
私信
关注
[问答]
应用响应时间的延迟问题怎么解决
开启该帖子的消息推送
DRAM
对于数据中心架构师而言,这似乎是一个简单的问题。对于从
电子
商务平台背后的数据库、搜索引擎中的大数据工具、突然流行的数据分析到科学代码的各种应用而言,应用响应时间的主要限制是存储延迟。与此同时,DRAM 的密度正在变得越来越高,而固态盘 (SSD) 则在变得越来越便宜。存储级内存 (SCM) 是一类新的内存设备,这类设备将在服务器卡中置入大量内存。那么为什么不将这些问题应用的所有数据都存储在内存中,从而完全消除磁盘甚至固态盘的延迟呢?
回帖
(2)
杨芳
2019-7-30 16:39:26
这个概念很适合数据中心工作负载的不断变化的需求。许多人对用户级别的响应时间变得越来越敏感,因为用户越来越倾向于在几秒延迟后放弃搜索、在线购物或内容浏览。随着控制系统(特别是自动驾驶汽车)中开始包含机器学习或数据分析功能,实时限制得以产生,这使得延迟问题变得更加紧迫。
与此同时,真正庞大的数据集也被纳入了网络角色。英特尔® 高级总工程师 David Cohen 表示:“大数据分析能力使得冷数据得以回暖。新的分析方法正在深入探究庞大的历史数据集,包括事务日志、分类账、遥测或源源不断的物联网 (IoT) 网络流,这些数据集过去只是难以理解的档案。开发人员希望分析在几秒内完成,而无需耗费数天。
因此将所有数据放在主内存中是一个好方法,这将可以推动创建出一整代新应用和平台以及一个新的类别名称:内存计算。(请注意,内存计算是指数据完全存储在内存中的应用,而非嵌入到内存子系统中的处理单元。)但强大的技术也会有弊端。若要消除弊端,需要重新思考内存组织和数据中心网络架构(图 1)。这使得内存计算不仅仅是一个编程决策,更是一项工程挑战。
首先我们来了解一下它的演变。
更靠近内核
人们对内存计算的最初反应是纷纷上马此项技术,好方法通常都是如此。争抢挤入扩展的服务器 DRAM 的数据集很快就超出了机架式服务器卡的几百 MB 的 DRAM 容量。
这迫使架构师仔细观察工作负载中的数据访问模式。在 map-reduce 工作负载中,每个服务器都有自己的数据块并且服务器没有什么必要访问不在其本地 DRAM 中的数据,这没有什么大问题。这种情况下的内存计算仅仅是指划分数据集,以便每个数据块适合一个服务器卡的 DRAM 并且持久储存在此处。大多数情况下都需要访问存储在 DRAM 中的工作集的其他工作负载也是如此。然而当工作集无法存储在 DRAM 中时,挑战就来了。
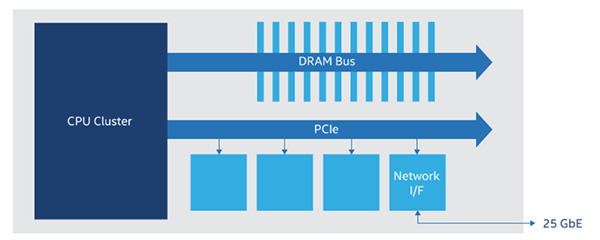
下一个演进步骤是使固态盘发挥作用。通过 PCIe 连接到 CPU 的服务器卡上的固态盘可以向卡中添加 1 到数 TB 的本地存储(图 2)。固态盘通常拥有用于隐藏其固有延迟的 DRAM 高速缓存,因此可以每秒生成数十万个随机读取操作,可能是写入操作数量的四分之一。通常它们会使用 NVMe 命令协议替代 PCIe,该协议适用于读写命令,而非模拟内存。
图 2.如今的服务器卡具有访问内存、存储和卡外资源的三种主要互连方案。
因此,当应用需要固态盘中的资源时,必须发出一个发送 NVMe 命令的系统调用,通过 PCIe 将来自固态盘的数据块传输到主内存 DRAM。管理程序可以隐藏这一进程,并使这些设备(其内部高速缓存可能有 30-40 微秒的延迟)在应用面前表现为非常缓慢的内存。依靠本地固态盘并不是真正的内存计算,只是对于应用而言看上去如此。
这一现实(特别是 40 微秒的延迟)增加了对下一个演进步骤 SCM的需求。这类内存的密度几乎与 NAND 闪存一样,但速度几乎与 DRAM 一样,可创建一个非常快速的固态盘,或以 DIMM 格式创建并直接插入服务器卡的 DRAM 总线。SCM 的当前备选选项也是非易失性的。这听起来很棒,但问题是这些技术实际上并没有以 DIMM 格式出现,所以目前它们只是另一种构建固态盘的方式。
如果我们确实获得 SCM DIMM,那么内存计算将会有很大提升,将 40 微秒的延迟缩短为 4 微秒左右。它们还会将服务器卡 DRAM 总线上的主内存容量从几百 MB 提升到 24 TB。现在我们有一个硬件平台,可以为实际数据集提供真正的内存计算。
这个概念很适合数据中心工作负载的不断变化的需求。许多人对用户级别的响应时间变得越来越敏感,因为用户越来越倾向于在几秒延迟后放弃搜索、在线购物或内容浏览。随着控制系统(特别是自动驾驶汽车)中开始包含机器学习或数据分析功能,实时限制得以产生,这使得延迟问题变得更加紧迫。
与此同时,真正庞大的数据集也被纳入了网络角色。英特尔® 高级总工程师 David Cohen 表示:“大数据分析能力使得冷数据得以回暖。新的分析方法正在深入探究庞大的历史数据集,包括事务日志、分类账、遥测或源源不断的物联网 (IoT) 网络流,这些数据集过去只是难以理解的档案。开发人员希望分析在几秒内完成,而无需耗费数天。
因此将所有数据放在主内存中是一个好方法,这将可以推动创建出一整代新应用和平台以及一个新的类别名称:内存计算。(请注意,内存计算是指数据完全存储在内存中的应用,而非嵌入到内存子系统中的处理单元。)但强大的技术也会有弊端。若要消除弊端,需要重新思考内存组织和数据中心网络架构(图 1)。这使得内存计算不仅仅是一个编程决策,更是一项工程挑战。
首先我们来了解一下它的演变。
更靠近内核
人们对内存计算的最初反应是纷纷上马此项技术,好方法通常都是如此。争抢挤入扩展的服务器 DRAM 的数据集很快就超出了机架式服务器卡的几百 MB 的 DRAM 容量。
这迫使架构师仔细观察工作负载中的数据访问模式。在 map-reduce 工作负载中,每个服务器都有自己的数据块并且服务器没有什么必要访问不在其本地 DRAM 中的数据,这没有什么大问题。这种情况下的内存计算仅仅是指划分数据集,以便每个数据块适合一个服务器卡的 DRAM 并且持久储存在此处。大多数情况下都需要访问存储在 DRAM 中的工作集的其他工作负载也是如此。然而当工作集无法存储在 DRAM 中时,挑战就来了。
下一个演进步骤是使固态盘发挥作用。通过 PCIe 连接到 CPU 的服务器卡上的固态盘可以向卡中添加 1 到数 TB 的本地存储(图 2)。固态盘通常拥有用于隐藏其固有延迟的 DRAM 高速缓存,因此可以每秒生成数十万个随机读取操作,可能是写入操作数量的四分之一。通常它们会使用 NVMe 命令协议替代 PCIe,该协议适用于读写命令,而非模拟内存。
图 2.如今的服务器卡具有访问内存、存储和卡外资源的三种主要互连方案。
因此,当应用需要固态盘中的资源时,必须发出一个发送 NVMe 命令的系统调用,通过 PCIe 将来自固态盘的数据块传输到主内存 DRAM。管理程序可以隐藏这一进程,并使这些设备(其内部高速缓存可能有 30-40 微秒的延迟)在应用面前表现为非常缓慢的内存。依靠本地固态盘并不是真正的内存计算,只是对于应用而言看上去如此。
这一现实(特别是 40 微秒的延迟)增加了对下一个演进步骤 SCM的需求。这类内存的密度几乎与 NAND 闪存一样,但速度几乎与 DRAM 一样,可创建一个非常快速的固态盘,或以 DIMM 格式创建并直接插入服务器卡的 DRAM 总线。SCM 的当前备选选项也是非易失性的。这听起来很棒,但问题是这些技术实际上并没有以 DIMM 格式出现,所以目前它们只是另一种构建固态盘的方式。
如果我们确实获得 SCM DIMM,那么内存计算将会有很大提升,将 40 微秒的延迟缩短为 4 微秒左右。它们还会将服务器卡 DRAM 总线上的主内存容量从几百 MB 提升到 24 TB。现在我们有一个硬件平台,可以为实际数据集提供真正的内存计算。
举报
钱铖
2019-7-30 16:39:40
扩展
但是,每个服务器卡上的大内存容量并不能解决所有问题。Cohen 指出,许多应用必须保存事务日志和检查点,即使在持久内存中运行也不例外。非易失性内存无法防止数据集受到漏洞或恶意攻击。这些可能会导致从服务器卡到存储池的短消息出现高频流量后台,从而给架顶式 (***) 网络带来严峻挑战。
同时,这些 10 或 25 Gbps 以太网 (GbE) 网络还面临着来自内存计算的挑战。有些数据中心架构师希望让服务器 CPU 获得比服务器卡中更多的内存。也许他们不想等待 SCM DIMM 出现。或者他们希望其应用的工作集增加到超过 SCM DIMM 所维持的 24 TB 容量。无论如何,他们正在推动对机架中其他服务器卡的固态盘和 DRAM 总线的远程直接内存访问 (RDMA)。事实上,他们希望所有 DIMM 在一个机架内,或许也希望所有固态盘也在一个机架内,以形成一个统一的虚拟内存。
用于这种 RDMA 事务的介质是内存区域网络。
网络
这一对服务器卡之外的内存进行访问和虚拟化的需求对机架内的网络有很大影响。对于内存引用,您希望让缓存缺失触发读取,直接访问另一个服务器卡上的 DRAM 或 SCM 页面。对于存储访问,您希望 NVMe 命令访问另一个卡上的 SCM DIMM 或固态盘,或一个存储卡上的巨大闪存池(仅为一堆闪存或 JBoF)。
您可以通过软件和现有 *** 网络做到这一点。使用管理程序代码找到所需的程序块,并且传输数据的 10 或 25 GbE 驱动程序将运行,但延迟可能在 50 微秒的范围之内。对许多应用而言,这是不可行的。分析师认为,如果延迟时间大于 10 微秒,CPU 应切换到另一个线程,而不是等待请求。除非应用有很多线程,否则任何长于 10 毫秒的延迟都将是性能问题。除了延迟问题之外,还存在带宽问题:一个高性能固态盘可能会使一个 25 GbE 网络饱和。
这些问题的解决方案需要机架内的多个变更层。
首先,您需要基于硬件的 RDMA。两端的网络接口都需要硬件 DMA,而不是每个以太网数据包由软件驱动程序进行组装,通过网络发送,由软件解压到缓冲区中,然后由软件移动到另一个位置以供应用使用。因此,数据可以从一个服务器卡上的内存或固态盘移动到另一个卡的内存中,且在移动过程中无需通过 CPU。
接下来,您需要确保这些延迟关键型 RDMA 传输不会被堵塞。我们必须将 RDMA 流量分离到自己的专用网络上,或者我们必须为 *** 以太网创建优先方案。
最好有一个连接服务器卡 PCIe 总线的专用点到点 RDMA 网络。这将使私有网络的全部收发器带宽用于 RDMA 传输,并可以将延迟缩短到 2 微秒的范围之内,几乎接近于将机架上的所有 DRAM 和 SCM 都放置在同一 DRAM 总线中。
但出于各种原因,例如本已非常拥挤的机架、额外的成本以及对单一数据源的依赖,大多数数据中心运营商都不喜欢专用网络,甚至在机架内也不喜欢使用。因此,点到点 RDMA 可能仅限于高性能计算机和一些具有特别苛刻工作负载的私有数据中心。这使得 *** 网络在大多数云和数据中心配置中承载流量。
*** 以太网拥有 RDMA 所需的所有连接。在 25 Gbps 时,它具有足够的带宽来处理适量的 RDMA 活动。现在市面上有些高质量网络芯片的最低延迟约为 5 微秒,基本上可以称得上足够快了。vanilla 25 GbE 不具备良好的延迟上限。
这就是融合以太网发挥作用的地方。CE 为以太网流量添加了优先级,允许 *** 交换机将 RDMA 流量优先于其他任何内容,包括那些来自内存计算的高频短消息以及关于一些新鲜事物的源源不断的流量。现在我们有了 RDMA over CE (RoCE),其发音类似于知名的电影拳击手。RoCE 为内存到内存传输以及内存和远程固态盘之间的 NVMe 事务提供了合理的延迟(图 3)。
图 3.内存到内存 RoCE 事务。
但 RoCE 不是***的。若要实现我们所说的延迟类型,则需要支持 RDMA 和硬件优先级排序的 RoCE 网络适配器,以及能够进行低延迟 CE 切换的 *** 交换机,其中可能包括一些非常大的快速缓冲区,因为队列变得非常大。队列溢出导致的丢包在这里行不通。
那么路线图是什么样子的呢?如今我们仍在从传统 10 GbE *** 网络向 25 GbE 转型,40 GbE 即将变为现实。RoCE 仍然不常见,但有人在专用芯片和高端 FPGA 中实施 RoCE 网络适配器。
未来,随着 SCM DIMM 的广泛使用,我们可以设想一下 *** 网络中的另一个演进步骤从数据包优先级划分过渡到完全软件定义的配置。在如今的世界中,巨大的数据集将是相对静态的,分散在持久性 DIMM 中,并且在某些情况下,仍搭接在机架内的固态盘上。应用和虚拟连接将根据其数据访问需求进行。用于分割数据集的分区边界从服务器卡移动到机架,前者拥有数 TB 存储,后者可能有 720 TB 的内存容量作为单个虚拟内存池。
然后,随着数据集进入 PB 范围,注意力将转移到数据中心脊柱网络上。我们可以重新开始讨论延迟了。
扩展
但是,每个服务器卡上的大内存容量并不能解决所有问题。Cohen 指出,许多应用必须保存事务日志和检查点,即使在持久内存中运行也不例外。非易失性内存无法防止数据集受到漏洞或恶意攻击。这些可能会导致从服务器卡到存储池的短消息出现高频流量后台,从而给架顶式 (***) 网络带来严峻挑战。
同时,这些 10 或 25 Gbps 以太网 (GbE) 网络还面临着来自内存计算的挑战。有些数据中心架构师希望让服务器 CPU 获得比服务器卡中更多的内存。也许他们不想等待 SCM DIMM 出现。或者他们希望其应用的工作集增加到超过 SCM DIMM 所维持的 24 TB 容量。无论如何,他们正在推动对机架中其他服务器卡的固态盘和 DRAM 总线的远程直接内存访问 (RDMA)。事实上,他们希望所有 DIMM 在一个机架内,或许也希望所有固态盘也在一个机架内,以形成一个统一的虚拟内存。
用于这种 RDMA 事务的介质是内存区域网络。
网络
这一对服务器卡之外的内存进行访问和虚拟化的需求对机架内的网络有很大影响。对于内存引用,您希望让缓存缺失触发读取,直接访问另一个服务器卡上的 DRAM 或 SCM 页面。对于存储访问,您希望 NVMe 命令访问另一个卡上的 SCM DIMM 或固态盘,或一个存储卡上的巨大闪存池(仅为一堆闪存或 JBoF)。
您可以通过软件和现有 *** 网络做到这一点。使用管理程序代码找到所需的程序块,并且传输数据的 10 或 25 GbE 驱动程序将运行,但延迟可能在 50 微秒的范围之内。对许多应用而言,这是不可行的。分析师认为,如果延迟时间大于 10 微秒,CPU 应切换到另一个线程,而不是等待请求。除非应用有很多线程,否则任何长于 10 毫秒的延迟都将是性能问题。除了延迟问题之外,还存在带宽问题:一个高性能固态盘可能会使一个 25 GbE 网络饱和。
这些问题的解决方案需要机架内的多个变更层。
首先,您需要基于硬件的 RDMA。两端的网络接口都需要硬件 DMA,而不是每个以太网数据包由软件驱动程序进行组装,通过网络发送,由软件解压到缓冲区中,然后由软件移动到另一个位置以供应用使用。因此,数据可以从一个服务器卡上的内存或固态盘移动到另一个卡的内存中,且在移动过程中无需通过 CPU。
接下来,您需要确保这些延迟关键型 RDMA 传输不会被堵塞。我们必须将 RDMA 流量分离到自己的专用网络上,或者我们必须为 *** 以太网创建优先方案。
最好有一个连接服务器卡 PCIe 总线的专用点到点 RDMA 网络。这将使私有网络的全部收发器带宽用于 RDMA 传输,并可以将延迟缩短到 2 微秒的范围之内,几乎接近于将机架上的所有 DRAM 和 SCM 都放置在同一 DRAM 总线中。
但出于各种原因,例如本已非常拥挤的机架、额外的成本以及对单一数据源的依赖,大多数数据中心运营商都不喜欢专用网络,甚至在机架内也不喜欢使用。因此,点到点 RDMA 可能仅限于高性能计算机和一些具有特别苛刻工作负载的私有数据中心。这使得 *** 网络在大多数云和数据中心配置中承载流量。
*** 以太网拥有 RDMA 所需的所有连接。在 25 Gbps 时,它具有足够的带宽来处理适量的 RDMA 活动。现在市面上有些高质量网络芯片的最低延迟约为 5 微秒,基本上可以称得上足够快了。vanilla 25 GbE 不具备良好的延迟上限。
这就是融合以太网发挥作用的地方。CE 为以太网流量添加了优先级,允许 *** 交换机将 RDMA 流量优先于其他任何内容,包括那些来自内存计算的高频短消息以及关于一些新鲜事物的源源不断的流量。现在我们有了 RDMA over CE (RoCE),其发音类似于知名的电影拳击手。RoCE 为内存到内存传输以及内存和远程固态盘之间的 NVMe 事务提供了合理的延迟(图 3)。
图 3.内存到内存 RoCE 事务。
但 RoCE 不是***的。若要实现我们所说的延迟类型,则需要支持 RDMA 和硬件优先级排序的 RoCE 网络适配器,以及能够进行低延迟 CE 切换的 *** 交换机,其中可能包括一些非常大的快速缓冲区,因为队列变得非常大。队列溢出导致的丢包在这里行不通。
那么路线图是什么样子的呢?如今我们仍在从传统 10 GbE *** 网络向 25 GbE 转型,40 GbE 即将变为现实。RoCE 仍然不常见,但有人在专用芯片和高端 FPGA 中实施 RoCE 网络适配器。
未来,随着 SCM DIMM 的广泛使用,我们可以设想一下 *** 网络中的另一个演进步骤从数据包优先级划分过渡到完全软件定义的配置。在如今的世界中,巨大的数据集将是相对静态的,分散在持久性 DIMM 中,并且在某些情况下,仍搭接在机架内的固态盘上。应用和虚拟连接将根据其数据访问需求进行。用于分割数据集的分区边界从服务器卡移动到机架,前者拥有数 TB 存储,后者可能有 720 TB 的内存容量作为单个虚拟内存池。
然后,随着数据集进入 PB 范围,注意力将转移到数据中心脊柱网络上。我们可以重新开始讨论延迟了。
举报
更多回帖
rotate(-90deg);
回复
相关问答
DRAM
DLPC3479 RUN ONCE的命令的
响应时间
怎么计算,具体为多少
时间
?
2025-02-18
284
关于伺服的采样周期、循环
时间
、
响应时间
、
响应
频率和带宽不看肯定后悔
2021-10-09
4589
请问AD8367增益步进
响应时间
是多少?
2018-10-01
2993
刚买的的显示面板,
响应时间
看不懂。
2014-04-03
4843
RL串联电路的
响应时间
怎么计算
2017-01-20
4353
怎么缩短freemodbus组件作为从机的
响应时间
呢?
2023-04-14
1383
运算放大器输出对输入的
延迟时间
如何准确计算?
2024-08-15
1015
请问AD9144输出
响应时间
?
2018-08-03
2870
SAR ADC
响应时间
实现迅速
响应
、快速控制的方法
2018-09-12
2218
请问nuc972上跑linux,如何降低串口的
响应时间
?
2023-06-27
483
发帖
登录/注册
20万+
工程师都在用,
免费
PCB检查工具
无需安装、支持浏览器和手机在线查看、实时共享
查看
点击登录
登录更多精彩功能!
首页
论坛版块
小组
免费开发板试用
ebook
直播
搜索
登录
×
20
完善资料,
赚取积分


 举报
举报
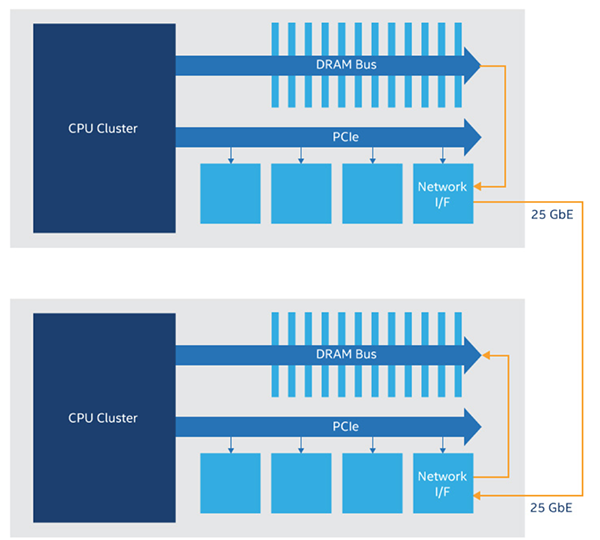 图 3.内存到内存 RoCE 事务。
举报
图 3.内存到内存 RoCE 事务。
举报



