11月2日,云效第三期Work Like Alibaba系列直播开启,阿里巴巴研发效能事业部云效技术专家何卫龙,分享了《测试数据中心-互联网模式下新型的数据准备引擎》,主要解决测试过程中数据准备困难,以及如何提升数据准备效率的思路和方法。
主播简介
何卫龙:阿里巴巴技术专家。一直从事软件开发测试及系统架构设计工作,对测试工具平台的开发架构有一定的经验。目前是云效持续集成平台Amon、测试用例管理系统pivot和测试数据中心databank的技术负责人,主要负责平台的技术规划和产品建设。在此期间,发表过技术专利多篇。
内容大纲
本次分享,分四个部分:
介绍云效的项目开发测试流程:在此流程中,哪些阶段会用到测试数据,以及数据准备的重要性。
传统数据准备现状:为什么数据准备会这么难,准备一次数据为什么会这么耗时,我们是否可以通过工具平台来改变现状,让我们的数据准备变的easy。
重点介绍测试数据中心:通过理念、产品架构以及核心功能点的介绍,让大家了解产品以及使用方式,利用云效平台来解决传统数据准备的问题。
个人对未来测试数据中心的展望。
项目流程
首先,我们看一下整个项目的流程。从创建需求开始,经过需求分析、设计,然后形成一个完整的项目,开发负责人拉取代码分支,编写代码,在此过程中,开发会写一些单元测试,来确保新开发的功能是ok的。然后会打包编译、部署环境,开发同学自测之后,测试同学介入进行系统测试,其中包含功能、接口、UI自动化测试。系统测试以后,会进入项目集成测试,是把主干分支合并到当前分支后部署环境测试,这个阶段主要是自动化用例进行回归,所以速度很快,如果自动化用例没有维护好,那就另说,最后大功告成,我们就可以提测发布我们的项目了。整个流程梳理下来,我们看看哪些环节是需要用到测试数据的?
显而易见,比如我们的单测集成阶段,开发同学写的单元测试,前置条件中,就会用到数据初始化,系统测试阶段那就更不用说了,手工测试、接口自动化测试、UI自动化测试以及性能测试,都会使用到测试数据构造。如果测试数据准备不充分,或者有些数据很难准备,不仅会增加测试时间,导致项目延期,而且会影响测试结果的准确性,所以数据准备就变的尤为关键。
传统数据准备现状
目前数据准备,一般都是由业务逻辑很熟悉的测试人员来操作的,新人或者刚上手个把月的测试,准备起来难度会很大,容易出错。准备数据会用到大量的脚本,由于业务经常变动,为了适应变化,我们需要修改相应的脚本,脚本里面的逻辑就会变的很复杂,因此维护起来很困难。有些数据要通过手工和自动化工具联合创建,流程长,错误率极高。
因此,我总结了三点传统数据准备难的原因:
数据准备存在这么多的问题,但是这些测试数据在整个测试过程中又十分重要,大部分数据由于项目结束,就被抛弃了,非常可惜。因此,我们能否有一个工具平台来做支撑,把数据准备的经验和复杂的流程沉淀下来,转化成可以操作的数据内容,让一个普通测试,甚至开发人员都能自己构造数据。
测试数据中心
基于数据准备存在的问题,云效测试数据中心应运而生。云效测试数据中心的理念可以用四个关键词概括:低门槛、稳定性、透明化、灵活性。
低门槛
让一个测试小白都能自己造数据,他只要知道自己想要什么数据,然后在平台上面搜索数据关键字,填写必要入参,点击执行,就可以构造出数据。
稳定性
为接口、UI等自动化平台提供测试数据,减少自动化步骤,提升自动化的成功率。
以录制UI自动化为例,我们录制一个淘宝下订单的功能,会包含如下步骤:账号登录、页面搜索、点击进入、添加购物车、支付以及查询订单,对应的UI录制会有20多步,链路比较长,出错的几率也比较大。
如果通过测试数据中心构造数据,可以省去像页面搜索、添加购物车等操作步骤,可以缩短到10步以内,只需关注我们下单的流程。这样自动化脚本会更加稳定而且易维护。
透明化
有了测试数据平台以后,我们制作的数据内容和执行情况都能一目了然,大家对相同功能的数据构造就可以重复使用,方便我们对数据的维护和管理。同时把之前线下的操作全都迁移到线上来,数据透明化和线上化,规范我们的整个流程。
灵活性
由于数据构造需要传入的参数是五花八门的,各种数据形式都有,没有一种固定的方式,而且构造数据可能会在多套环境里面执行,因此,为了提升数据的复用性,我们支持在数据构造前选择环境参数,方便用户使用,同时支持用户自定义参数。另外,对于比较复杂的数据构造,我们支持组合数据的形式,化复杂为简单。
测试数据中心产品视图
我们常用的测试数据中心功能有六块:包括我的配置单、Sql助手、参数管理、我的收藏夹以及配置单列表、执行历史。
配置单是测试数据中心构造数据的基本单元,一个配置单的创建可能需要sql助手帮我们产生sql语句,这样解决用户由于书写不规范的sql导致的执行失败问题,然后通过参数管理抽象出配置单所需要的参数,这样一个配置单就构造好了。如果你觉得某个配置单自己会经常用到,可以在配置单列表页面,点击添加收藏夹,就可以在我的收藏夹页面看到添加的配置单。每次配置单执行都会产生一条执行记录,因此你可以在执行历史页面查看配置单历次的执行记录。
配置单好了之后,我们看下是怎么生成数据的?生成数据关键的一环是需要用到插件容器,每个配置单的执行都会调用插件容器,我们的插件容器,可以理解为一个agent,测试数据中心下发任务到agent,有agent来执行配置单,然后返回执行结果,我们的插件是可以分布式执行的,而且可以横向扩展,因此支持大规模的任务执行,同时可以即插即用,非常方便。
目前测试数据中心支持的插件有:mysql、oracle、sql server,这三种是数据库操作比较常用的。linux和windows的远程命令执行,驱动脚本生成数据,同时我们支持使用MongoDB、redis的操作命令直接构建数据,dds是蚂蚁分布式数据源服务,支持分库分表操作,tddl是淘系的分库分表,最后是常用的http服务。
云效数据生成插件是可以组合使用的,灵活多变。后面会把更多的插件集成进来,从而丰富我们的数据构造。测试数据中心的用户分普通用户和管理员,在权限管理里面进行设置,数据统计功能后面会详细介绍。
在对产品有一个大概了解后,那它是怎么灵活支持数据准备的?
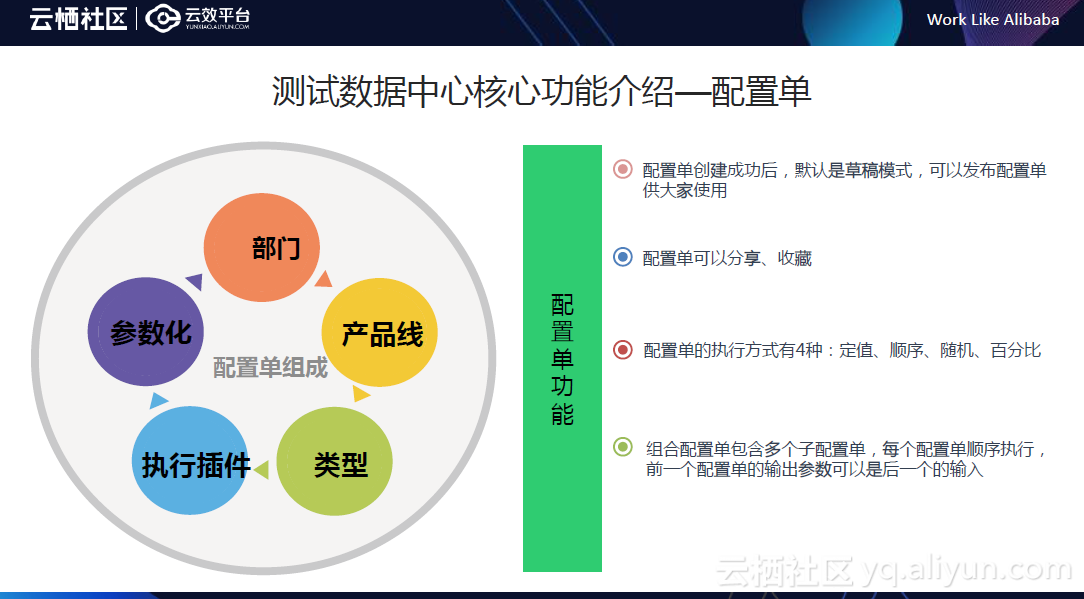
首先我介绍一下配置单的组成:由部门、产品线、配置单类型、执行插件和参数化配置5个部分组成。由于不同部门、产品线之间,所需要的测试数据不太一样,从而对配置单进行区分,配置单类型分为单配置单和组合配置单,执行插件前面介绍过了,参数化配置后面会详细介绍。
当配置单创建成功后,默认是草稿模式,创建者可能需要一定时间的调试,成功以后,可以把配置单发布出来,供用户使用;分享的功能是为了帮助用户快速精准的定位到自己想要的配置单。
在配置单的执行过程中,我们支持4种方式执行,定值、顺序、随机、百分比执行,这些执行的前提条件是配置单的执行次数为多次,以及你选择的参数是个参数列表形式。
定值执行:是你选择了什么参数,就按照你选择的参数值执行。
顺序执行:是执行的时候按照参数列表的顺序依次执行。比如,你的参数列表有4组参数,你执行5次,那么它会依次执行里面的每一组参数,第一组参数会执行两遍,这样方便用户遍历执行。
随机执行:是参数的选择执行是随机的,可以理解为一种随机测试。
百分比执行:是可以对每一组参数进行百分比的权重设置,按权重执行。
最后,我们的配置单支持组合方式,可以关联其他子配置单,然后对子配置单进行编排,编排的原则是前一个子配合单的输出参数,可以作为后一个配置单的输入参数使用,这种方式适用于一些比较复杂的数据构造流程。比如,需要先通过sql造数据,然后通过http,接着在缓存redis里面造数据,然后再通过http查询等,或者是多个http接口的数据构造,前一个接口的输出作为后一个接口的输入参数,组合场景多种多样,可以涵盖绝大部分的数据构造场景了。
参数管理在测试数据中心也是一个比较重要的功能,主要是为了方便用户在构造配置单的时候,进行参数化操作,而不是参数固定写死的那种,这样做的优势在于用户可以少写配置单,把参数抽象出来,在执行前进行替换。
目前我们参数支持的形式有3类:数据源参数、组合参数、一般参数。
数据源参数的使用方式,是在选择配置单插件容器的时候,可以进行数据源的选择,我们支持的数据源有mysql、oracle、sql server、MongoDB、redis、DDS、tddl等,方便数据源选择和维护,而且为了数据安全,我们对数据源密码进行了加密处理。
组合参数的使用场景更加广泛,几乎可以适用于任一场景,设计理念在于用户可以自定义参数,同时支持参数的批量拷贝功能,方便参数的添加和修改。目前用户使用最多的场景是他们有多套环境,可以根据组合参数自由选择参数执行,大大提升了配置单的复用性和维护性。
一般参数,主要是键值对的方式保存,他的使用场景是对同一个key进行顺序执行,比如我的传入参数名为项目id,我需要批量创造一批数据,那么我就可以用一般参数来帮我构造。
测试数据中心的核心功能介绍的差不多了,平台有了,那么平台上用户的使用情况如何呢?接下来介绍一下数据统计功能。
数据统计我们分执行总次数、配置单数、用户数、产品线数,4个维度进行统计。数据都是实时性的,可以按最近1个月、3个月、6个月、1年及全部数据进行查询。每天的执行次数在页面上一目了然。总执行次数多少,成功和失败多少,每天发布的配置单数有多少,以及每天使用平台的用户,UV和PV是多少。通过分析这些数据知道运行情况,同时对每个页面进行打点,以及客户回访,方便我们对产品功能的优化,持续改进。
接下来,通过执行总次数、成功率高的配置单,以及用户执行成功率3个维度,对top10的配置单和用户进行排名,排名是为了激励大家更好的使用配置单,提升配置单的成功率,从而提高我们创建配置单的能力。
比如,第一个小图展示的是执行总数排名前10的配置单,可以看出哪些配置单是经常被使用到的,他的使用频率及成功率等信息;第二个小图是按照执行成功率排名前10的配置单展示的,说明那些人创建的配置单是质量比较高的;第三个小图是执行成功率排名前10 的用户,说明这些用户对数据执行成功率是有追求的。(截图来自测试数据中心功能,数据已处理。)
通过这些维度的统计,是为了让用户更好的使用测试数据中心,以及通过数据的显示,让用户对使用过程做到心中有数。
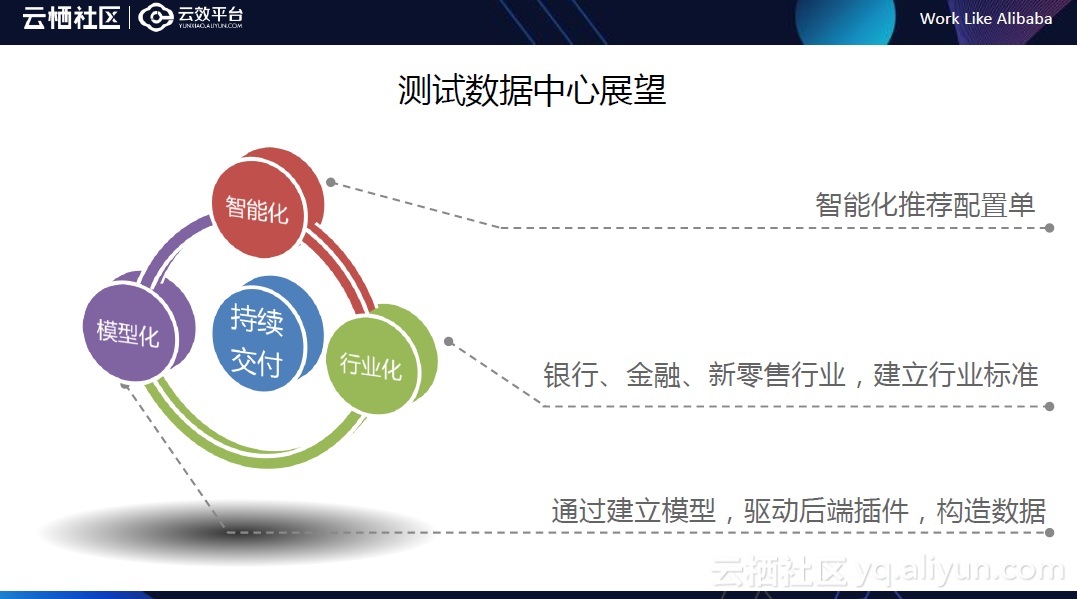
展望
1.数据智能化:既然我们是构造数据的,通过对数据的分析,以及用户的喜好,智能推荐用户想要的配置单。
2.行业化:目前测试数据中心也已经开始对外售卖,但是银行、金融、新零售等行业,他们的数据准备过程比较复杂,比如银行借记IC卡的预制作流程,第一页面录制预制卡申请,第二调用ssh跑批命令,第三自动化录制核心制卡任务预处理/跑批,第四手工操作制卡工具制卡,第五预制卡中心预制卡/待发卡入库,第六柜员领用凭证,第七身份核实,第八实时发个人卡主卡,第九存款,一共九个步骤,这是他们正常的一个数据准备过程,流程长,中间还需要线下处理,错误率会很高,这种行业化带来的技术壁垒需要我们尝试突破,建立相对标准的规范。
3.模型化:通过数据模型来消除业务上面的差异,然后转变成我们的插件,提供数据构造。
直播回顾:点我查看
直播PPT下载:关注云效微信公众号(ali_yunxiao),对话框回复直播资料或者点击附件下载。
Work Like Alibaba更多直播:
11月03日15:00:玩转《阿里巴巴开发手册》 P3C插件(直播回顾)
11月09日20:00:智能运维——百万级服务器自动化运维怎么玩?(点击报名)