Protel|AD|DXP论坛
登录
直播中
cooldog123pp
15年用户
5945经验值
擅长:可编程逻辑 嵌入式技术 控制/MCU RF/无线
私信
关注
[讨论]
【AD新闻】AI时代,一美元能够买到多强的算力?
新闻
时代
当真正需要在嵌入式终端设备中使用AI技术时,客户的诉求更多的集中在功耗、响应时间、成本等方面,对性能的无尽追求反而不是重点,这和很多人之前的预想并不一致。花一美元或一瓦电能买到多强的算力?
算法、数据和算力,并称为新AI时代三大驱动力。如何在追求更好性能的同时实现低功耗、低延迟和低成本,逐渐成为摆在所有AI从业者面前的艰巨挑战之一。日前,深鉴科技ASIC副总裁陈忠民应邀在“2018人工智能与
半导体
技术国际
论坛
”发表演讲就指出:当真正需要在嵌入式终端设备中使用AI技术时,客户的诉求更多的集中在功耗、响应时间、成本等方面,对性能的无尽追求反而不是重点,这和很多人之前的预想并不一致。”他提出客户最切实的需求是:花一美元或一瓦电能买到多强的算力?
如何解决当下面临的算力与功耗比的困境,深鉴科技本次演讲主题《人工智能芯片设计与应用:软硬件协同》提出新的思路。而会后陈忠民与《
电子
工程专辑》就如何突破AI芯片的算力与功耗的限制进行更加深入的对谈。表明这是两种很难调和的矛盾。深鉴科技研发团队为此进行了深入分析,试图解开困扰当前AI运算的谜团。
算力与功耗,真的难以兼得?
在接受《电子工程专辑》的电话采访时,陈忠民提及:随着海量数据的爆炸式增长与摩尔定律的逐渐放缓,可以看到像英伟达、英特尔、微软、谷歌这样的行业巨头纷纷推出了定制化专用AI芯片。尽管实现方式不同,但无论是选择
FPGA
还是ASIC,都在向业界传递一个明确的信号:即整个AI运算今后将会从通用计算平台走向定制化计算平台。追求更好性能,兼顾低功耗、低延迟和低成本将会是未来的主流趋势。
图1
图1中,很多硬件平台都展示了自身所具备的强大算力,然而当用户在真正运行一个应用时,却发现由于内存带宽的限制和架构的限制,依然不能将所有的AI运算单元填满,从而导致计算硬件的计算效率低下。以谷歌第一代TPU为例,其平均硬件乘法阵列使用率只有28%,这意味着72%的硬件在大部分时间内是没有任何事情可以做的。
另一方面,在设计AI平台的时候,大量运算引擎所带来的能量消耗是不可忽视的。
图2
图2表明,如果将完成16位整数加法能量消耗定义为1,那么将32比特的数据从DDR内存传输到芯片中,就将花费1万倍的能量消耗。因此,过大的访问带宽将会直接导致AI芯片功耗高居不下。
问题找到了,接下来该如何提升计算效率、降低功耗?陈忠民表示深鉴经过多次研究,总结出三条路径:首先,优化计算引擎,增加计算并行度;其次,优化访存系统;第三,利用神经网络稀疏性,实现软硬件协同设计。
Yann LeCun教授在IBM 45nm芯片上采用NeuFlow新架构为例,新架构使得芯片性能直接上升到了1.2T,这比传统CPU高出约100倍,比V6 FPGA实现的NeuFlow高出8倍,说明当架构设计得到改进后,更多的并行运算单元的确能够提升性能,让所有的硬件数据得到充分的运算。
“如果我打算构建一个8位乘法器,或是一个浮点16位乘法器,在每一代工艺节点下,是不是就一定会有天然的物理极限?要消耗多少晶体管才能实现一个16比特的乘法是一个定数”陈忠民说。一个有趣的事实是,早期之所以要在硬件和算法之间画出一道明显的界限,是因为处理器设计人员永远不知道将来要运行一个怎样的程序,是一个数据库应用还是一个网页显示?所以最简单的方法就是把接口标准化,这样,软件工程师透过编译器就可以将程序变成标准的硬件指令去执行。然而到了AI时代,每一个神经网络要做什么,设计人员都非常清楚,那么硬件就可以想办法实现与软件的配合,突破摩尔定律限制,做出兼具高性能与低功耗的产品。
软硬件协同优化
作为一家专注于提供从算法压缩、到软件/硬件、再到系统的完整解决方案的新锐AI公司,深鉴科技一直试图通过核心的深度压缩技术优化算法,结合自有深度学习底层架构—亚里士多德架构和笛卡尔架构,实现算法和硬件的协同优化,促进嵌入式端与云端的推理平台更加高效、便捷、经济。
深鉴科技联合创始人韩松博士是世界上首位提出利用稀疏性和模型量化来压缩运算量的科学家。简单来说,就是当拿到一个浮点32位或者浮点16位的模型之后,由于稀疏性的存在,完全可以将那些对结果没有影响的运算从神经网络中剪除,这样就能在减少运算量的同时保持整个网络的精度。对于现在的卷积神经网络来说,也没有必要通过运行浮点16/32位才能保证足够的精度,很多整数运算在某些网络层上已经可以实现。因此通过量化的方法,将一些浮点数转化为定点数运算,比如将16位浮点加运算转化为16位整数加运算时,能量消耗就会下降87.5%。
采访中,陈忠民将深鉴科技软硬件协同优化思路归结为“一句话”:软件定义硬件架构,而高效的硬件架构定义软件的组织方式。这种优化需要实现“三个目标”:第一,要在有限的资源下实现尽可能高的峰值性能;第二,需要优化硬件的微结构和编译工具来提升整体计算效率;第三,所有工作都不能破坏模型的精度。
然而“知易行难”,要做到这三点并不容易。
图3
图3是他向记者展示的不同计算特质的硬件架构,可以看到,一个标准的CNN网络里会包括一些共通的层,比如卷积层和全连接层。卷积层进行的是密集型计算,消耗的带宽有限,如果并行化能力突出,就可以用更多的计算单元来获得更好的卷积层性能;对全连接层而言,计算能力会被访存的带宽所限制,因此设计者需要思考为FC层所付出的硬件代价是什么?要怎样去构建硬件结构?等关键问题。
此外,一个众所周知的事实是,AI算法始终处于持续进化状态,即便是在同一个算法内部,仍然存在多种不同的算子。这势必要求设计者在硬件设计结构上时刻保持前瞻性分析,了解最新的算法趋势,平衡不同算子间的效率,深刻剖析整个网络里每一层的硬件需求,并借此设计出一个合理的、高效的硬件架构。
“针对这些不同的方法论,我们采取了很多应对策略。”陈忠民解释说,在整个硬件设计中,深鉴科技一直在追寻低比特量化的运算,同时要把运算单元整体充分调动起来,继而在编译器层面对神经网络数据结构做了很多优化,开发了自己的编译工具。在保持在模型精度不变的情况下将网络压缩降低运算量。
揭开“听涛”SoC的神秘面纱
今年上半年,深鉴科技将落实芯片计划,正式发布基于自主研发的人工智能处理器核心DPU 的“听涛”系列 SoC。资料显示,该DPU属于卷积神经网络加速器,能够实现高效地图像检测、识别、分类等AI应用。早前在该架构基础之上,深鉴科技做出了第一代FPGA产品,已经在摄像头市场实现了批量出货。
DPU计算核心采用全流水设计结构设计,内部集成了大量的卷积运算器、加法器、非线性等运算单元。高效率的架构设计会确保每一个运算单元都能够被充分的调动起来。像VGG16比较重的应用中,深鉴科技DPU的运算器利用率可以达到85%,对主流算法可以达到50%以上,功耗方面则大大低于竞争对手的产品。
陈忠民对记者说,在实际的客户拜访中,他注意到这样一个现象,即某些行业客户有自己偏爱的算法。深鉴科技就在自己开发的DNNDK工具链中毫无保留地加入了自动网络压缩和自动编译,任何一家客户的算法在DNNDK编译的过程中将自动完成网络的压缩,将浮点32位网络压缩成定点8位的运算网络,从而实现网络运算量的降低。客户甚至只用了50行代码就可以实现了一个Resnet 50的算法结构,极为便捷。
图4
在论坛现场,陈忠民展示了DNNDK在SSD算法上的结果。如图4,蓝色表示运算量,灰色表示运算精度。可以看到,在SSD算法上经过了若干轮迭代的压缩之后,整个运算量压缩从120降到了11.5,只有原来网络的1/10,同时基本保持了整个运算模型的精度没有变化。据此,陈忠民认为深度压缩可以使网络计算量变的更少,实现轻量化AI的运算。
相比现有FPGA产品的较高功耗,将于年中交付的“听涛”SoC产品的预期功耗约为3瓦,峰值算力4TOPS。考虑到网络压缩部分,等效的算力应该再扩大5-10倍。当下嵌入式领域的AI芯片中,无论是FPGA还是GPU,都很难越过每瓦1TOPs能效比,而听涛将会超过这条能效比的红线。
“我们希望通过自身在神经网络压缩以及先进芯片设计技术方面的经验,能够帮助客户得到更好的AI应用体验。他们完全不必关心使用何种硬件,只需要根据自己的性能和功耗需求选择适合的硬件平台即可。”这是陈忠民,也是深鉴科技对客户,也是对AI芯片未来的期望。
更多回帖
rotate(-90deg);
回复
相关帖子
新闻
时代
大模型
时代
的
算
力
需求
506
请问,智能座便器的各种配件哪里
能够买到
?
2492
开启
AI
算
力
芯
时代
592
算
力
大会2023 | 华为星河
AI
网络,高运力释放
AI
时代
高
算
力
1024
超
算
和
AI
怎么在智能
时代
算
力
突围
3408
立足
算
力
,聚焦
AI
!顺网科技全面走进
AI
智
算
时代
447
一
图看懂星河
AI
数据中心网络,全面释放
AI
时代
算
力
715
走进芯
时代
:
AI
算
力
GPU行业深度报告
1109
英伟达「黄氏定律」让未来的
AI
算
力
每年
能够
提升
一
倍
3001
AIGC
时代
和大模型对
算
力
的影响
1030
发帖
登录/注册
20万+
工程师都在用,
免费
PCB检查工具
无需安装、支持浏览器和手机在线查看、实时共享
查看
点击登录
登录更多精彩功能!
首页
论坛版块
小组
免费开发板试用
ebook
直播
搜索
登录
×
20
完善资料,
赚取积分
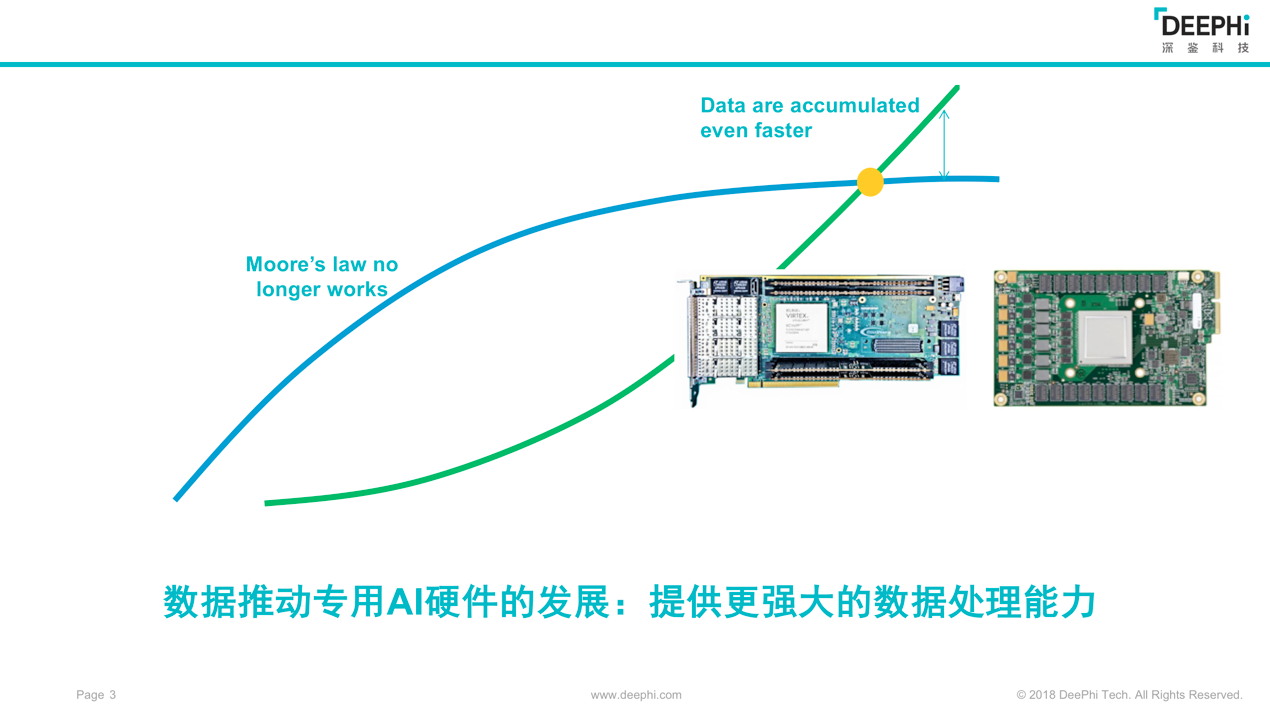 图1
图1 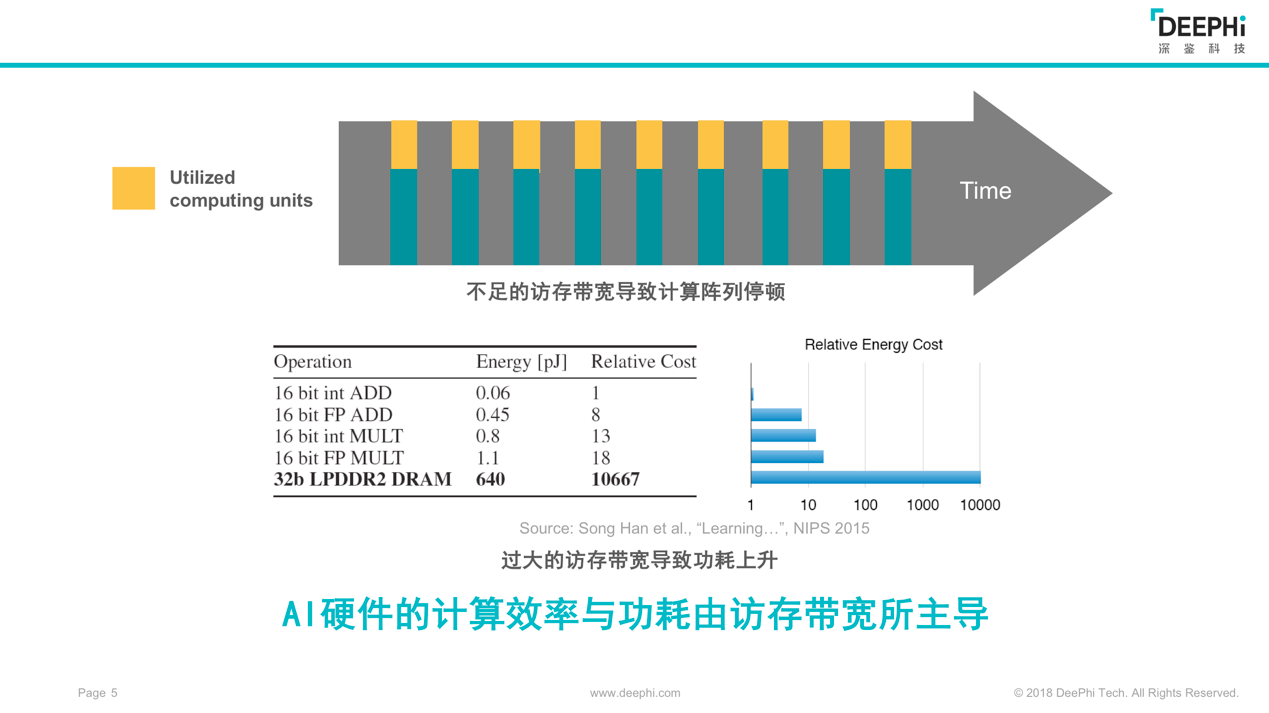 图2
图2 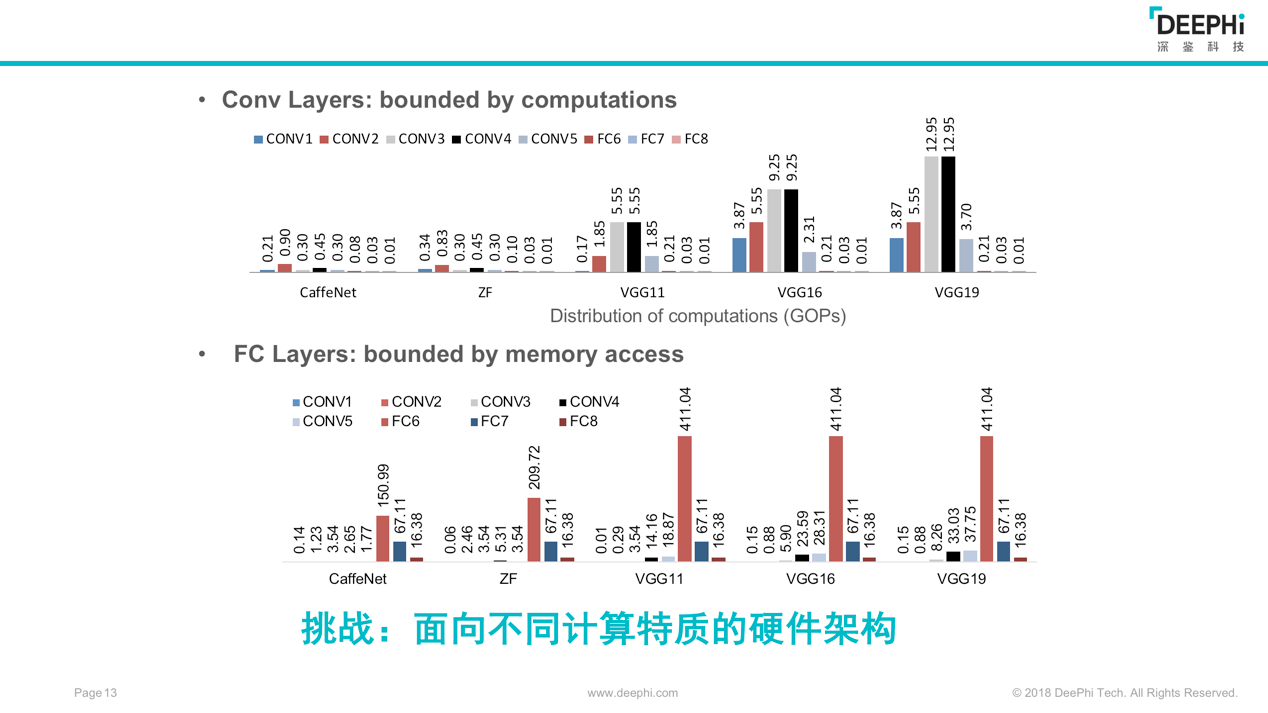 图3
图3 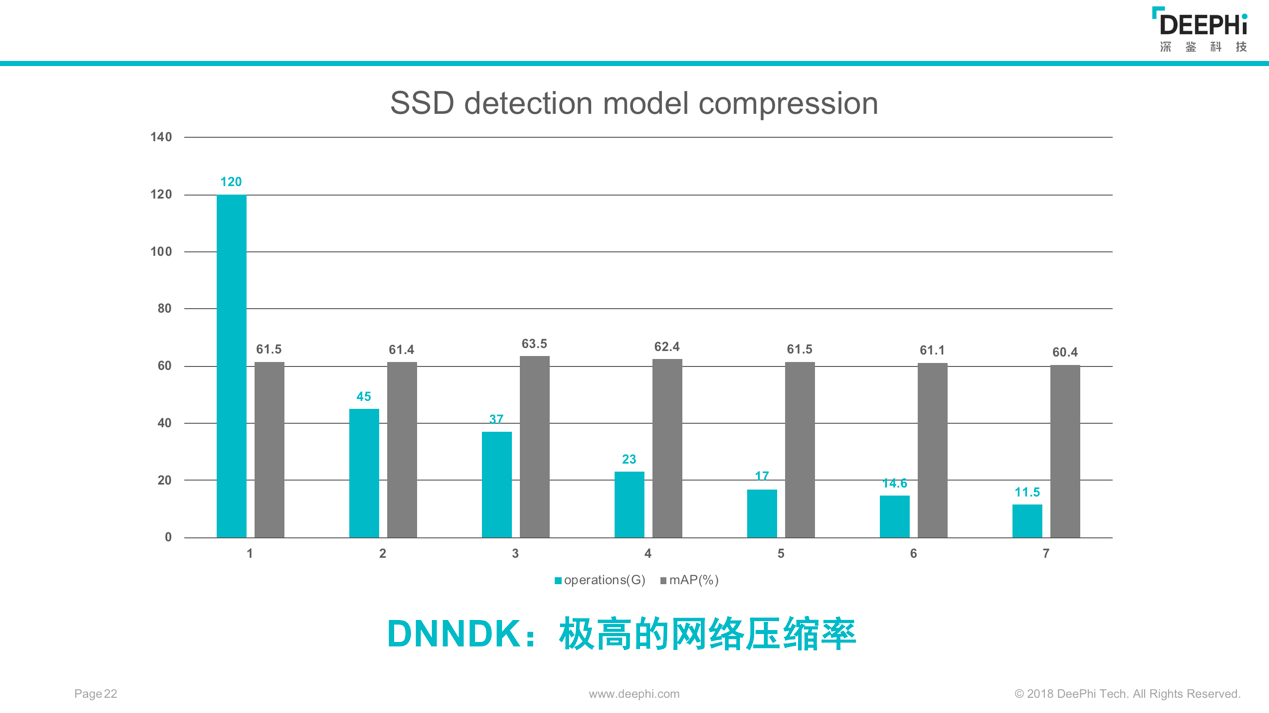 图4
图4 

